
Musing 102: Agent Laboratory: Using LLM Agents as Research Assistants
Very exciting paper out of AMD and Johns Hopkins University

Today’s paper: Agent Laboratory: Using LLM Agents as Research Assistants. Schmidgall et al. 8 Jan. 2025. https://arxiv.org/abs/2501.04227
Scientists frequently face constraints that limit the number of research ideas they can explore at any given time, resulting in ideas being prioritized based on predicted impact. While this process helps determine which concepts are worth investing time in and how best to allocate limited resources effectively, many high quality ideas remain unexplored. If the process of exploring ideas had less limitations, researchers would be able to investigate multiple concepts simultaneously, increasing the likelihood of scientific discovery.
Today’s paper takes this challenge head on by introducing Agent Laboratory, an autonomous pipeline for accelerating the individual’s ability to perform machine learning research. Unlike previous approaches, where agents participate in their own research ideation independent of human input, Agent Laboratory is designed to assist human scientists in executing their own research ideas using language agents. As shown below, it takes as input a human research idea and outputs a research report and code repository produced by autonomous language agents, allowing various levels of human involvement, where feedback can be provided at a frequency based on user preference.

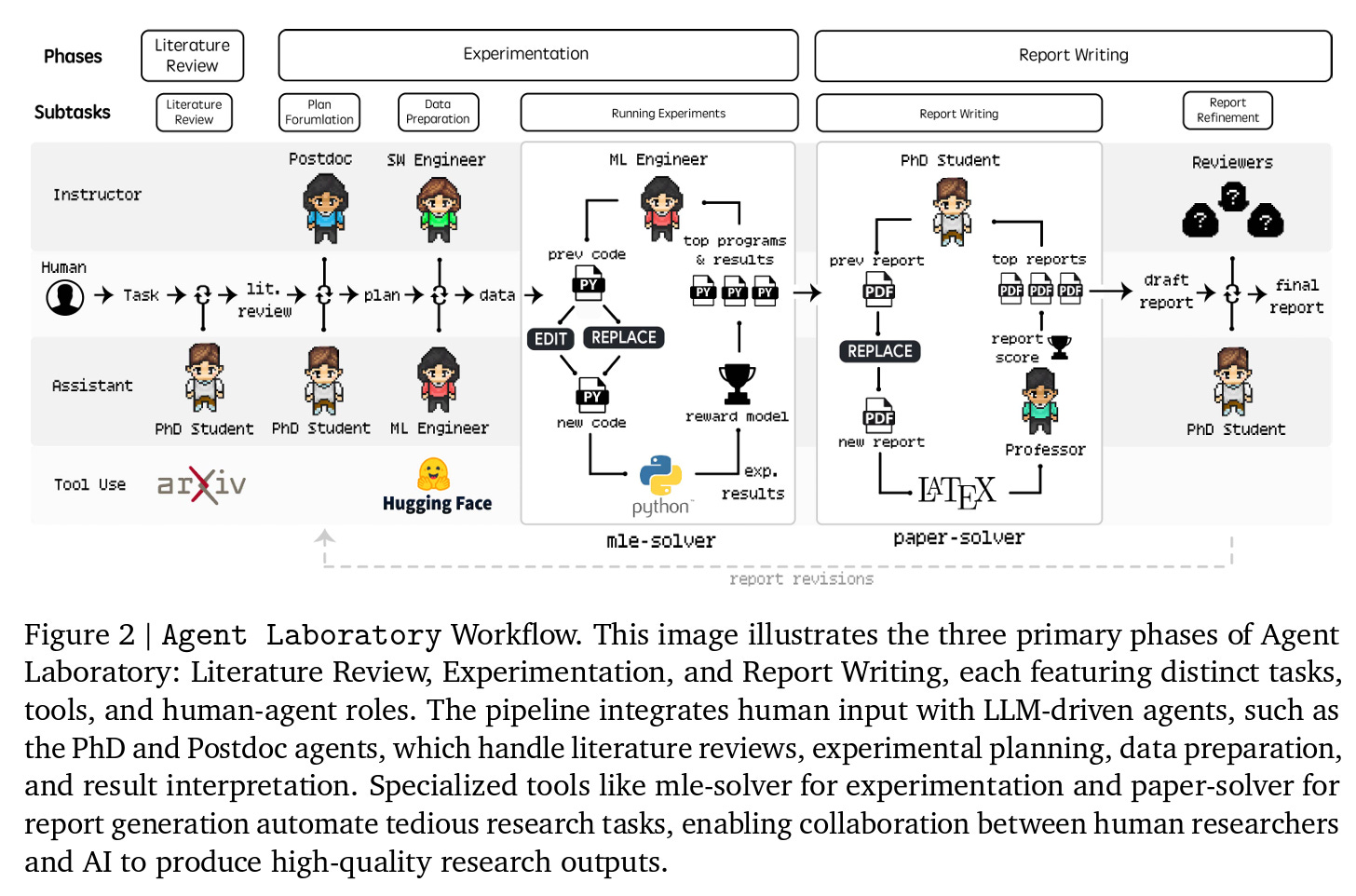
Agent Laboratory begins with the independent collection and analysis of relevant research papers, progresses through collaborative planning and data preparation, and results in automated experimentation and comprehensive report generation. As shown in Figure 2 below, the overall workflow consists of three primary phases: (1) Literature Review, (2) Experimentation, and (3) Report Writing.
Literature Review: The literature review phase involves gathering and curating relevant research papers for the given research idea to provide references for subsequent stages. During this process, the PhD agent utilizes the arXiv API to retrieve related papers and performs three main actions: summary, full text, andadd paper. Thesummaryaction retrieves abstracts of the top 20 papers relevant to the initial query produced by the agent. The full text action extracts the complete content of specific papers, and the add paper action incorporates selected summaries or full texts into the curated review. This process is iterative rather than a single-step operation, as the agent performs multiple queries, evaluates the relevance of each paper based on its content, and refines the selection to build a comprehensive review. Once the specified number of relevant texts (N=max) is reached via the add paper command, the curated review is finalized for use in subsequent phases.
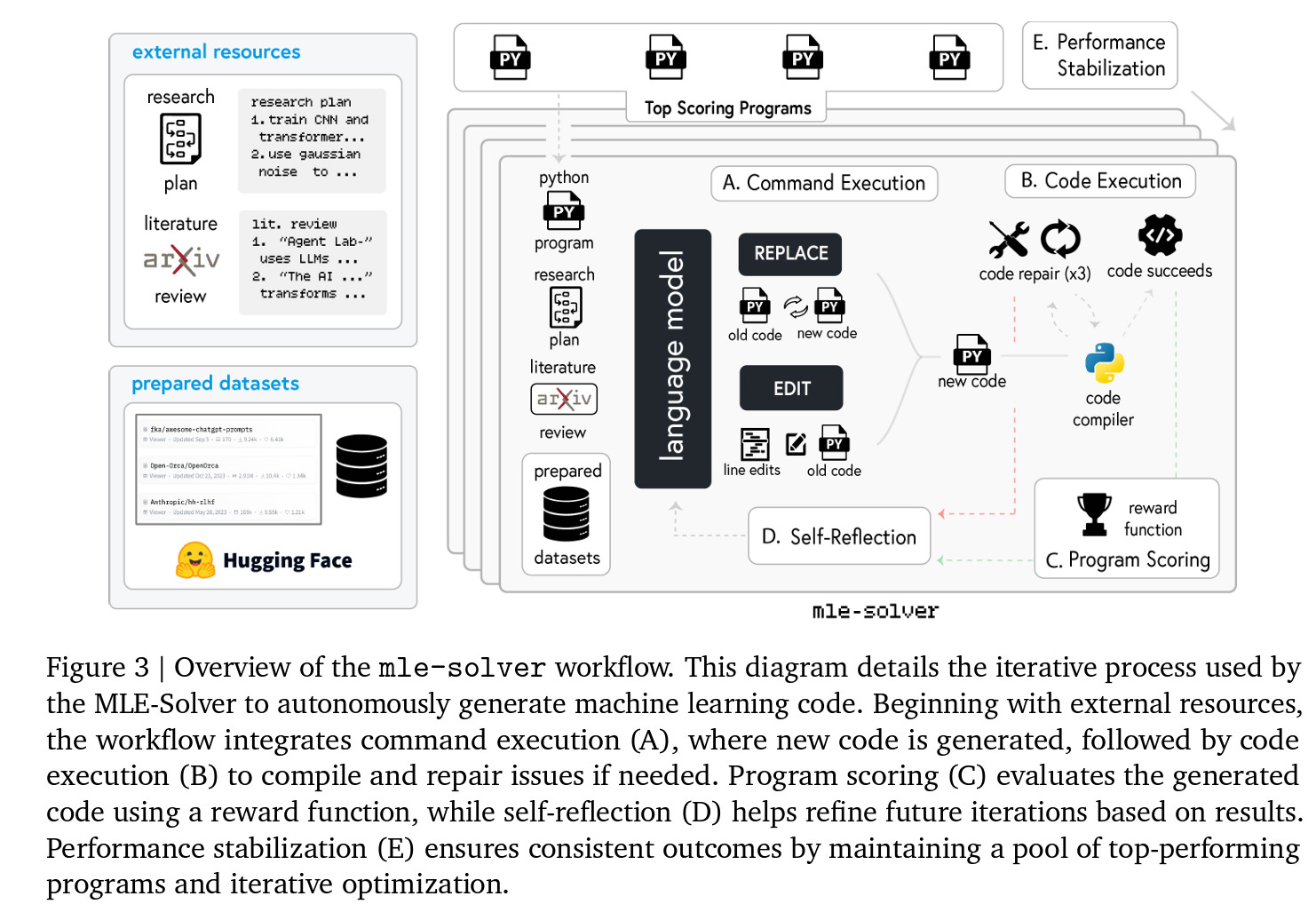
Experimentation: This is the most involved step of the process, and is shown in the figure below as well. Several steps are involved, including plan formulation, data preparation, and running experiments. The plan formulation phase focuses on creating a detailed, actionable research plan based on the literature review and research goal. During this phase, the PhD and Postdoc agents collaborate through dialogue to specify how to achieve the research objective, detailing experimental components needed to complete the specified research idea such as which machine learning models to implement, which datasets to use, and the high-level steps of the experiment. The goal of the data preparation phase is to write code that prepares data for running experiments, using the instructions from the plan formulation stage as a guideline. The ML Engineer agent executes code using Python command command and observes any printed output. The MLEngineer has access to HuggingFace datasets, searchable via the search HF command. After agreeing on the finalized data preparation code, the SW Engineer agent submits it using the submit code command. In the running experiments phase, the ML Engineer agent focuses on implementing and executing the experimental plan formulated prior. This is facilitated by mle-solver (Figure 3 below), a specialized module designed to generate, test, and refine machine learning code autonomously.
Report Writing: In the report writing phase, the PhD and Professor agent synthesize the research f indings into a comprehensive academic report. This process is facilitated by a specialized module called paper-solver, which iteratively generates and refines the report. The paper-solver aims to act as a report generator, positioning the work that has been produced by previous stages of Agent Laboratory. paper-solver does not aim to entirely replace the academic paper-writing process, but rather to summarize the research that has been produced in a human-readable format so that the researcher using Agent Laboratory understands what has been accomplished.
Let’s jump to experiments. The authors begin by asking how human evaluators perceive papers generated by Agent Laboratory running in end-to-end autonomous mode across five topics. Next, they examine human evaluation when using Agent Laboratory in collaborative co-pilot mode from both allowing the researcher to choose any topic they want and from a set of preselected topics. They then provide a detailed runtime analysis including cost, average time, and success rate by various models. Finally, they conclude with an evaluation of the mle-solver in isolation on MLE-Bench, a set of real-world Kaggle challenges.
The first experiment aims to evaluate how human-evaluated quality varies across three axes: experiment quality, report quality, and usefulness. This evaluation was conducted by human participants using three different LLM backends: gpt-4o, o1-mini, and o1-preview. Research questions were selected from a set of 5 templates, and are shown in the first column of the table below:

The results of this evaluation indicate variability in performance across different Agent Laboratory LLM backends. gpt-4o consistently achieved lower scores, with an average experimental quality rating of 2.6/5, a report quality rating of 3.0/5, and a usefulness rating of 4.0/5. In contrast, o1-mini generally outperformed gpt-4o in experimental quality, with an average score of 3.2/5 (+0.6), while maintaining similar levels of report quality and usefulness at 3.2/5 (+0.2) and 4.3/5 (+0.3), respectively. o1-preview demonstrated the highest usefulness and report quality, averaging 4.4/5 (+0.4 from gpt-4o and +0.1 from o1-mini) and 3.4/5 (+0.4 from gpt-4o and +0.2 from o1-mini) respectively, though its experimental ratings were slightly lower than o1-mini at 2.9/5 (+0.3 from gpt-4o and-0.3 from o1-mini). While all backends perform comparably in terms of report and experimental quality, the o1-preview model was as the most useful for research assistance, suggesting that its outputs were better aligned with the expectations and needs of researchers.
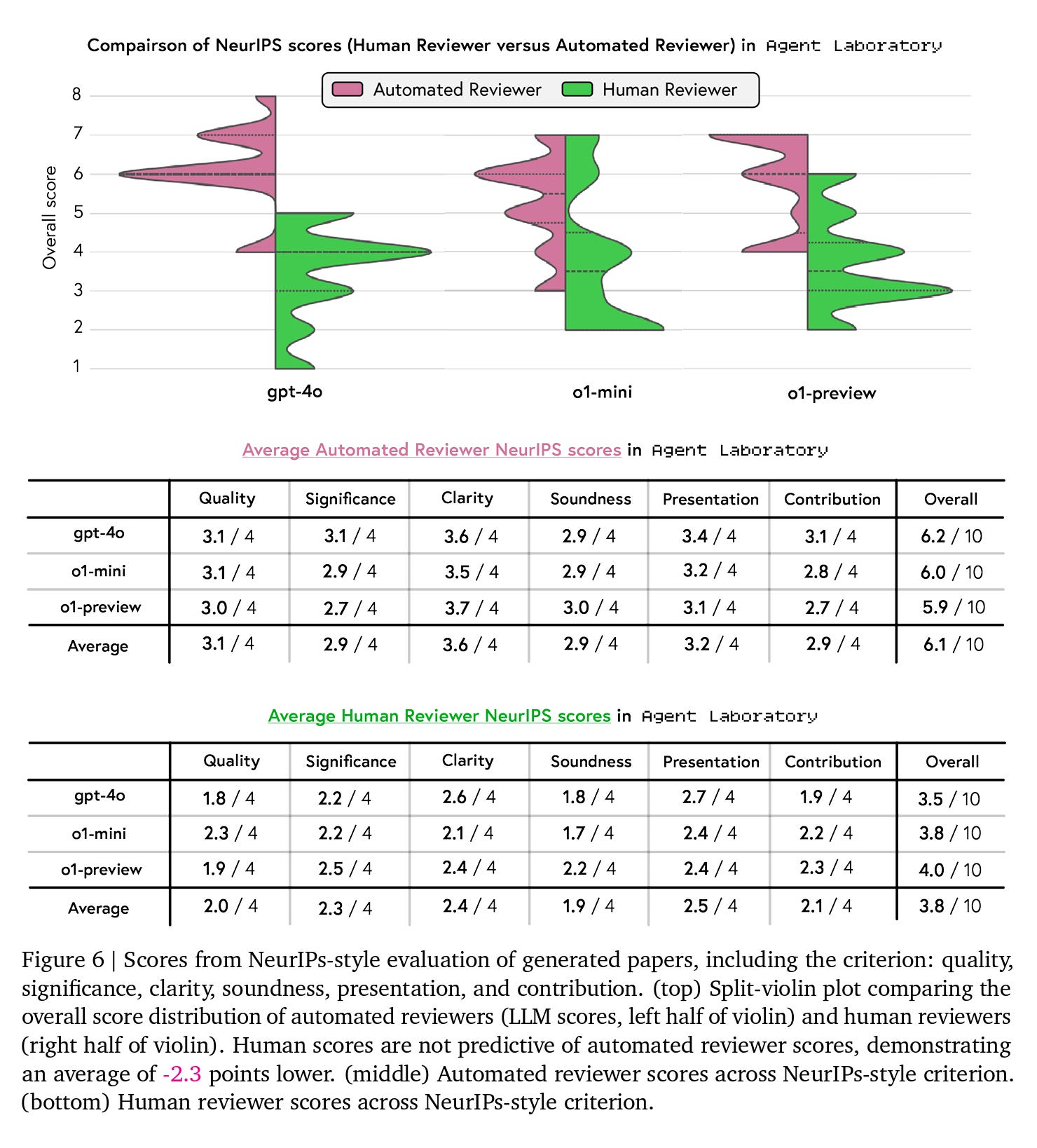
Another interesting experiment the authors conducted was to ask human reviewers to assess papers generated by Agent Laboratory according to NeurIPS-style criteria, including quality, significance, clarity, soundness, presentation, and contribution as shown in Figure 6 below. They evaluated the same papers analyzed in the experiment earlier using the aforementioned metrics and conducted the comparison. They found that the average human scores for the three backends revealed differences in performance, with average overall ratings ranging from 3.5/10 with gpt-4o, 3.8/10 with o1-mini, and 4.0/10 with o1-preview.
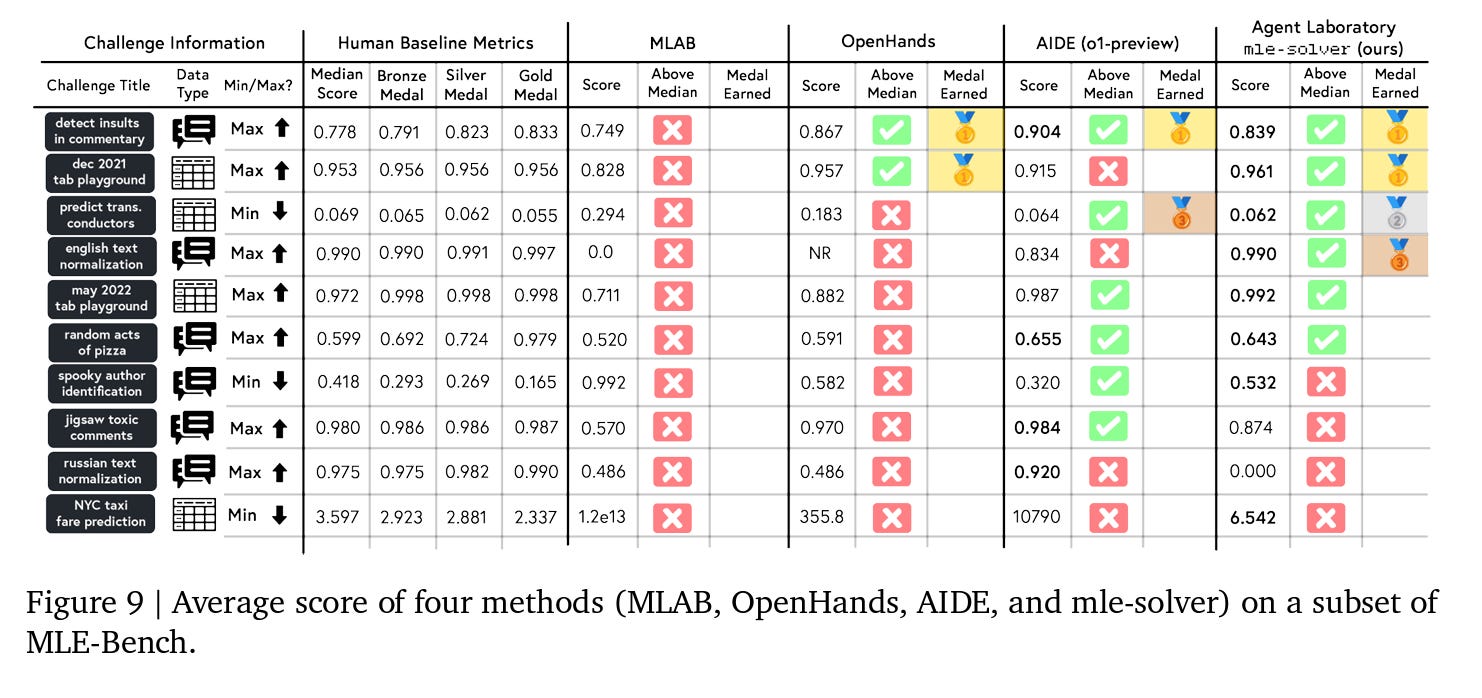
The authors do a bunch of other experiments, but I’ll end with an interesting one. Evaluating the entire Agent Laboratory workflow does not contain much information about the ability of mle-solver specifically to solve individual ML problems. In order to evaluate mle-solver more objectively, the authors use a subset of 10 ML challenges from MLE-Bench. MLEBench is a benchmark designed to assess the capability of agents in handling real-world ML tasks on Kaggle competitions. This benchmark compares agent performances with human baselines, scoring agents with Kaggle’s medal system, and incorporating mechanisms to mitigate contamination and plagiarism risks. The authors include all challenges focusing on text and tabular data from the low complexity category of MLE-Bench. We provide as input to mle-solver the following: Kaggle dataset description, distilled knowledge from Kaggle notebooks, as well as an accessible train and dev set.
A detailed overview of results is shown below. The authors compare average scores across several runs from three other methods: MLAB with gpt-4o backend, OpenHands with gpt-4o backend, and AIDE with o1-preview backend. While mle-solver submitted valid solutions for all MLE-Bench challenges within two hours, prior methods often failed to submit, complicating scoring. The authors thus calculated average scores by excluding invalid submissions from other works and averaging valid ones. They find that Agent Laboratory’s mle-solver is more consistently high scoring than other solvers, with mle-solver obtaining four medals (two gold, one silver, and one bronze) compared with OpenHands (gpt-4o) obtaining two medals (two gold), AIDE (o1-preview) obtaining two medals (one gold, one bronze) and MLAB obtaining zero medals. Additionally, mle-solver obtained above median human performance on six out of ten benchmarks, with AIDE obtaining five out of ten, OpenHands two out of ten, and MLAB zero out of ten.
Closing this musing, the question that we have to ask is: will this ‘automate’ reviewers? Not really, a theoretical reason being that good ideas still seem to be coming from humans, and the AI is really executing and implementing the idea. But that in itself could be automated eventually (presumably). The more practical reason is that putting together an end-to-end paper at sufficiently high quality is still difficult; just ask students, who use GenAI a lot, but still have to put in many hours to have work that is original and gets published in the best journals or conferences.
The paper also has some limitations. One is self-evaluation: the paper-solver is being evaluated for quality by using LLMs emulated NeurIPS reviewers. This has two limitations: (1) while the reviewing agents were shown to have high alignment with real reviewers, qualitatively research reports from Agent Laboratory are less satisfying than research papers from The AI Scientist, with the former having lower quality figures, despite Agent Laboratory papers obtaining higher scores overall. (2) The research reports produced by Agent Laboratory are not meant to replace the paper writing process done by humans as it was in The AI Scientist, rather it is meant to provide a report for the human to understand what has been accomplished, so that they can scale up the experiment and write their own research report.
There are also some limitations that present themselves due to the structure enforced in the workflow. For example, paper-solver is encouraged to a organize the paper into a relatively fixed structure (abstract, introduction, etc), which disallows unique paper organizations and section orders. Another limitation is that mle-solver and paper-solver are limited to generating only two figures for the paper. However, these limitations are all addressable with relatively minor tweaks and add-ins.
Ultimately, as a co-pilot for scientists, this is an incredibly useful framework, and it’s well documented and open-source. We need to give it a try to see how well it actually works in the wild west of experiments. The results are very promising.