


Musing 116: WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents
Multi-national paper out of China, Australia and US

Today’s paper: WALL-E 2.0: World Alignment by NeuroSymbolic Learning improves World Model-based LLM Agents. Zhou et al. 22 Apr. 2025. https://arxiv.org/pdf/2504.15785
The authors waste no time in today’s paper to ask the question(s) that they then pursue through the remainder of the paper: Can we build accurate world models out of large language models (LLMs)? How can world models benefit LLM agents? Let’s get started with what we mean by world models. A world model refers to a structured internal representation that enables a large language model (LLM) agent to understand, predict, and interact with its environment effectively. Such environments tend to be open-world and can be domain-specific: games, VR/AR systems, medical care, education, autonomous driving.

A primary reason for the failures that are currently observed is the gap between the prior knowledge driven commonsense reasoning by LLMs and the specified environment’s dynamics. The gap leads to incorrect predictions of future states, hallucinations, or violation of basic laws in LLM agents’ decision-making process. The authors claim that the world alignment of an LLM can significantly improve the LLM performance as a promising world model, which enables us to build more powerful embodied LLM agents in partially observable settings. Instead of fine-tuning the LLM, they introduce a training-free pipeline World Alignment by NeuroSymbolic Learning (WALL-E 2.0) to learn symbolic knowledge that is environment-specific and complementary to the LLM’s prior knowledge, by analyzing explored trajectories and predicted ones as shown in the figure below. An example of WALL-E in action is shown above.

In the figure, the agent determines actions to take via MPC (the now-famous model-predictive control agentic AI protocol), which optimizes future steps’ actions by interacting with a neurosymbolic world model. The world model adopts an LLM whose predictions are aligned with environment dynamics through code rules converted from symbolic knowledge (action rules, knowledge/scene graph) learned via inductive reasoning from real trajectories and predicted trajectories.
WALL-E 2.0 significantly builds upon WALL-E 1.0, which the authors had proposed just last year by enriching the agent’s understanding of action preconditions and effects through inductive learning of a knowledge graph, doing dynamic scene graph extraction, and most importantly, through neurosymbolic world model integration.
Concerning the last point, the neurosymbolic learning in WALL-E 2.0 takes 4 stages: (1) comparing predicted and actual trajectories; (2) learning new symbolic knowledge from real trajectories; (4) translating symbolic knowledge to code; and (4) Code rule set pruning via solving a maximum coverage problem:

Several pages are dedicated to the mathematical formulation and specific algorithms for the four stages, but for practical purposes, let’s jump to experiments. The authors use the following two benchmark test environments:
Mars serves as an interactive environment created to assess how well models can perform situated inductive reasoning, which involves generating and applying new rules within unfamiliar settings. Mars introduces changes to terrain, survival mechanics, and task structures to produce a wide range of environments. Agents operating in Mars are required to engage with these dynamic worlds and adjust to novel rules, rather than depending on prior knowledge such as the assumption that “eating cows restores health.” As a result, Mars provides a distinctive platform for evaluating an agent’s flexibility and reasoning capabilities in evolving contexts.
ALFWorld is a virtual simulation where agents complete tasks by interacting with a household setting, presented in either a visual or text-based format. In text-based tasks, agents receive ground-truth environmental information directly through input text. In contrast, visual tasks require agents to extract meaning from raw visual data, without receiving explicit information. To succeed, agents must use perceptual tools to interpret the scene. ALFWorld includes six task categories, each demanding the execution of complex goals—for instance, placing a cooled lettuce on a kitchen counter—thus testing both planning and understanding within simulated domestic environments.
As shown in Tables 1 and 2 below, WALL-E 2.0 consistently outperforms baselines across diverse environments. In Mars, WALL-E 2.0 achieves reward improvements of 16.1% to 51.6% and boosts task scores by at least 61.7%. While DreamerV3 reaches higher absolute rewards, it is trained for 1 million environment steps—far exceeding WALL-E 2.0 ’s budget of just 5,600 steps (0.56% of DreamerV3’s budget).
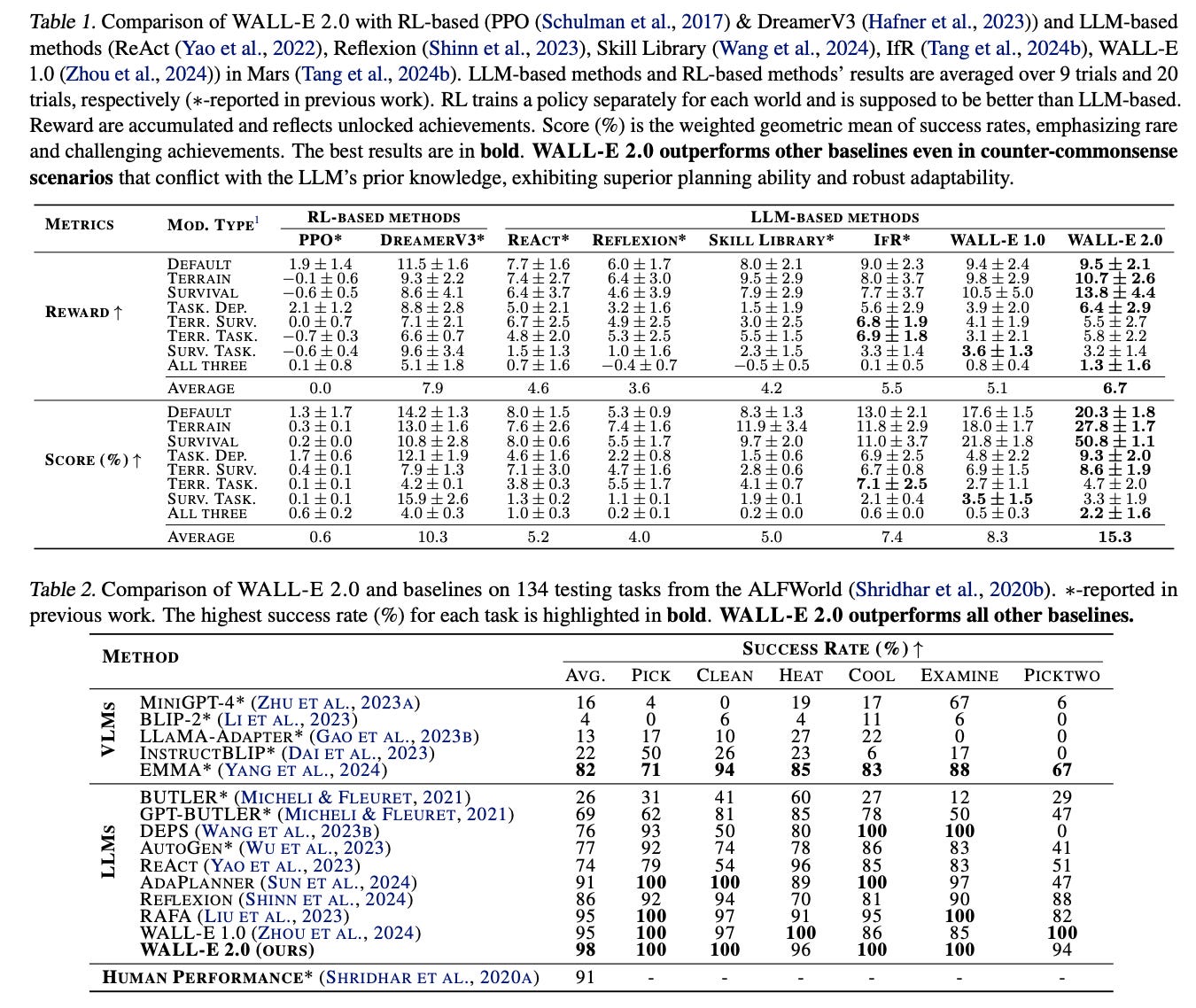
Table 1 also shows that when the environment’s mechanics conflict with the LLM’s prior knowledge, the agent’s performance drops substantially, ranging from 3.3% to 97.1%, compared to the default setting. Nevertheless, the authors’ method can learn symbolic knowledge through inductive reasoning to align its world model with the current environment. This alignment leads to more accurate predictions, feedback, and suggestions during planning, thereby significantly boosting the agent’s performance. In these counter-commonsense scenarios, WALL-E 2.0 achieves a reward increase of at least 21.8% and a score increase of at least 51.6% compared to other methods.
Figure 5 below further shows that WALL-E 2.0 surpasses the current state of the art in every aspect. As the number of iterations increases, WALL-E 2.0 ’s reward rises from 3.6 to 6.7, while its score improves from 4% to 15.3%, exceeding IfR (the current state of the art) by 17.9% and 51.6%, respectively. Several factors account for this performance gap. First, although IfR employs inductive reasoning to learn the environment’s mechanisms, it relies solely on rules. In contrast, the neurosymbolic learning approach in WALL-E acquires action rules, knowledge graphs, and scene graphs, providing a more comprehensive understanding of the environment and allowing the agent to align more effectively. Additionally, IfR’s rules are expressed in natural language and can only be applied through prompt-based learning, which introduces randomness—particularly when the model’s prior knowledge conflicts with the rules. WALL-E, however, utilizes code rules, forcing the LLM to adhere to them strictly and thereby reducing variability. This design choice significantly enhances overall performance, according to the authors. They also do an ablation study, but I’ll skip the details here.

In closing the musing, the authors have demonstrated that LLMs can serve as good world models for agents when aligned with environment dynamics via neurosymbolic knowledge learning. Their neurosymbolic approach uses code-based, gradient-free integrations of action rules, knowledge graphs, and scene graphs, closing the gap between the LLMs’ prior knowledge and specific environments. By using a model-based framework, their agent WALL-E 2.0 achieves substantial improvements in planning and task completion. In open-world environments such as Mars and ALFWorld, it outperforms baselines by 16.1%–51.6% on success rate metrics and achieves a new record 98% success rate in ALFWorld after only four iterations. These results suggest that additional symbolic knowledge is critical for aligning LLM predictions with environment dynamics, leading to high-performing model-based agents in complex settings.
My one criticism is that I am not completely sure that WALL-E 2.0 should be called an ‘agent’. I don’t believe the authors emphasized the terminology as strongly for WALL-E 1.0. But that being said, it is not clear in general what is, or is not, an agent. Semantics aside, the paper offers a new advancement in the growing space of world models + alignment + LLMs.