


Fast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph
Timely paper out of three labs

Today’s paper: Fast Think-on-Graph: Wider, Deeper and Faster Reasoning of Large Language Model on Knowledge Graph. Liang et al. 24 Jan 2025. https://arxiv.org/pdf/2501.14300
In an age of LLMs, Retrieval Augmented Generation is a cutting-edge technique for LLMs to generate accurate, reasonable, and explainable responses. The early RAG, known as naive RAG, mostly works by indexing the documents into manageable chunks, retrieving relevant context based on vector similarity to a user query, integrating the context into prompts, and generating the response via LLMs. If this sounds very technical, the best way to remember it is: to help the LLM answer better answers (and not hallucinate), enrich its context with ‘retrieved’ facts to help it do a better job in its generation. As the paradigm is simple and highly efficient for the basic tasks, naive RAG is widely adopted in various applications, including dialogue and recommender systems.
However, naive RAG is not without its problems. First, there can be low precision as ambiguity or bias exist in the embedding model. Another problem might be low recall when dealing with complex queries, and third, there can be lack of explainability as the queries and documents are embedded in high-dimensional vector spaces.
To address some of these challenges, while still keeping the benefits of RAG, graph-based RAG (GRAG) has emerged as a novel set of techniques within the RAG paradigm. GRAG is widely considered an advanced RAG by incorporating KGs as an external source for LLMs. Employing various graph algorithms within a graph database, GRAG empowers LLMs for complex operations such as graph querying, path exploration, and even community detection.
GRAG is categorized into n-w GRAG and n-d GRAG (Fig. 1 below) based on the breadth and depth of retrieval. Particularly, there are still quite a few 1-w 1-d Graph RAG researches. Similar to the “Retrieve one Read One” paradigm of naive RAG, most of the 1-w 1-d research focuses on single entity or one-hop relationship queries, thereby inheriting the shortcomings of naive RAG.
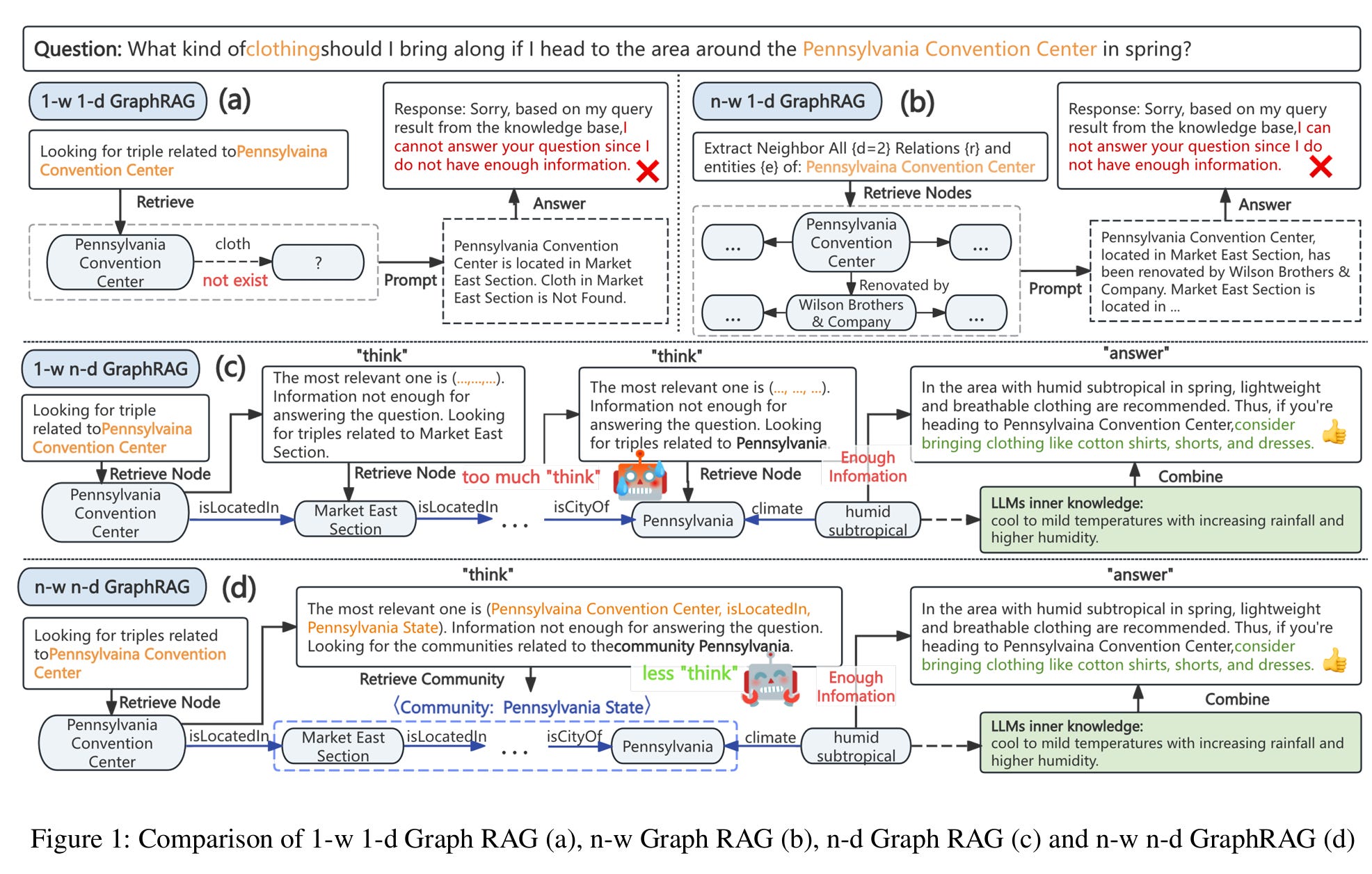
Building on the consideration of n-w or n-d methods, today’s authors propose a n-d n-w Graph RAG paradigm: Fast Think on-Graph (FastToG). The key idea of FastToG is to guide the LLMs to think “community by community”. As illustrated in Fig. 1, though the path between Pennsylvania Convention Center and humid subtropical may be lengthy, it notably shortens when nodes are grouped. Accordingly, FastToG regards communities as the steps in the chain of thought, enabling LLMs to “think” wider, deeper, and faster.
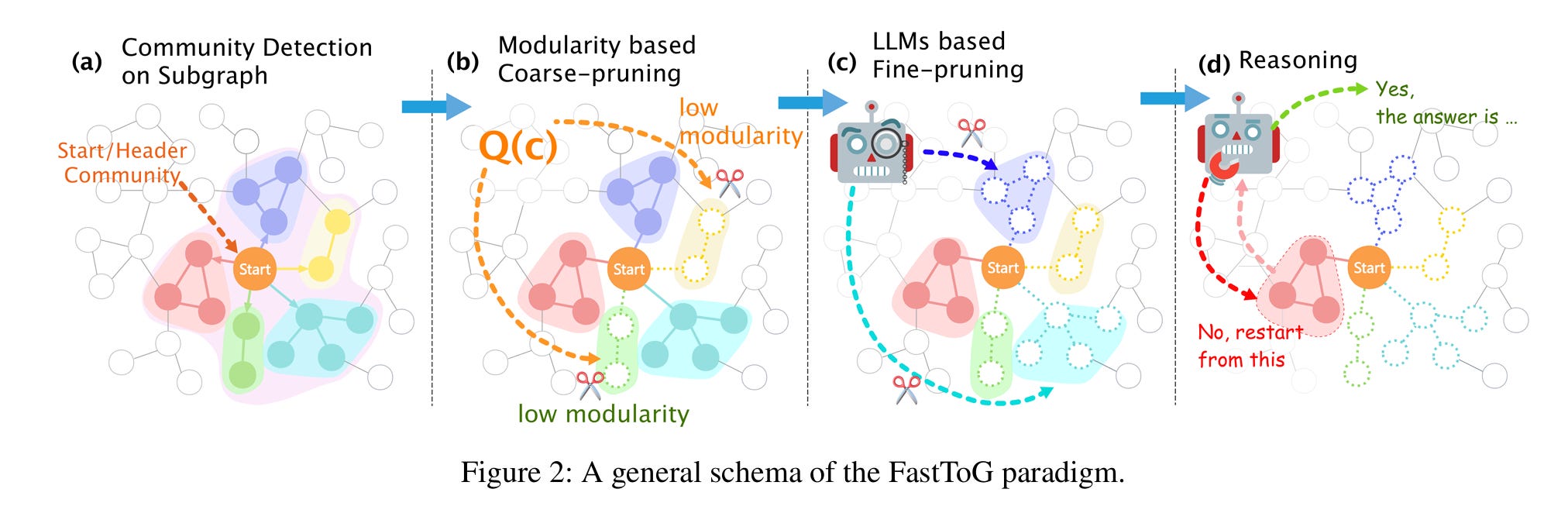
The FastToG framework operates in two primary stages: the initial phase and the reasoning phase. During the initial phase, the goal is to identify the starting communities and the main community for each reasoning chain (as shown in Figure 2a above). FastToG guides language models to extract the subject entities of a query as a single-node starting community. Following this, FastToG uses a method called Local Community Search (LCS), which includes two main steps: detecting relevant communities within a subgraph (Figure 2b) and refining these communities (Figure 2c). This process identifies neighboring communities most likely to contribute to solving the query and establishes the main community for each reasoning chain.
After identifying the head communities, the algorithm transitions to the reasoning phase. For each reasoning chain, FastToG continues to use Local Community Search (LCS) for detecting and refining local communities. The selected community is added to the reasoning chain as the newest element in a process referred to as pruning. Once all reasoning chains are updated, methods such as Graph2Text (G2T) or Triple2Text (T2T) are applied to convert the communities within the chains into textual formats. These texts serve as input for the language models in the reasoning process (Figure 2d). If the reasoning chains are deemed sufficient by the language models to generate an answer, the algorithm concludes and provides the answer. To avoid excessive processing time, if no answer is generated after a maximum number of iterations, the algorithm switches to a fallback approach, relying on the language models' internal knowledge, such as IO, Chain of Thought (CoT), or CoT-SC methods, to answer the query.
Details behind both phases are fleshed out formally and mathematically in the paper, but the key points are surprisingly readable, and the figure really tells you everything you need to know about the method. I cite this as a strength of the paper.
Let’s jump to how well the method does experimentally. It was evaluated on 6 real-world datasets and to ensure compatibility with prior work, exact match (hits@1) was used as the evaluation metric. Considering the computational cost and time consumption, the authors randomly sampled 1k examples from the datasets containing more than a thousand data.
Two LLMs (gpt-4o-mini1 and Llama-3-70b-instruct) are used without quantization. For the graph2text model , the authors use T5-base using dataset WebNLG and synthetic data generated by GPT-4. To build the synthetic data, they prompt GPT-4 to generate text descriptions of given communities, which are the byproduct of the experiments. For the knowledge graph, they utilize Wikidata , which is a free and structured knowledge base, as source of KGs. The version of Wikidata is 20240101 and only the triples in English are considered. Following extraction, 84.6 million entities and 303.6 million relationships are stored in Neo4j.
Let’s begin by looking at accuracy in the two tables below:

Overall, FastToG, which includes t2t and g2t mode, outperforms all previous methods. In particular, it surpasses n-d 1-w (ToG) by 4.4% in Tab. 1 and 5.9% in Tab. 2. The evaluation of the two community-to-text conversion methods shows that Graph2Text (G2T) generally achieves higher accuracy across most datasets, aligning with the conceptual framework proposed in the earlier section. However, the improvement in G2T's performance is minimal (typically less than 1%) and, on the QALD dataset, it slightly underperforms compared to Triple2Text (T2T). To investigate these unexpected results, extensive checks were conducted (details available in the repository), which revealed that the primary reason for G2T's underperformance is hallucination issues stemming from its base model.
Efficiency is a key focus of this work, evaluated using the number of calls to the LLMs as the primary metric. The number of calls per question is estimated as 2WD + D + 2 for reasoning. Since all settings for the n-d methods share the same W, the evaluation focuses on D as a measure of efficiency, with efficiency roughly proportional to D. Methods such as IO, CoT, CoT-SC, and 1-d are excluded from this analysis because their D value is fixed at 1. Figure 3 below illustrates the relationship between the maximum size of a community and the average depth of reasoning chains on the CWQ and WebQSP datasets, where a MaxSize of 1 corresponds to earlier n-d1-w methods, like ToG. The results show that FastToG (with MaxSize > 1) outperforms these n-d1-w methods. Even with communities of MaxSize = 2, there is a notable reduction in the average depth of reasoning chains. For instance, on CWQ, the average depth decreases by approximately 0.2 and 0.4 for T2T and G2T modes, respectively. On WebQSP, these reductions are even greater, reaching about 1.0 for both modes. However, as MaxSize increases further, the reductions in depth become less pronounced.

Finally, Figures 4 and 5 go into some ablation study analysis. Fig. 4 illustrates the relationship between the MaxSize and accuracy. Overall, most of the cases achieve higher accuracy when MaxSize is set to 4. However, at MaxSize = 8, results show a decrease in accuracy. Therefore, setting a larger size of the community does not necessarily result in higher gain from accuracy. Fig. 5 depicts the accuracy comparison between modularity-based coarse pruning and random pruning on the CWQ and WebQSP datasets for 2 modes, with all cases using MaxSize = 4. Overall, modularity-based coarse pruning outperforms random pruning in all cases. In other words, the specific components that are used in FastToG (unsurprisingly) can affect overall performance significantly.
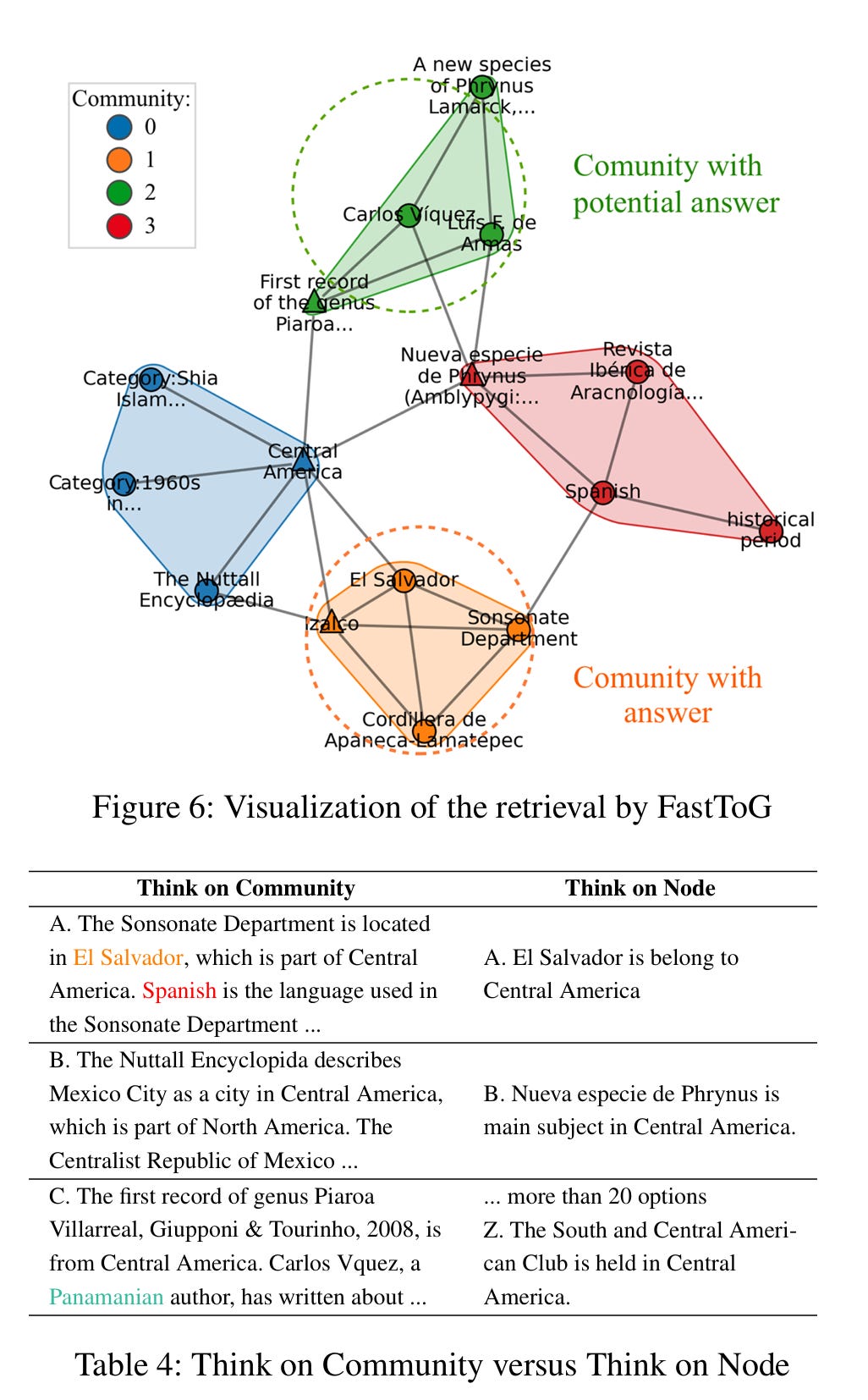
While results are useful for scientific discourse, a case study always helps to tell the story. The authors consider the query “Of the 7 countries in Central America, which consider Spanish an official language?” from dataset CWQ, and visualize the retrieval process of FastToG. Fig. 6 displays a snapshot of LLMs pruning with start community Central America. Note that the node Central America has 267 one hop neighbors, making it hard to visualize. Tab. 4 shows the corresponding Graph2Text output of the communities or nodes. The left column shows part of the pruning with communities as the units to be selected, while the right column shows the nodes. The case study demonstrates that community as the basic unit for pruning can increase the likelihood of solving this problem. For example, comparing two options A, the community associated with the option A in left column has a path connecting to the entity Spanish. Thus, it seems that EI Salvador is one of the answers. In contrast, when using node as the unit, it requires more exploration to reach this entity.
In closing, today’s musing covered a novel GraphRAG paradigm- FastToG. By allowing large models to think “community by community” on the knowledge graphs, FastToG not only improves the accuracy of answers generated by LLMs but also enhances the efficiency of the RAG system. The authors also identified areas for further improvement, such as incorporating semantics and syntax with community detection, introducing multi-level hierarchical communities to enhance retrieval efficiency, and developing better community-to-text conversion. Overall, a very promising addition to the LLM literature.