



Today’s paper: Voxtral. Liu et al. 17 July 2025. https://arxiv.org/pdf/2507.13264
It’s always fun when one of the important ‘new’ AI giants like OpenAI, Anthropic or Mistral (in this case) drop new models and decide to also put them out on arxiv for our perusal. In a nutshell, that’s what today’s post is about. The model, as the title makes clear, is called Voxtral.
Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. The authors also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Voxtral contains an audio encoder to process speech inputs, an adapter layer to downsample audio embeddings, and a language decoder to reason and generate text outputs. The overall architecture is depicted in Figure 1 below.
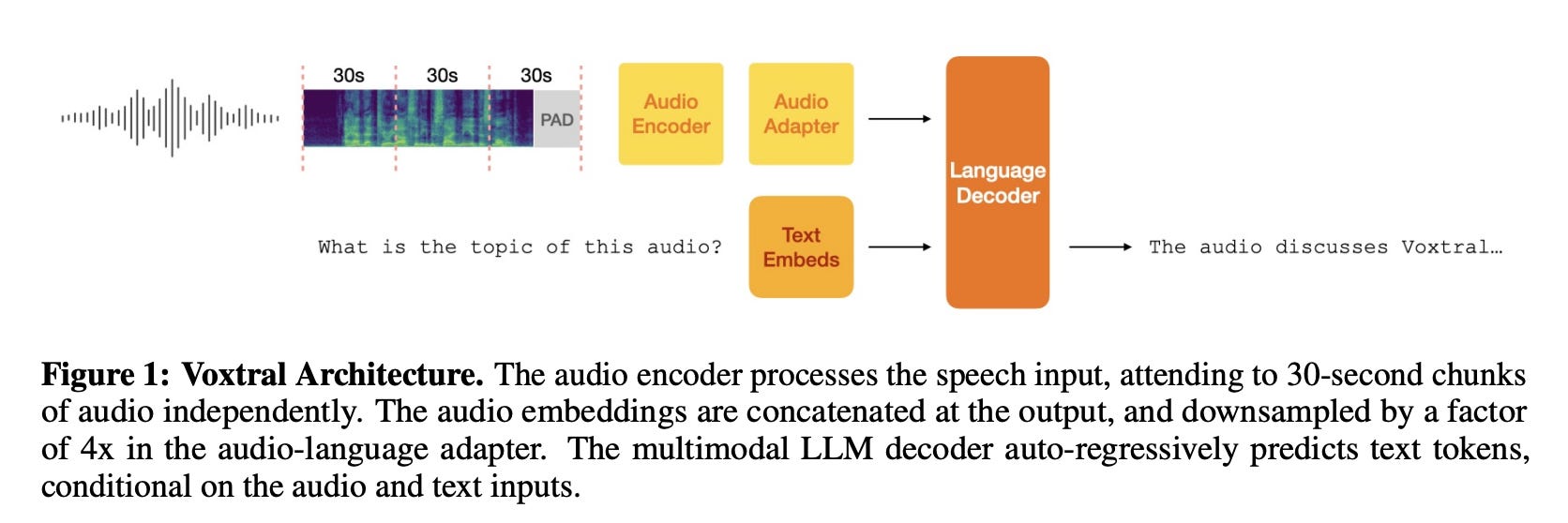
Two variants of Voxtral are released: Mini and Small. Voxtral Mini is built on top of Ministral 3B, an edge-focused model that delivers competitive performance with a small memory footprint. Voxtral Small leverages the Mistral Small 3.1 24B backbone, giving strong performance across a range of knowledge and reasoning tasks. Table 1 below decomposes the number of parameters in each checkpoint based on the sub-components.

The model is developed in three phases: pretraining, supervised finetuning, and preference alignment. In the first pretraining phase, the model is introduced to audio by training on paired audio and text data. This is done using two strategies: one mimics transcription by having the model listen to a segment of speech and repeat it in text, while the other encourages deeper understanding by pairing an audio segment with the next text segment, as if in a dialogue or story. To guide the model, special tokens indicate which pattern to follow. This dual-pattern training helps the model develop both transcription skills and context-aware reasoning across modalities. Figure 2 below describes both patterns.

In the second phase, the model is finetuned using more structured and diverse instruction-style tasks. Most of this data is synthetic—generated using a large language model given transcripts of long audio clips. These include question–answer pairs, summaries, and translations, crafted to simulate real-world user interactions. Additionally, the model is trained to understand and respond to spoken prompts directly, including those in various accents and languages, with a special “transcribe mode” for speech recognition tasks.
In the final phase, the model is taught to prefer higher-quality answers using an approach called Direct Preference Optimization (DPO). For a given prompt, the model generates two candidate responses, which are ranked using a reward model. This model sees only the audio transcript—not the raw audio—but is still able to evaluate the factuality, tone, and helpfulness of the responses. The main model is then updated to favor outputs that align with these rankings, resulting in more helpful and human-aligned behavior.
Let’s jump to experiments. To evaluate Voxtral’s capabilities, the authors conduct a comprehensive set of experiments spanning speech recognition, speech translation, speech understanding, and traditional text-only tasks. These evaluations compare Voxtral Mini and Small against both open and closed-source models, including Whisper large-v3, GPT-4o mini, and Gemini 2.5 Flash. In addition to using established benchmarks, the authors also introduce new evaluation datasets, particularly for speech-based question answering and long-context understanding, filling important gaps in current benchmark coverage. This well-rounded experimental design allows them to assess not just transcription accuracy, but also reasoning, multilingual capabilities, and the model's effectiveness in multimodal scenarios.
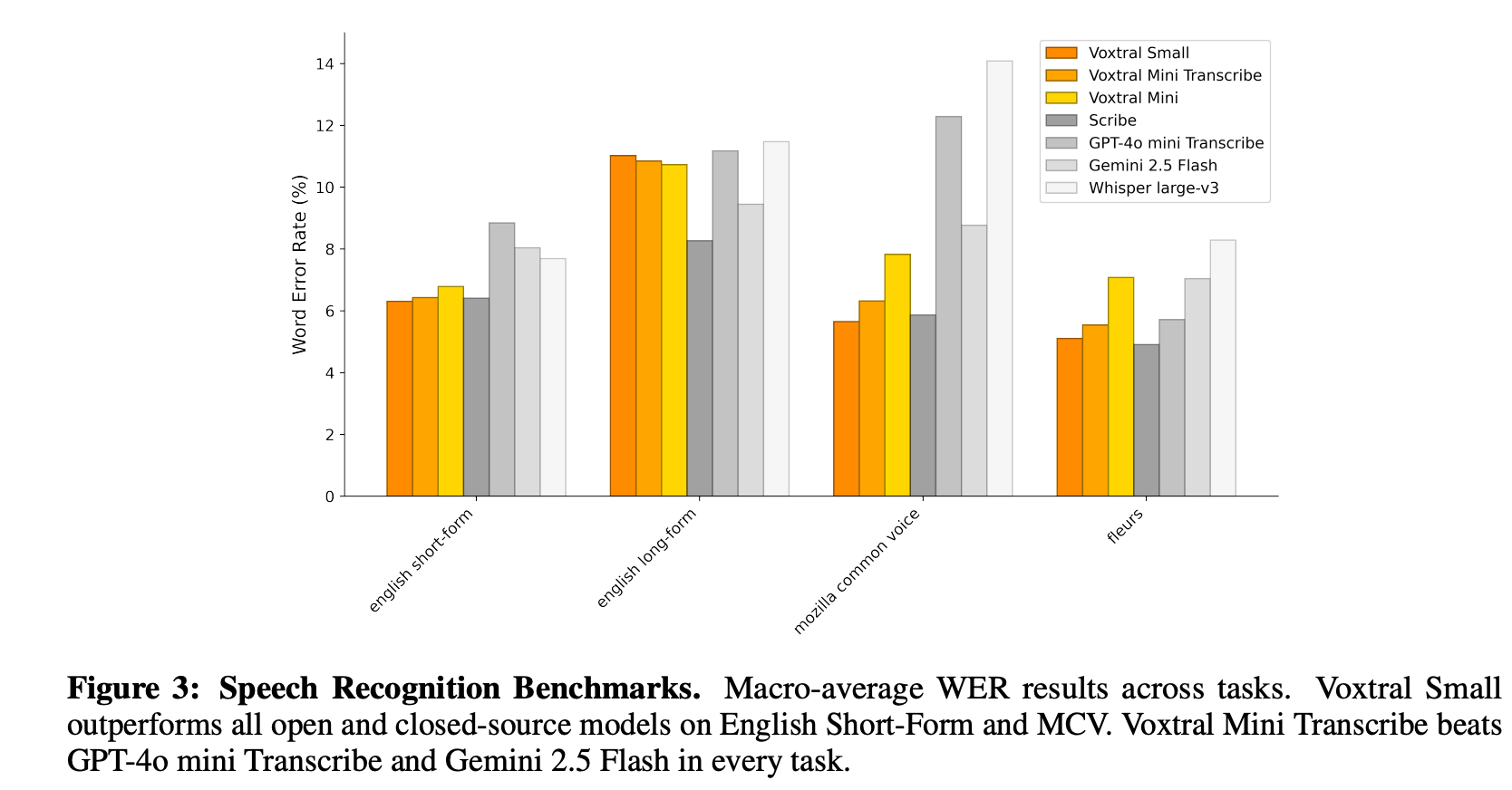
Figure 3 presents a comparison of word error rates (WER) across four prominent speech recognition benchmarks: English Short-Form, English Long-Form, Mozilla Common Voice (MCV), and FLEURS. Voxtral Small achieves state-of-the-art performance on both English Short-Form and MCV, outperforming even strong closed-source competitors like GPT-4o mini and Gemini 2.5 Flash. Remarkably, Voxtral Mini Transcribe (a smaller model trained only on transcription objectives) still beats those larger models across every task shown. These results highlight the effectiveness of Voxtral’s pretraining and architecture choices, especially for high-quality speech recognition in both open-domain and multilingual settings.
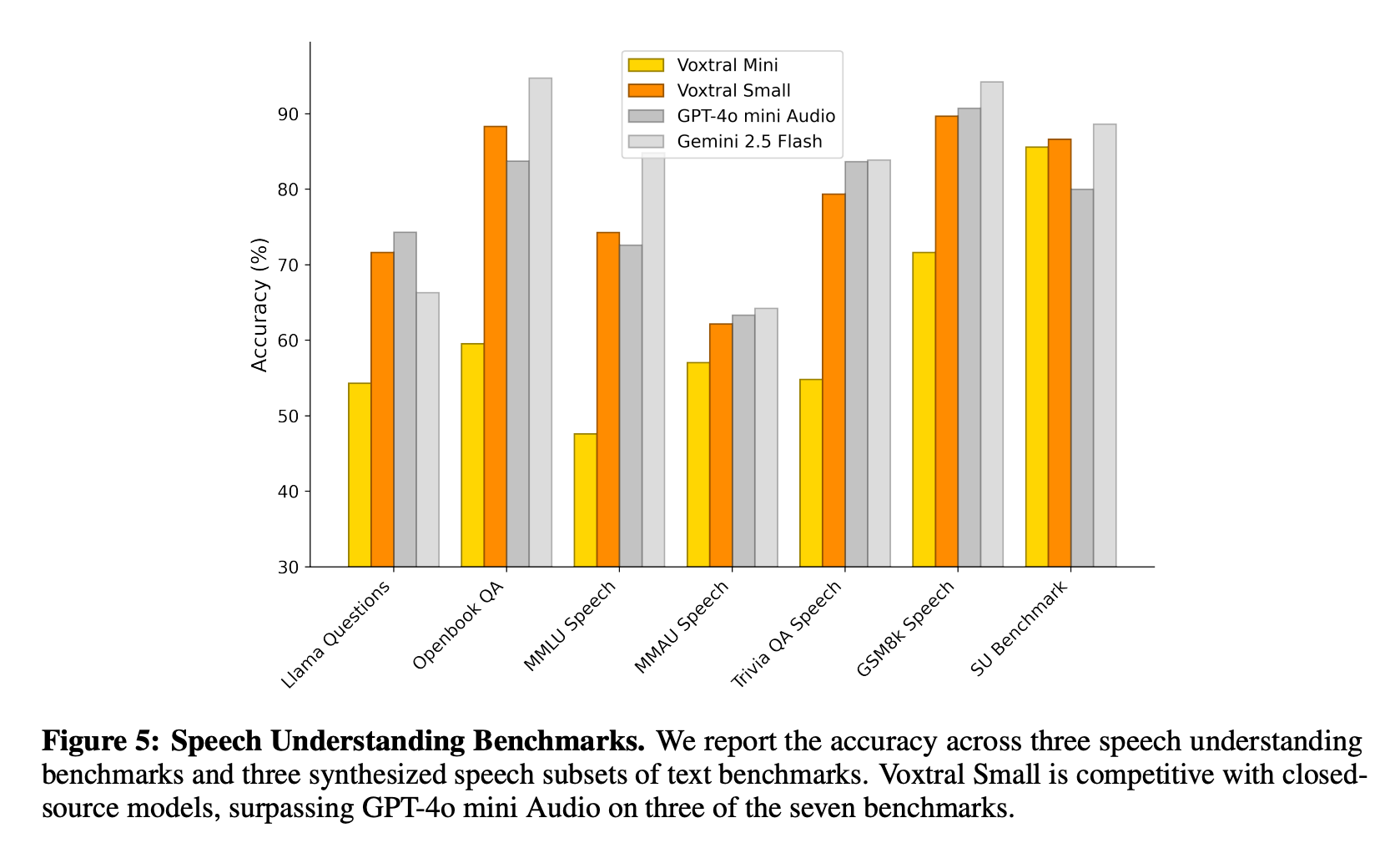
In a similar vein, Figure 5 below showcases Voxtral’s performance on a suite of speech understanding benchmarks, including Llama QA, Openbook QA, and several speech-synthesized versions of standard text tasks like MMLU and GSM8K. Voxtral Small consistently performs on par with or better than closed-source models like GPT-4o mini Audio, beating it on three of the seven tasks. This indicates that Voxtral is not just transcribing audio accurately: it is genuinely understanding and reasoning over spoken content. The model’s strong results on tasks like TriviaQA and Openbook QA suggest robust world knowledge integration, while its competitiveness on GSM8K hints at emerging capabilities in audio-based numerical reasoning.
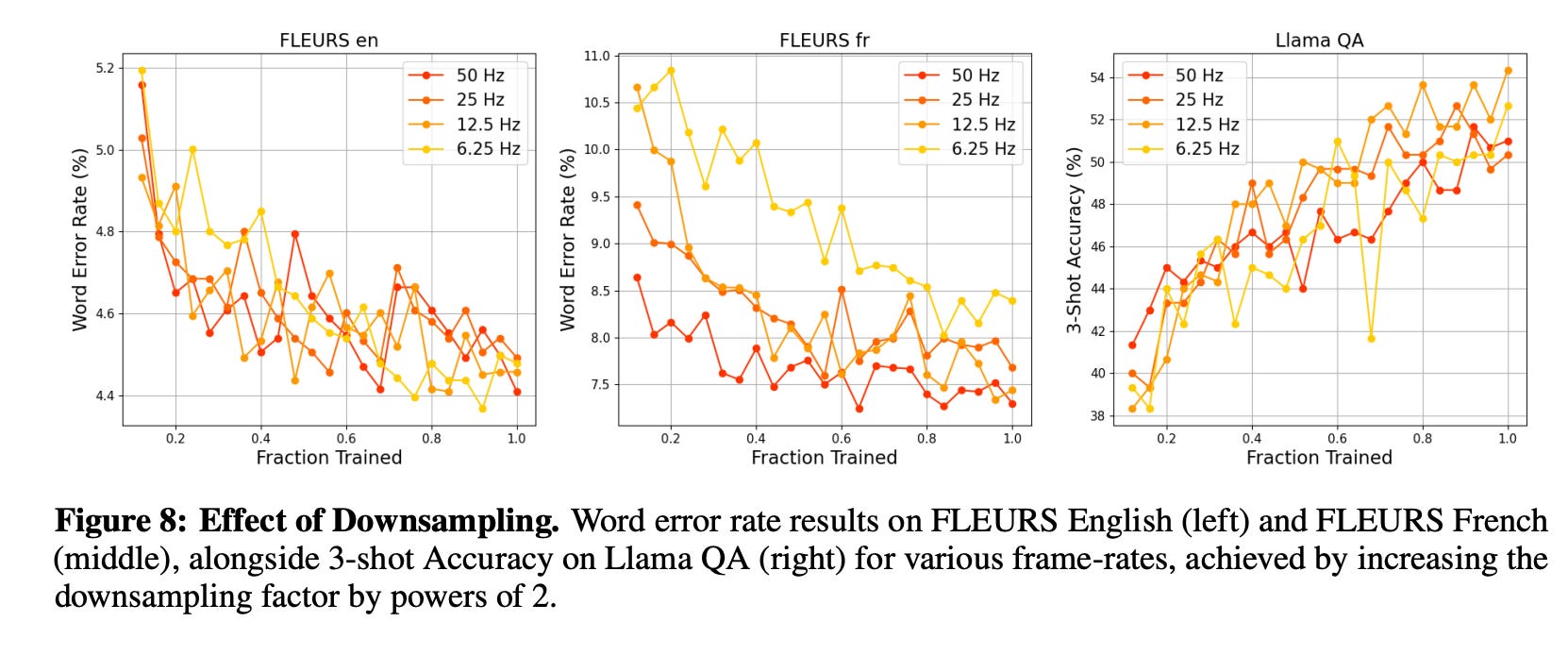
There’s a set of other interesting results but you get the gist. I’ll close out with one more. Figure 8 below explores the trade-offs involved in downsampling the audio embeddings before feeding them into the language decoder. The baseline audio encoder operates at 50 Hz, but to improve efficiency, the authors test downsampling to 25 Hz, 12.5 Hz, and 6.25 Hz. The results show that reducing the frame rate to 12.5 Hz preserves, and in some cases even improves, performance—particularly on Llama QA, where it outperforms the 50 Hz baseline. However, going further to 6.25 Hz leads to noticeable degradation, especially on French ASR. These findings support the decision to downsample by a factor of 4 (to 12.5 Hz), which strikes an effective balance between model efficiency and performance across both transcription and speech understanding tasks.
In closing the musing, there’s not much to say except that this is an exciting development in speech LLMs. The authors demonstrated the capabilities of their two proposed models in understanding spoken audio and text, both on existing and new benchmarks. Their strengths across a wide array of speech tasks, strong instruction following, and multilingual prowess make them highly versatile for complex multimodal tasks.
Key links:
Webpage: https://mistral.ai/news/voxtral/
Model weights: https://huggingface.co/mistralai/Voxtral-Mini-3B-2507 https://huggingface.co/mistralai/Voxtral-Small-24B-2507
Evals: https://huggingface.co/collections/mistralai/speech-evals-6875e9b26c78be4a081050f4
Impressive breakdown. Tackling ASR challenges through contextual and spatial modeling is exactly where meaningful voice interaction is heading. Excited to see more innovation that brings human-like understanding to noisy, multi-speaker environments.