
Let papers flow...
Why are we so antagonistic to AI reviewing and authoring? Is it just about quality?

Follow us also on LinkedIn, X, Instagram, YouTube, Discord, and TikTok
Today’s preprint: Let Papers Flow: AI Conferences ShouldEmbrace Submission Explosion via Autonomous Review Pipelines. He et al. April 2026.
The most important idea in AI research right now is not a new model but a new institution. Today’s preprint makes a bold, but increasingly mainstream, claim: the coming flood of AI-generated and AI-accelerated research should not be treated as a crisis to suppress, but as a structural shift to design for. I think the authors are directionally right. If AI is dramatically lowering the cost of searching literature, writing code, running experiments, and drafting papers, then it is also destabilizing the human bottlenecks that sit downstream - and especially, peer review.
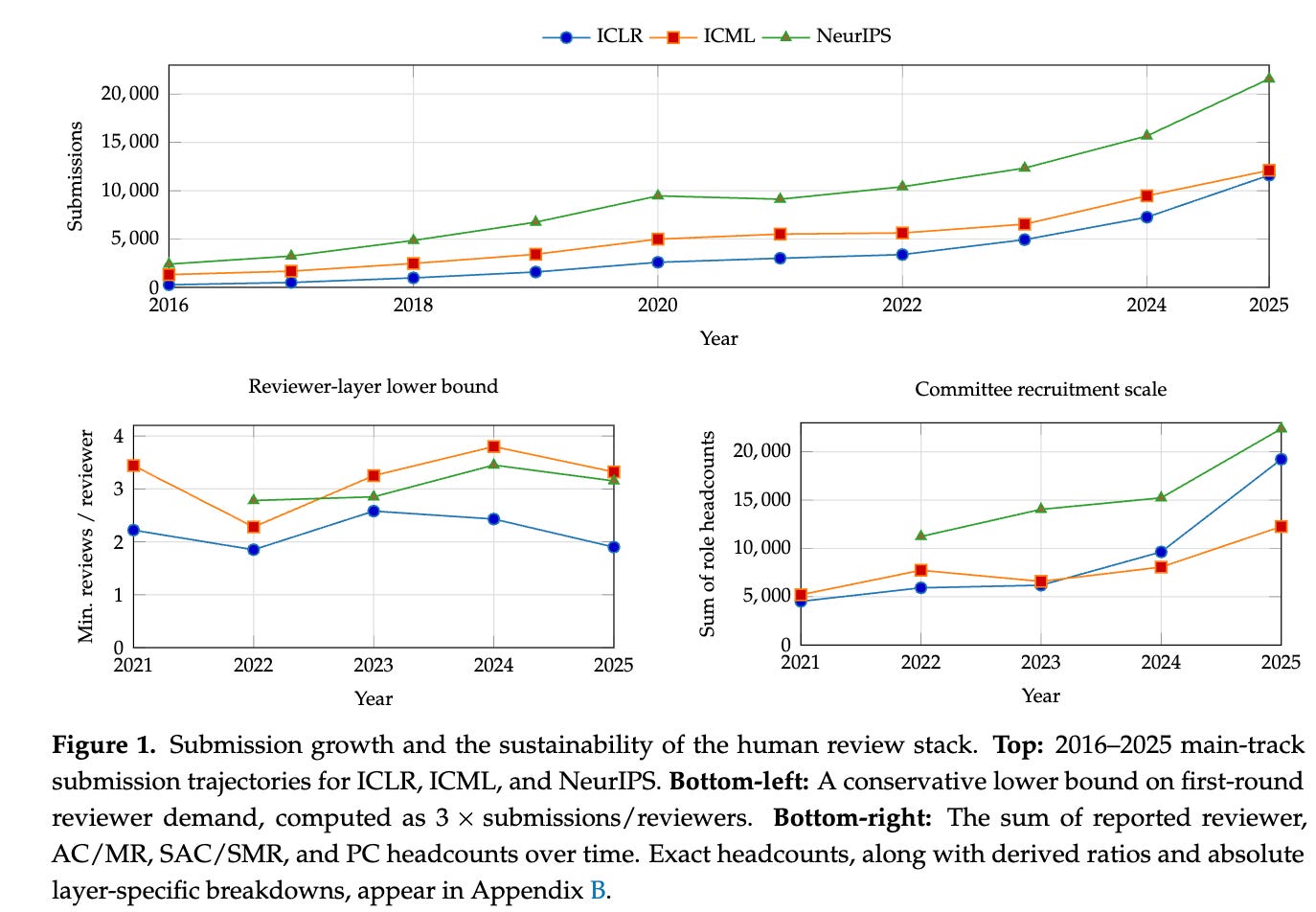
This is already visible in the numbers. Major AI conferences are operating at absurd scale, with tens of thousands of submissions, reviewers, area chairs, and senior committee members (Figure 1 below). The scarce resource is no longer PDF production. What we need is trusted human attention. And once you see the system through that lens, the idea of a machine-first, human-governed review pipeline starts to feel less radical and more inevitable.
What I like about the paper is that it does not argue for a sovereign AI judge. It argues for an autonomous review pipeline as a control plane: a system that can do first-pass evidence construction, artifact checks, literature positioning, policy screening, and routing, while escalating ambiguous or high-stakes cases to humans. That distinction matters because the right role for AI in science is not to replace legitimacy, but to increase the amount of rigor we can apply before scarce human expertise is engaged.
This is exactly why I’m bullish on AI review as a category. Done well, it can raise the floor on scientific process. Every paper can get a baseline pass on reproducibility, missing baselines, disclosure requirements, and internal consistency. Every reviewer can begin with a richer dossier. Every venue can make its escalation criteria more explicit. In a world of accelerated research, that is not a nice-to-have. It is infrastructure.
At GRAIL, this is very close to how we think about the future of science. We’re building autonomous science products for what we call exponential science: an AI reviewer that tells three top-shelf models to review a manuscript in deep thinking mode, an OpenClaw-based platform for end-to-end scientific experimentation called ApexClaw, and an agentic LaTeX editor for scientific writing. We believe the opportunity is not just to accelerate isolated tasks, but to build a full pipeline where hypothesis generation, experimentation, review, and communication become more tightly integrated.
But the most important question is not whether AI can generate more science. It is whether we can trust the science it helps generate. And that also is where I believe the optimism has to become more disciplined. If an AI system writes code, proposes analyses, reviews a manuscript, or edits the final paper, what exactly are we trusting? Are we trusting the model’s output? The process that produced it? The audit trail behind it? The reproducibility of the underlying artifacts? For scientific AI systems, trust cannot be a vibe. We need to think carefully about the engineering challenges here, and we need to get it right the first time around before we overhaul the time honored human peer-review process that’s been in place for over a century.

To me, the answer is that trust comes both from systematic verification and human role clarity. AI should be used to make claims more legible, experiments more reproducible, and review more systematic. Humans should remain responsible for judgment, exception handling, appeals, and epistemic accountability. In other words: AI can scale evidence, but humans must still own legitimacy. The human role becomes more valuable, not less, when it is concentrated on the decisions that actually matter.
This is why I think the best AI review systems will not look like magic black boxes that output accept/reject recommendations but like other scientific instruments. They will surface missing controls, flag uncertainty, run code, compare claims to prior work, and generate reports that others can inspect and contest. Trustworthy AI for science will not be built by asking people to suspend disbelief, but by making the workflow auditable.
The broader implication is exciting. If we get this right, we can move from a world where science is bottlenecked by seasonal review queues to one where technical certification is increasingly continuous and curation becomes a separate layer. That could mean faster feedback loops, better error correction, broader publication of replications and negative results, and a healthier scientific record overall. For both scientists and investors, that should matter enormously: better infrastructure for truth production compounds. Or done wrong, it could lead to a lot of shoddy science. We could also see a social schism - well-funded Bay Area researchers start producing science that departs in significant ways from today’s practice. That could be good, and it might help us take bigger risks - which I argue is sorely needed in modern science. But let’s not throw out the baby with the bathwater.
So yes, I’m bullish on the vision in this preprint. But I’d sharpen the thesis this way: the future of AI in science will not be won by systems that merely produce more papers, more code, or more reviews. It will be won by systems that make machine-generated science trustworthy enough for humans to rely on. That is the frontier I am advocating for, and it is why I think good, unbiased autonomous review is not just a tool category but one of modern AI’s primitives for today’s exponentially expanding science.