
Musing 101: PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
A high-utility paper on a universal problem out of three Chinese labs

Today’s paper: PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides. Zheng et al. 7 Jan. 2025. https://arxiv.org/pdf/2501.03936
Which of us who has to do presentations for (at least part of) our living hasn’t been impressed by ChatGPT but then thought, if only it could also give me a powerpoint presentation to start with? Yes, there are ‘apps’ on OpenAI that could give you some content to paste into your slides (see right of Figure 1 below), but creating a set of slides that have content, design and coherence, using relatively automated methods, doesn’t seem to have caught on in the mainstream. One reason is that ChatGPT cannot give us pptx’s directly, although there is no doubt in my mind that the technology to tweak it to do so is relatively trivial (after all, it can generate far more complex things, including videos and even audio). So I was very excited to cover today’s paper (left of Figure 1), which has taken a genuine stab at the powerpoint generation problem, and has even made their methods and code publicly available. Let’s get started.

To create good presentations, the authors derive inspiration from human workflow. They observe that humans, rather than create a presentation in a single pass, typically tend to select exemplary slides as references and then summarize and transfer key content onto them. Figure 2 below shows the workflow of PPTAgent, which is inspired by this two-pass approach. In the first stage, given a document and a reference presentation, PPTAgent analyzes the reference presentations to extract semantic information, providing the textual description that identifies the purpose and data model of each slide. In the Presentation Generation stage,PPTAgent generates a detailed presentation outline and assigns specific document sections and reference slides to each slide.

Another important contribution is to evaluate the quality of generated presentations, which we’ll come to in a bit. First, let’s go into more details on PPTAgent itself. In Stage 1, called Presentation Analysis, PPTAgent first clusters slides in the reference presentation and extract their content schemas. This structured semantic representation helps LLMs determine which slides to edit and what content to convey in each slide. Think of the reference presentation almost like a training dataset. This stage involves both slide clustering (e.g. separating structural slides like opening slides from slides that convey specific content, like bullet-point slides) and schema extraction, content schemas are extracted from the clusters. Both of these are visually illustrated in Figure 2 above. Technical details are not as complex as they may initially appear (covered in the appendices of the paper), and rely to a great extent on LLM prompting. The clustering example is very simple; based on a greedy approach that can be found pretty much all over practical computing implementations.
Now let’s go to Stage 2 (Presentation Generation). Here, I think human inspiration shines i.e., how we create slides in real life. As shown in Figure 2 above, the first step is outline generation. Many of us design our most complex presentations in this way: here, an LLM is instructed to create an outline, which is a list of entries: each entry specifies a reference slide, relevant document section indices, as well as the title and description of the new slide. Next, guided by the outline, the slide generation process iteratively edits a reference slide to produce the new slide. To enable precise manipulation of slide elements, the authors implement five specialized APIs that allow LLMs to edit, remove, and duplicate text elements, as well as edit and remove visual elements. Another trick they use is to convert slides from their raw XML format (this is the underlying representation that software like PowerPoint use to ‘create’ the presentation we see, similar to how HTML code turns into the webpages we see by browsers) into an HTML representation, which is more interpretable for LLMs (see below).

For each slide, LLMs receive two types of input: text retrieved from the source document based on section indices, and captions of available images. The new slide content is then generated following the guidance of the content schema. Subsequently, LLMs leverage the generated content, HTML representation of the reference slide, and API documentation to produce executable editing actions. The authors also use a self-correction mechanism to improve the robustness of the generation process.
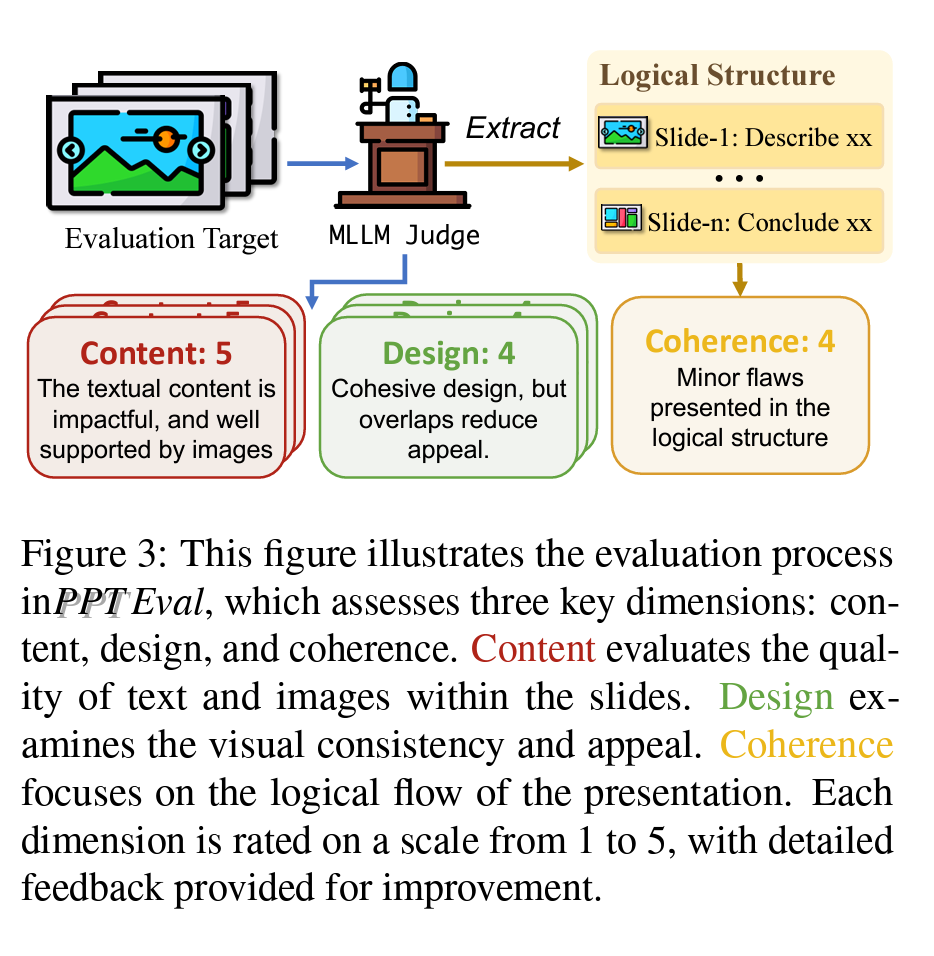
Now that a presentation has been generated comes another difficult problem: how do we evaluate it? Even for human-generated presentations, this is not trivial. There are presentations that wow, and others that are really bad, but there’s also a big middle. Of course, subjectivity is also an important component of it. Here though, the authors are aiming for something practical and they introduce PPTEval, which they describe as a a comprehensive framework for assessing presentation quality from multiple perspectives. The framework provides scores on a 1-to-5 scale and offers detailed feedback to guide the improvement of future presentation generation methods. The overall evaluation process is depicted in Figure 3 below.
What are some of the limitations of traditional methods? A big one is that most such methods are too focused on evaluating only the content, rather than the design and coherence, of the slides. Metrics in the NLP community, such as perplexity and ROUGE fail to capture essential aspects of presentation quality such as narrative flow, visual design, and content impact. They are designed more for problems like summarization and machine translation, which (while related to this problem) are quite different. Moreover, ROUGE-based evaluation tends to reward excessive textual alignment with input documents, undermining the brevity and clarity crucial for effective presentations.
PPTEval uses a multi-modal LLM (MLLM) as a judge instead. It prompts the MLLM to rate the slides along three large criteria:
Content: The content dimension evaluates the information presented on the slides, focusing on both text and images. The authors assess content quality from three perspectives: the amount of information, the clarity and quality of textual content, and the support provided by visual content.
Design: Good design not only captures attention but also enhances content delivery. The authors evaluate the design dimension based on three aspects: color schemes, visual elements, and overall design.
Coherence: The authors evaluate coherence based on the logical structure and the contextual information provided. Effective coherence is achieved when the model constructs a captivating storyline, enriched with contextual information that enables the audience to follow the content seamlessly.
Another contribution of the paper is to collect an actual dataset of presentations (and corresponding documents which the presentations were meant to describe) from Zenodo, a repository service that most academics are familiar with. It hosts diverse artifacts from different domains. The authors have curated 10,448 presentations from this source and made them publicly available to support further research. They sampled 50 presentations across five domains to serve as reference presentations. Additionally, they collected 50 documents from the same domains to be used as input documents. The small number of references above shows that PPTAgent is relatively few-shot.
Results for PPTAgent are reported using three state-of-the-art models: GPT-4o-2024-08-06 (GPT4o), Qwen2.5-72B-Instruct (Qwen2.5), and Qwen2-VL-72B-Instruct (Qwen2-VL).

Looking at Table 2 above, we find that PPTAgent improves LLMs’ presentation generation capabilities significantly, compared only to vanilla use of a model like GPT-4o. There is almost a 50% improvement on the Design metric, which is understandable: a presentation that only contains text would not score high on this metric.
In closing the musing, I think this paper is a great example of how prompt engineering, judiciously composed into a pipeline, can be used to do tasks that otherwise seem ill-designed for text-only or even multi-modal LLMs. The appendices in the paper are well worth a read: they provide most of the technical details necessary for any engineer with a weekend to spare to implement some of this and see how it works for them (although the authors also promise in their GitHub repo that code and data for PPTAgent are ‘coming soon’).
However, while the method demonstrates some capability to produce high-quality presentations, there remain challenges that affect its universal applicability. Parsing slides with intricate nested group shapes often proves to be a bottleneck, leading to less consistent results. Additionally, although PPTAgent shows noticeable improvements in layout optimization over prior approaches, it still falls short of exploiting the full potential of visual cues for refining stylistic consistency. This manifests in design flaws, such as overlapping elements, undermining the visual harmony of the generated slides. All of this means there’s plenty of scope for future work.