
Musing 131: Hierarchical Reasoning Model
Interesting model from Sapient Intelligence, Singapore

Today’s paper: Hierarchical Reasoning Model. Wang et al. 26 June 2025. https://arxiv.org/pdf/2506.21734v1
Today’s paper technically came out on arXiv almost two months ago, but it’s worth covering because it is one of the rare papers that could end up being hugely influential in the future (we don’t know yet). It proposes a new model that offers a step up in reasoning compared to now established methods like Chain of Thought prompting, even for small LLMs. The name of the model is in the title of the paper itself: hierarchical reasoning model (HRM). Fair warning: today’s substack will be more on the technical side, which is unavoidable given the details involved.
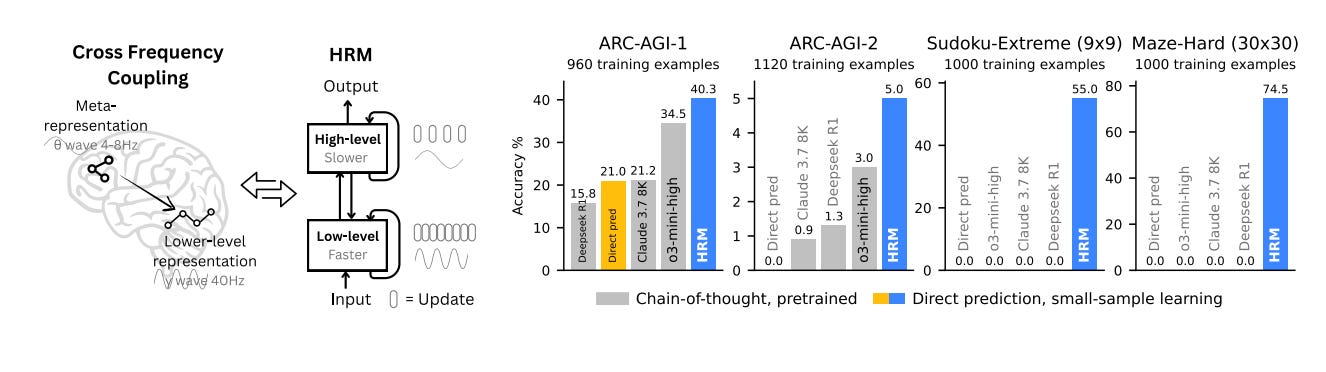
As the figure above shows, HRM is inspired by hierarchical processing and temporal separation in the brain. It has two recurrent networks operating at different timescales to collaboratively solve tasks (left). With only about 1000 training examples, the HRM (~27M parameters) surpasses state-of-the-art CoT models on inductive benchmarks (ARC-AGI) and challenging symbolic tree-search puzzles (Sudoku-Extreme, Maze-Hard) where CoT models failed completely (right). The HRM was randomly initialized, and it solved the tasks directly from inputs without chain of thoughts.
As alluded to earlier, LLM progress has relied largely on Chain-of-Thought (CoT) prompting for reasoning, which is now native to models like o1, o3 and others. CoT externalizes reasoning into token-level language by breaking down complex tasks into simpler intermediate steps, sequentially generating text using a shallow model. However, CoT for reasoning is a crutch, not a satisfactory solution. It relies on brittle, human-defined decompositions where a single misstep or a misorder of the steps can derail the reasoning process entirely. This dependency on explicit linguistic steps tethers reasoning to patterns at the token level. As a result, CoT reasoning often requires significant amount of training data and generates large number of tokens for complex reasoning tasks, resulting in slow response times. The authors argue that a more efficient approach is needed to minimize these data requirements.
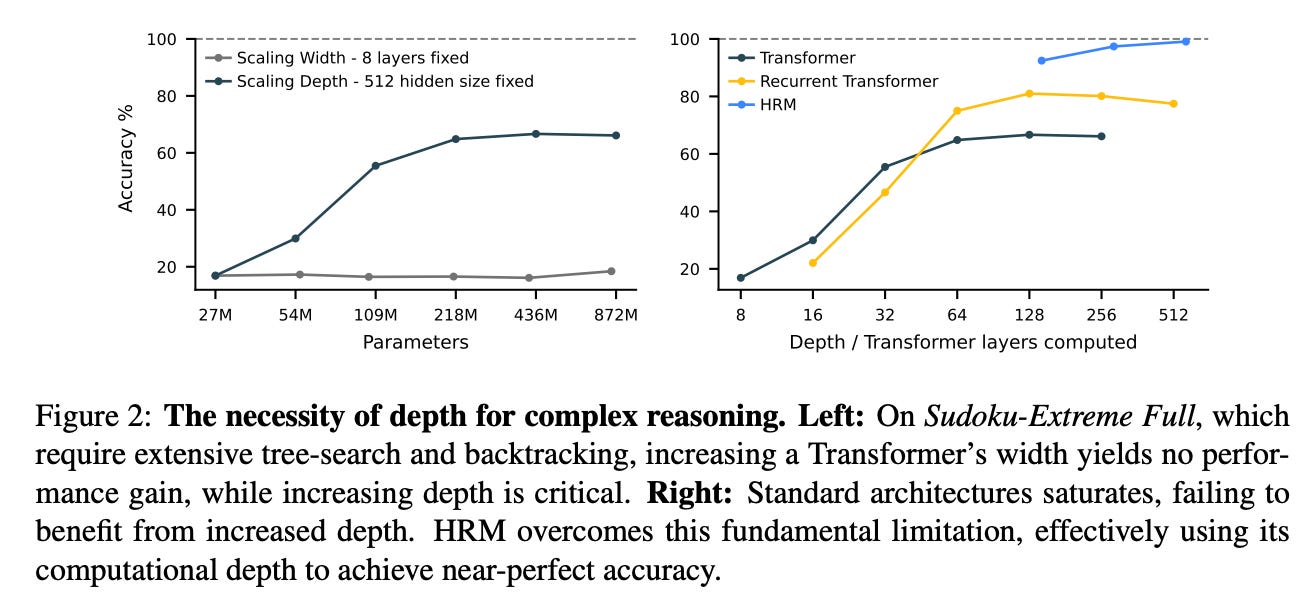
The authors’ approach aligns with the understanding that language is a tool for human communication, not the substrate of thought itself (this can be controversial in some philosophical schools of thought, but we’ll go with it; it’s certainly very plausible). Hence, the authors explore “latent reasoning”, where the model conducts computations within its internal hidden state space. Unfortunately, the power of latent reasoning is still fundamentally constrained by a model’s effective computational depth (see Figure 2 below). Naively stacking layers is notoriously difficult due to vanishing gradients, which plague training stability and effectiveness. Recurrent architectures, a natural alternative for sequential tasks, often suffer from early convergence, rendering subsequent computational steps inert, and rely on the biologically implausible, computationally expensive and memory intensive Backpropagation Through Time (BPTT) for training.
As with so many other models, HRM is inspired by the brain itself. It provides a compelling blueprint for achieving the effective computational depth that contemporary artificial models lack. It organizes computation hierarchically across cortical regions operating at different timescales, enabling deep, multi-stage reasoning. Recurrent feedback loops iteratively refine internal representations, allowing slow, higher-level areas to guide—and fast, lower-level circuits to execute—subordinate processing while preserving global coherence. Notably, the brain achieves such depth without incurring the prohibitive credit-assignment costs that typically hamper recurrent networks from BPTT.
HRM is designed to significantly increase the effective computational depth. It features two coupled recurrent modules: a high-level (H) module for abstract, deliberate reasoning, and a low-level (L) module for fast, detailed computations. The approach avoids the rapid convergence of standard recurrent models through a process we term “hierarchical convergence.” The slow-updating H-module advances only after the fast-updating L-module has completed multiple computational steps and reached a local equilibrium, at which point the L-module is reset to begin a new computational phase. Additionally, the authors propose a one-step gradient approximation for training HRM, which offers improved efficiency and eliminates the requirement for BPTT. This design maintains a constant memory footprint (O(1) compared to BPTT’s O(T) for T timesteps) throughout the backpropagation process, making it scalable and more biologically plausible. Here’s a more technical description:

This process allows the HRM to perform a sequence of distinct, stable, nested computations, where the H-module directs the overall problem-solving strategy and the L-module executes the intensive search or refinement required for each step. Although a standard RNN may approach convergence within T iterations, the hierarchical convergence benefits from an enhanced effective depth of NT steps. As empirically shown subsequently, this mechanism allows HRM both to maintain high computational activity (forward residual) over many steps (in contrast to a standard RNN, whose activity rapidly decays) and to enjoy stable convergence. This translates into better performance at any computation depth.
With that, let’s jump to experiments. The authors evaluate the method on the ARC-AGI, Sudoku, and Maze benchmarks. The ARC-AGI benchmark evaluates general fluid intelligence through IQtest-like puzzles that require inductive reasoning. Each task provides a few input–output example pairs (usually 2–3) and a test input. An AI model has two attempts to produce the correct output grid. Although some believe that mastering ARC-AGI would signal true artificial general intelligence, its primary purpose is to expose the current roadblocks in AGI progress. In fact, both conventional deep learning methods and chain-of-thought techniques have faced significant challenges with ARC-AGI-1, primarily because it requires the ability to generalize to entirely new tasks.
Sudoku and Maze are fairly self-explanatory. For all benchmarks, HRM models were initialized with random weights and trained in the sequence-to-sequence setup using the input–output pairs. The two-dimensional input and output grids were flattened and then padded to the maximum sequence length. We showed the results earlier in the figure at the beginning of the substack. Remarkably, HRM attains these results with just ~1000 training examples per task—and without pretraining or CoT labels. On the Sudoku-Extreme and Maze-Hard benchmarks, the performance gap between HRM and the baseline methods is significant, as the baselines almost never manage to solve the tasks. These benchmarks that demand lengthy reasoning traces are particularly difficult for CoT-based methods.
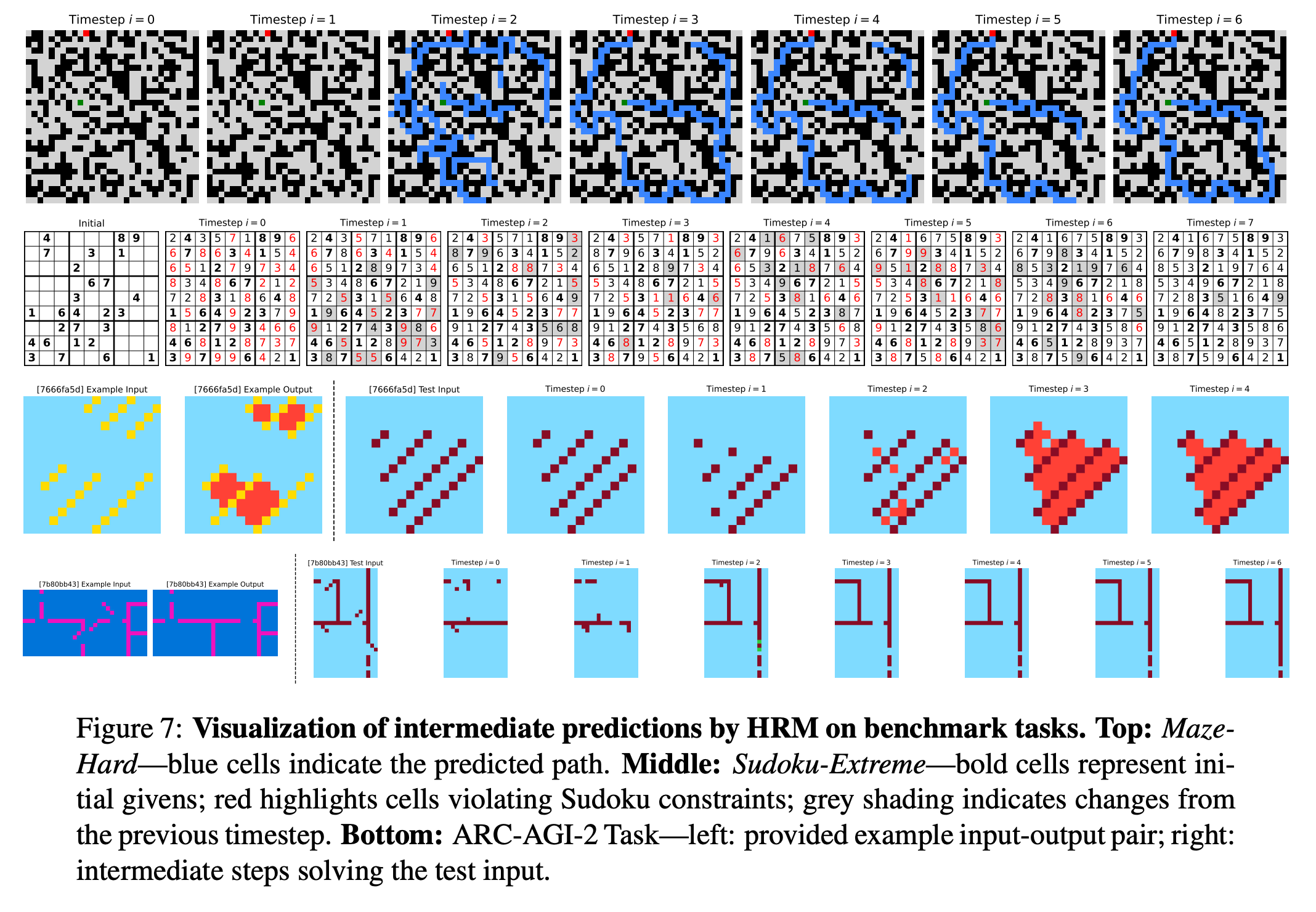
Although HRM demonstrates strong performance on complex reasoning tasks, it raises an intriguing question: what underlying reasoning algorithms does the HRM neural network actually implement? Addressing this question is important for enhancing model interpretability and developing a deeper understanding of the HRM solution space. The authors do a preliminary study and find that in the Maze task, HRM appears to initially explore several potential paths simultaneously, subsequently eliminating blocked or inefficient routes, then constructing a preliminary solution outline followed by multiple refinement iterations. In Sudoku, the strategy resembles a depth-first search approach, where the model appears to explore potential solutions and backtracks when it hits dead ends. HRM uses a different approach for ARC tasks, making incremental adjustments to the board and iteratively improving it until reaching a solution. Unlike Sudoku, which involves frequent backtracking, the ARC solution path follows a more consistent progression similar to hill-climbing optimization. Importantly, the model shows it can adapt different reasoning approaches, likely choosing an effective strategy for each particular task. Further research is needed to gain more comprehensive insights into these solution strategies.
Closing this musing, the HRM is a brain-inspired architecture that leverages hierarchical structure and multi-timescale processing to achieve substantial computational depth without sacrificing training stability or efficiency. With only 27M parameters and training on just 1000 examples, HRM effectively solves challenging reasoning problems such as ARC, Sudoku, and complex maze navigation–tasks that typically pose significant difficulties for contemporary LLM and chain-of-thought models. Although the brain relies heavily on hierarchical structures to enable most cognitive processes, these concepts have largely remained confined to academic literature rather than being translated into practical applications. The prevailing AI approach continues to favor non-hierarchical models. The authors’ results challenge this established paradigm and suggest that the HRM represents a viable alternative to the currently dominant chain-of-thought reasoning methods, advancing toward a foundational framework capable of Turing-complete universal computation.