
Musing 141: Self-Adapting Language Models
Conceptually fascinating paper out of MIT

Today’s paper: Self-Adapting Language Models. 18. Sep 2025. Zweiger et al. https://arxiv.org/abs/2506.10943
Large Language Models (LLMs) like GPT-4 and Llama 3 are incredibly powerful. Trained on vast swathes of the internet, they can write code, draft emails, and explain complex topics. Yet, they have a fundamental limitation: they are static. Once trained, their underlying knowledge is frozen in time. They can’t permanently learn a new fact from a conversation or acquire a new skill without a team of engineers initiating a massive, costly retraining process. This is like a brilliant student who can ace any exam based on their textbook but can’t update their knowledge with a new discovery unless they re-read the entire library.
But what if a model could teach itself? That’s the direction that today’s paper takes.
As a step towards better language model adaptation, the authors propose equipping LLMs with the ability to generate their own training data and fine-tuning directives in response to new inputs. They introduce a reinforcement learning algorithm that trains LLMs to generate “self-edits”—natural language instructions that specify the data and, optionally, optimization hyper-parameters for updating the model’s weights (see Figure 1 below). They refer to such models as Self-Adapting LLMs (SEAL).

The core idea behind SEAL is to let an LLM generate its own study materials. When presented with a new piece of information—say, a paragraph about a recent scientific discovery—the model doesn’t just read it; it creates a “self-edit.” This self-edit is a set of instructions and custom-tailored data that the model generates for itself to learn from. This might involve rephrasing the information, drawing logical implications, or even specifying the exact parameters for its own update, like the learning rate and number of training epochs. The process works through a clever two-step loop, as illustrated in the paper’s overview (Figure 1 above).
The Inner Loop (The Update): The model takes a new piece of data and generates a self-edit. It then uses this self-edit to perform a small, targeted fine-tuning update on its own parameters. This is a quick and efficient modification, not a full-scale retraining.
The Outer Loop (The Learning): How does the model know if its self-edit was any good? This is where reinforcement learning comes in. After the update, the model is tested on a relevant task. If the self-edit helped it perform better (e.g., it can now correctly answer a question about the new information), it receives a “reward.” This reward signal trains the model to get better at generating effective self-edits over time. In essence, the model learns how to learn.
This entire process is self-contained. Unlike other methods that bolt on separate modules, SEAL uses the model’s own powerful generative capabilities to direct its adaptation.
The researchers evaluated SEAL in two key areas to demonstrate its versatility: incorporating new knowledge and learning novel tasks from a few examples.
1. Knowledge Incorporation: Making Learning Stick. The first challenge was to see if SEAL could permanently absorb new facts from a text passage. The goal is for the model to answer questions about the passage without having to see it again. In this setup, shown in Figure 2 below, the model reads a passage and the self-edit consists of generating a list of “implications”—clear, concise statements derived from the text.

2. Few-Shot Learning: Mastering New Skills. The second test was on the Abstraction and Reasoning Corpus (ARC), a benchmark that tests a model’s ability to learn abstract tasks from just a handful of examples. Here, the self-edit was more complex. As seen in Figure 3 below, the model had to generate a complete configuration for its own training, specifying data augmentation strategies (like rotating or flipping grids) and optimization hyperparameters (like the learning rate).
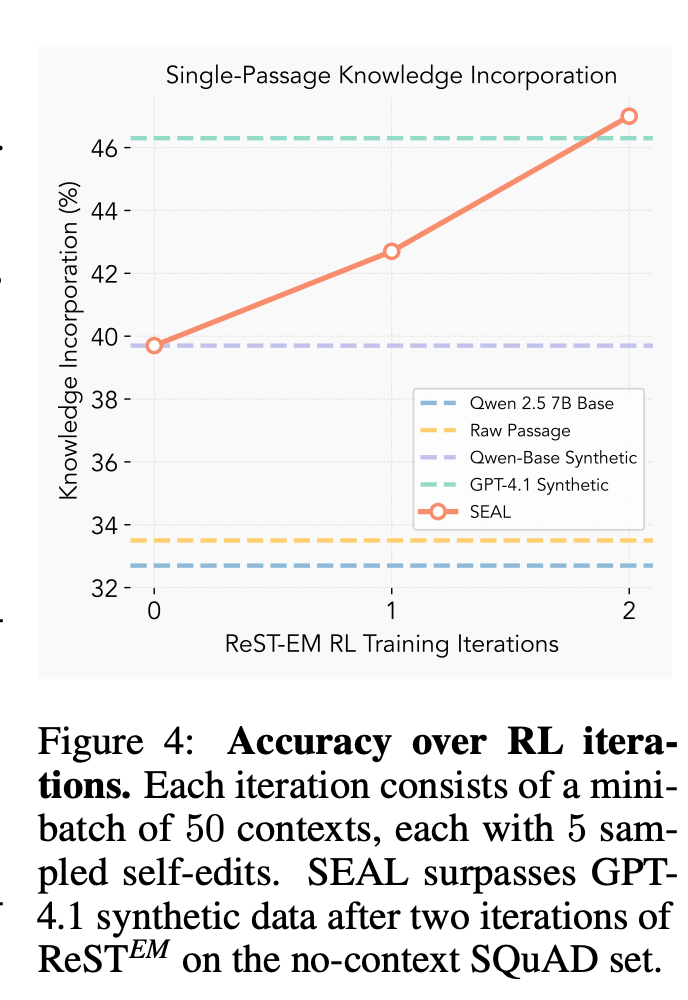
Let’s move to experimental results. The results are striking. As shown in the performance graph (Figure 4), finetuning on the raw passage barely improves the model’s ability to answer questions from memory (a score of 33.5% vs. 32.7% for the base model). However, when the model finetunes on the self-edits it generates, its accuracy jumps significantly. After just two rounds of reinforcement learning, SEAL’s performance rose to 47.0%. Remarkably, the self-generated data from SEAL, a 7-billion-parameter model, proved more effective for learning than synthetic data generated by the much larger GPT-4.1.
A qualitative look at these self-edits (Figure 5) reveals why. Initially, the model’s implications are simple restatements. But after RL training, they become more structured, breaking down the information into atomic facts that are easier for the model to digest and integrate into its weights. The model literally learns to create better study notes for itself.

On the second challenge (mastering new skills) SEAL also demonstrated a dramatic improvement. A standard model attempting to learn from self-edits without RL training succeeded on only 20% of the tasks. After SEAL’s reinforcement learning loop, the success rate shot up to 72.5%. The model had successfully learned to configure its own learning pipeline for a novel reasoning task.
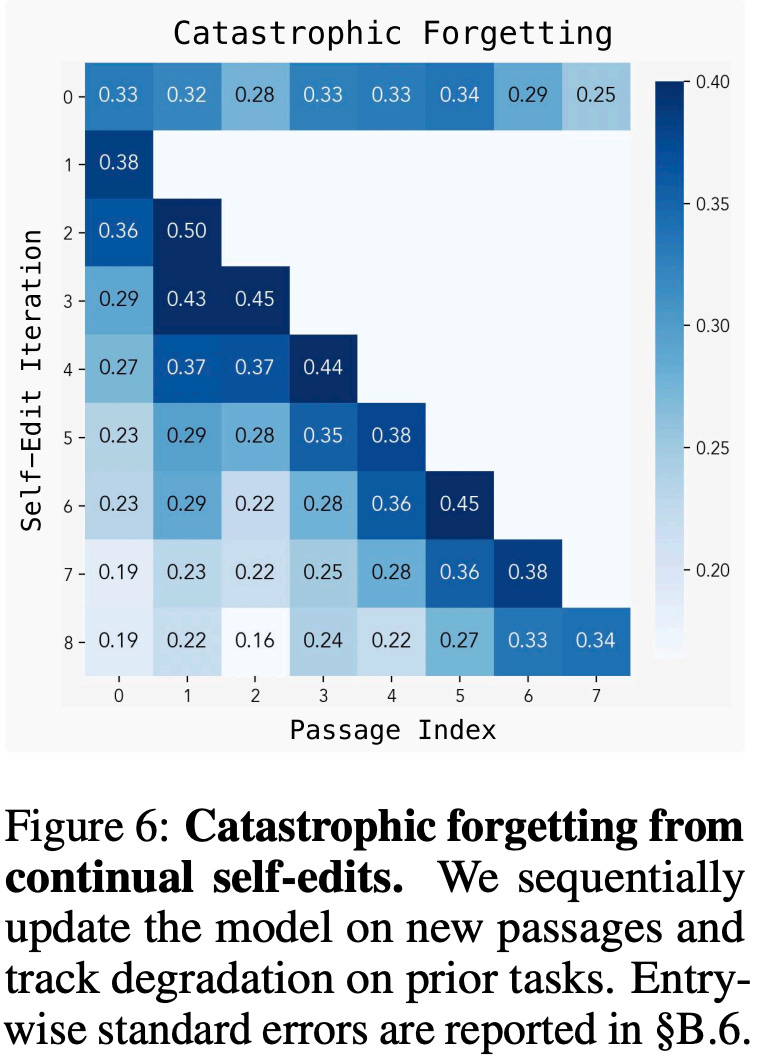
In closing this musing, the approach is not without its limitations. One of the biggest hurdles in continual learning is catastrophic forgetting or the tendency for a model to forget old knowledge as it learns new things. The researchers show in Figure 6 that while SEAL can handle a sequence of several updates, performance on previously learned tasks gradually degrades. Preventing this remains an open challenge.
Despite this, SEAL represents a paradigm shift. It moves away from the idea of models as static, frozen artifacts and toward a future of dynamic, continuously improving AI. In a world where we are rapidly approaching a “data wall” (the point at which we will have trained models on all available human-generated text) a model’s ability to generate its own high-quality training data will be paramount. SEAL provides a powerful and promising framework for making that a reality.
Wow, this is a game-changer! It's super interesting to think how self-adapting LLMs might impact the future of teacing. What are your thoughts on that? Always appreciate your sharp analysis!