
Musing 143: History-Aware Reasoning for GUI Agents
Interesting paper out of Zhejiang University and Ant accepted to AAAI 2026

Today’s paper: History-Aware Reasoning for GUI Agents. Wang et al. 12 Nov. 2025. https://arxiv.org/pdf/2511.09127
Multimodal Large Language Models (MLLMs) are making AI agents that can operate our apps and websites—so-called Graphical User Interface (GUI) agents—a reality. The dream is to give an agent a complex goal, like “Find a recipe for chocolate chip cookies, create a shopping list for the ingredients, and then find them on eBay,” and have it execute the task flawlessly.
While today’s agents are getting good at understanding a single screen, they often fall apart during these long-horizon tasks. They exhibit what researchers call “history-agnostic reasoning.” In simpler terms, they have the memory of a goldfish. Each step is treated as a new puzzle, disconnected from the previous actions. An agent might forget it already added an item to a cart or get stuck in a loop, repeating the same error.
Today’s paper introduces a framework to solve this very problem. The authors propose a method to give these agents a “short-term memory,” allowing them to learn from the chain of their own actions and, importantly, from their mistakes. Current state-of-the-art methods use a System-2 reasoning approach, where the agent generates an explicit chain of thought before taking an action. However, this reasoning is often myopic. The agent analyzes the current screen but fails to consider the vital context of how it got there. This makes navigating complex, multi-step tasks a significant challenge. It’s the difference between following a single instruction and understanding a whole recipe.
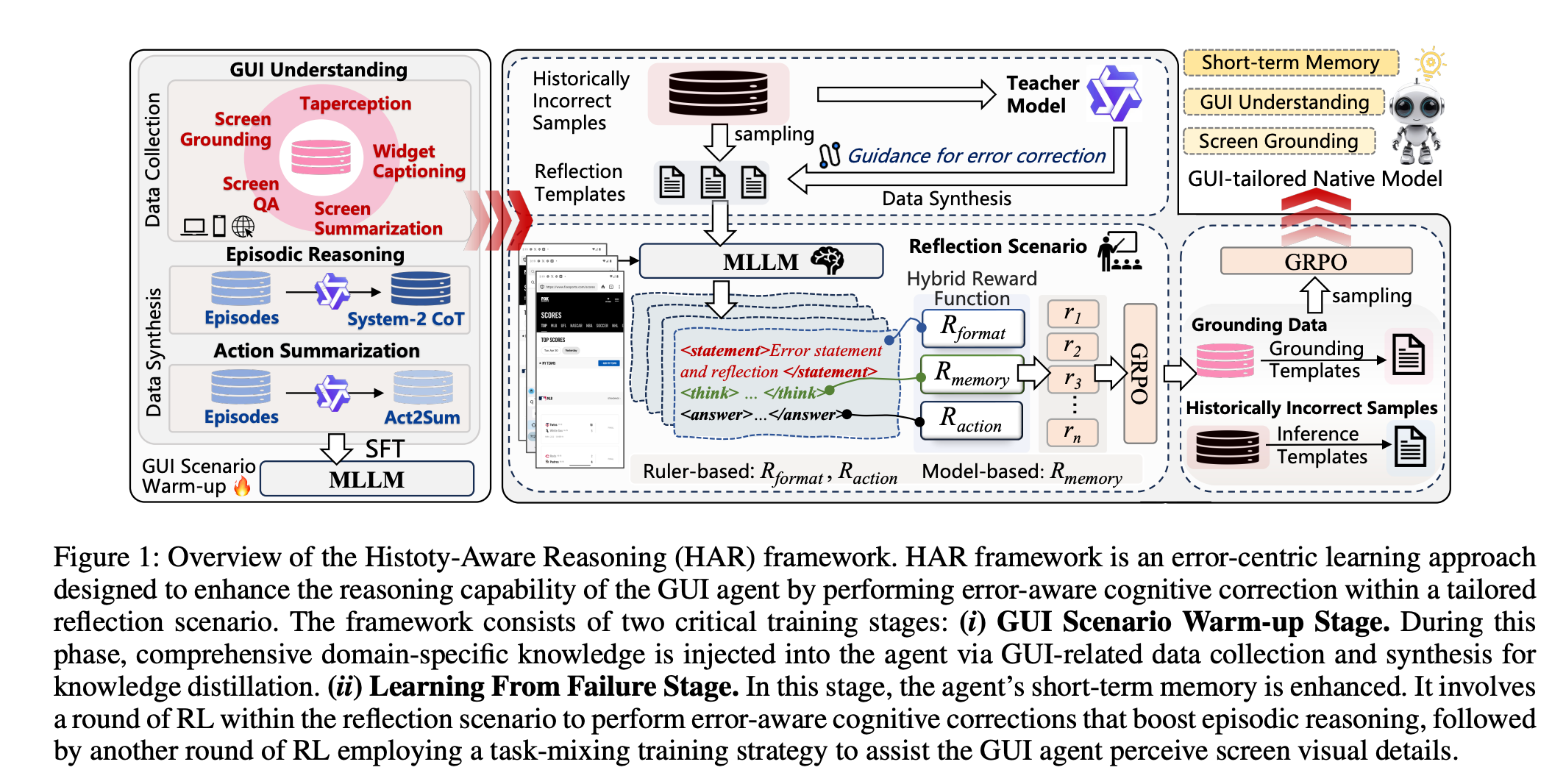
The core idea behind the authors’ proposed History-Aware Reasoning (HAR) framework is to train the agent through a process of reflection and self-correction. Instead of just learning from successful task completions, the agent is forced to analyze its own failures and understand why it made an error.
As illustrated in Figure 1 of the paper below, the framework has three key components:
Reflective Learning Scenario: The process starts by collecting instances where the agent failed a task (the authors call these “historically incorrect samples”). These failures become the training ground.
Customized Correction Guidelines: A powerful teacher model analyzes each failure and generates a set of simple, tailored correction guidelines. These aren’t the direct answers, but hints that guide the agent toward the correct logic. For example, a guideline might be: “Consider the context of previous actions to determine the next logical step.”
A Hybrid RL Reward Function: The agent is then trained using Reinforcement Learning (RL) in this reflective environment. It’s rewarded for more than just getting the action right. The hybrid reward function also incentivizes:
Memory (
R_memory): The agent gets a specific reward if its chain-of-thought explicitly references historical interactions.Precision (
R_action): For click actions, the reward is scaled based on how close the click is to the target, encouraging fine-grained perception of the screen.
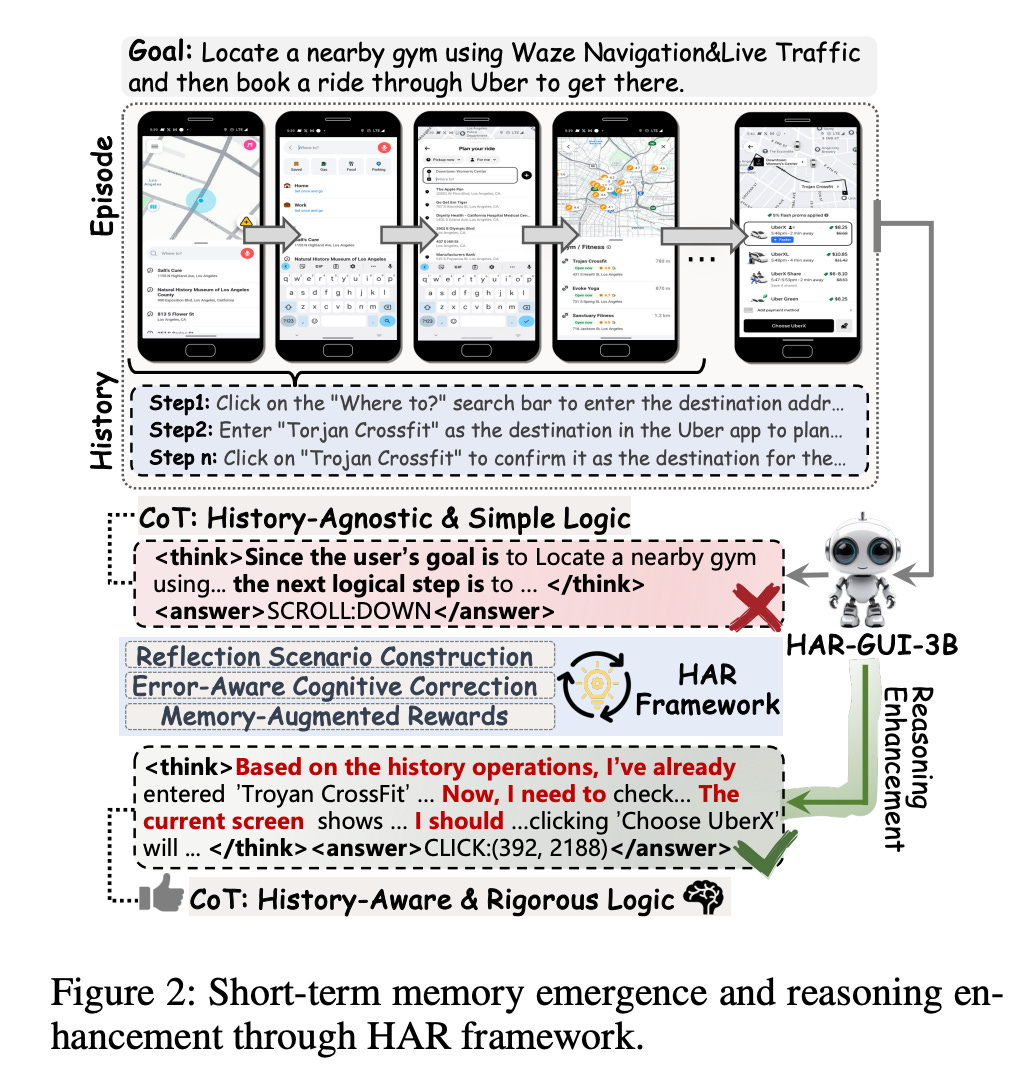
The impact of this process is a fundamental shift in the agent’s reasoning style. As shown in Figure 2, the agent’s internal monologue (chain-of-thought) transforms from a simple, history-agnostic analysis to a history-aware and more rigorous one. The agent’s thought process starts to look like: “Based on my history, I’ve already done X... Now, looking at the current screen, the next logical step is Y.”
Using this framework, the authors developed HAR-GUI-3B, a 3-billion-parameter native GUI agent. The results are impressive.
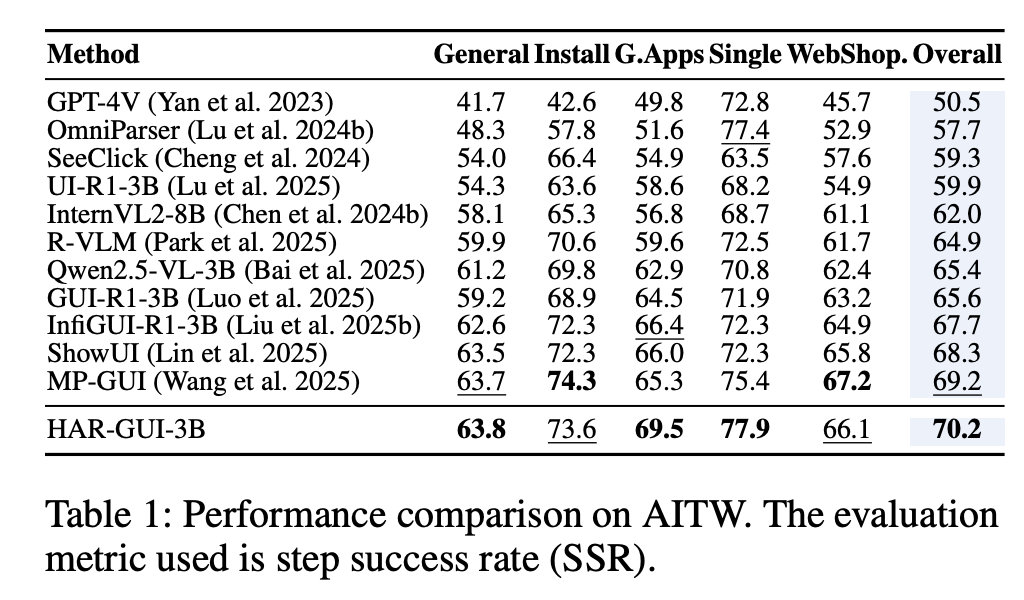
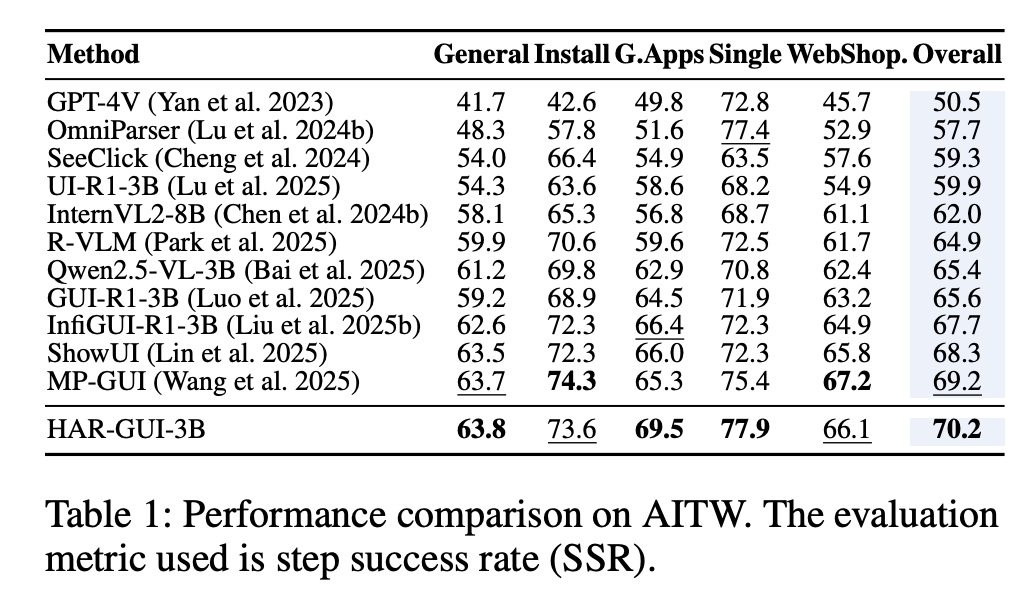
Superior Performance: Across a range of standard benchmarks like AITW, Mind2Web, and GUI-Odyssey, HAR-GUI-3B consistently outperforms other models of a similar size. As seen in Table 1 below on a specific test and metric, it even competes with or surpasses much larger models.
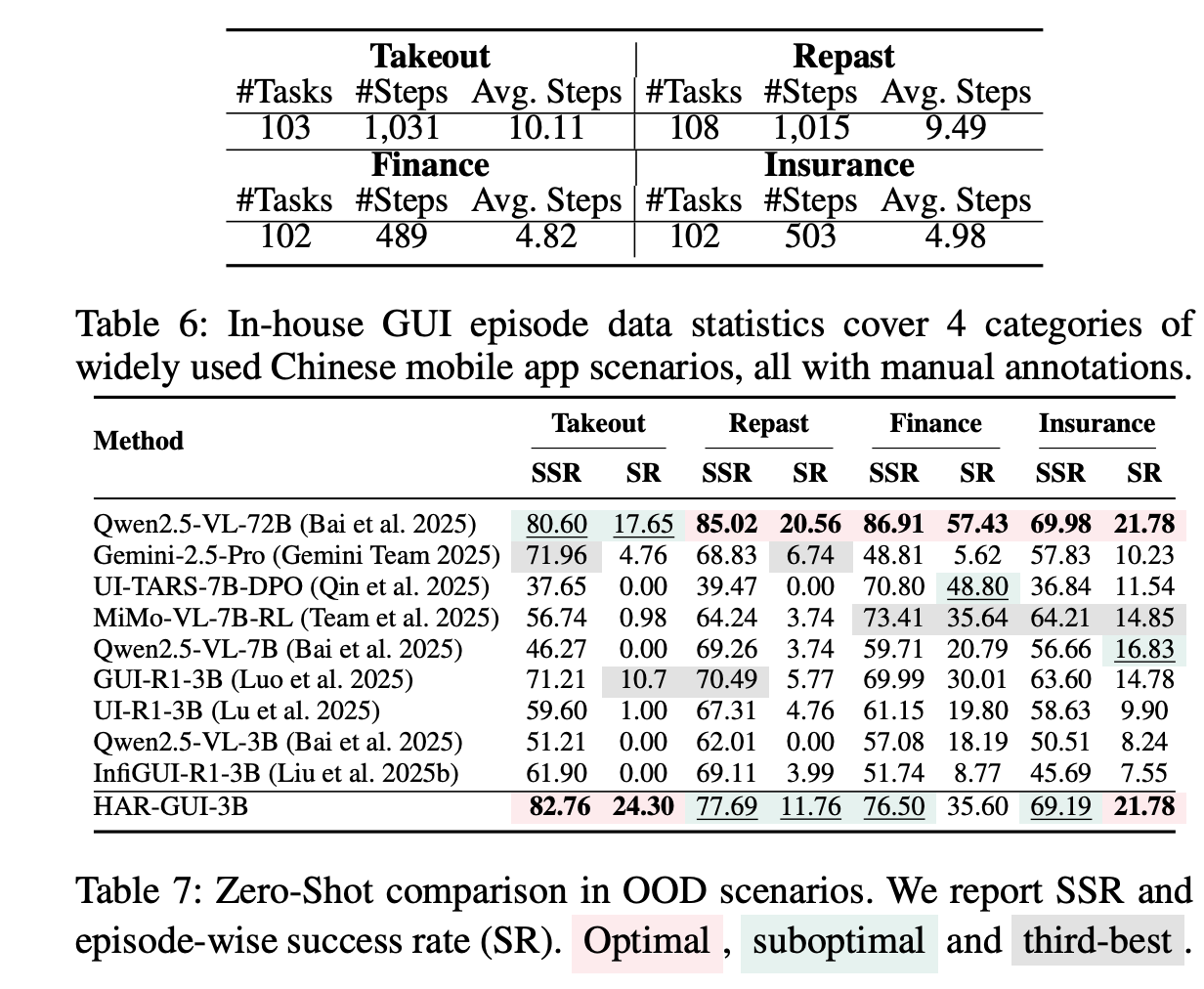
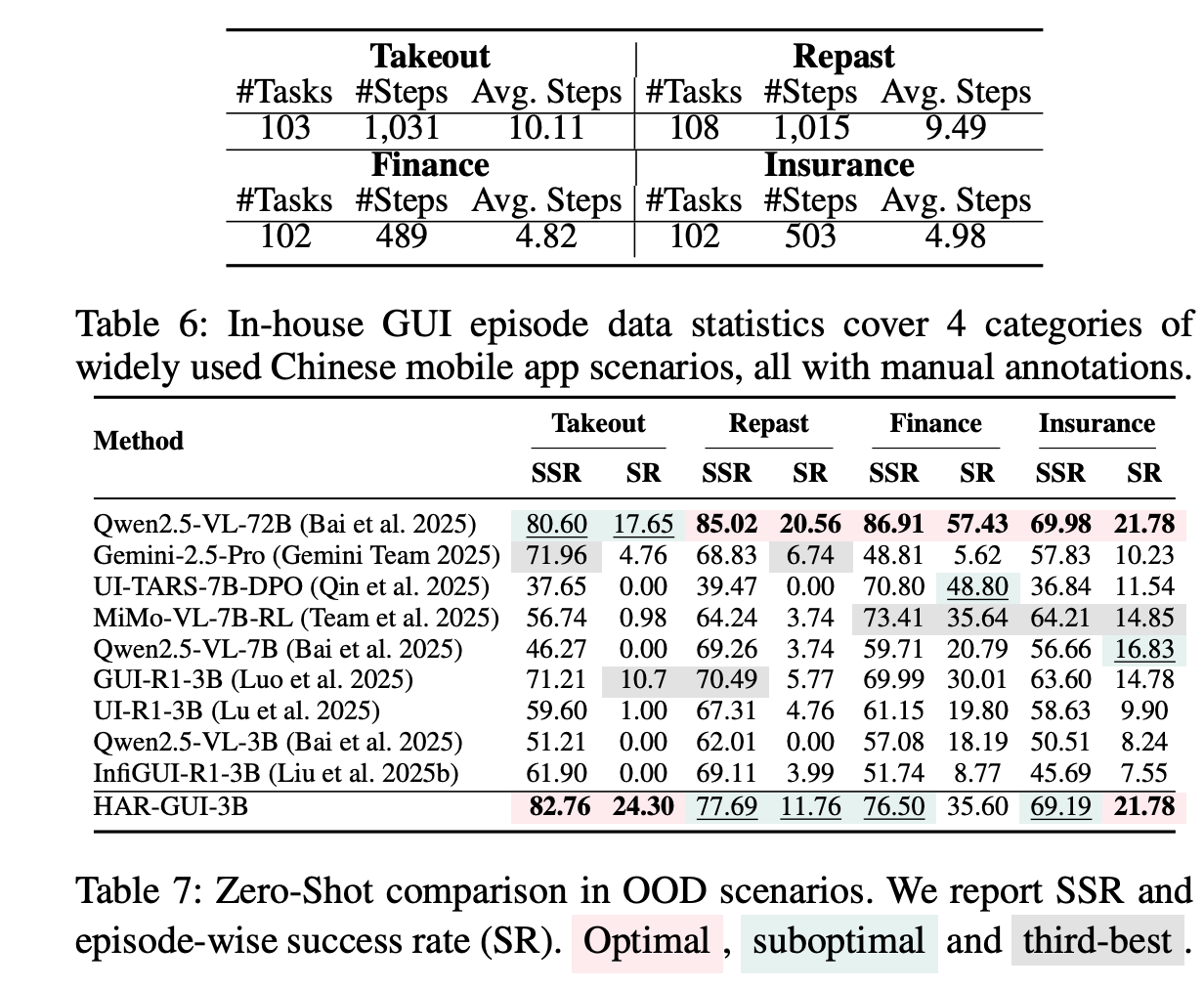
Excellent Generalization: The most telling results come from an out-of-distribution (OOD) test on a custom-built benchmark of Chinese mobile apps (Table 6). Here, HAR-GUI-3B significantly outperforms its peers and even massive commercial models (Table 7), demonstrating that the reasoning skills it learned are not brittle but robust and generalizable.
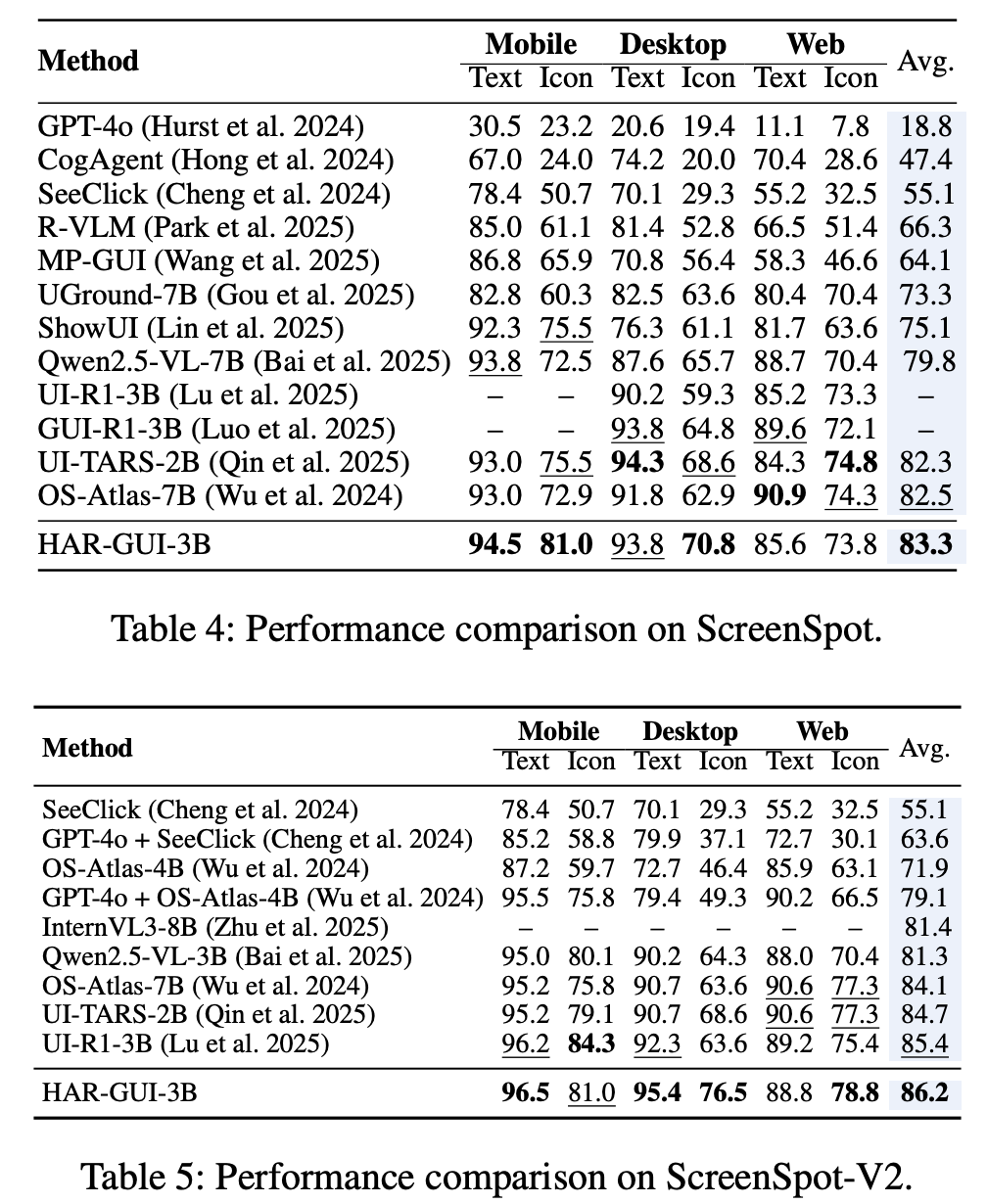
Grounded and Precise: The framework also uses a “task mixing training strategy” to ensure the agent doesn’t lose its fundamental screen-grounding ability. Tables 4 and 5 show that HAR-GUI-3B achieves state-of-the-art results in accurately locating elements on the screen.
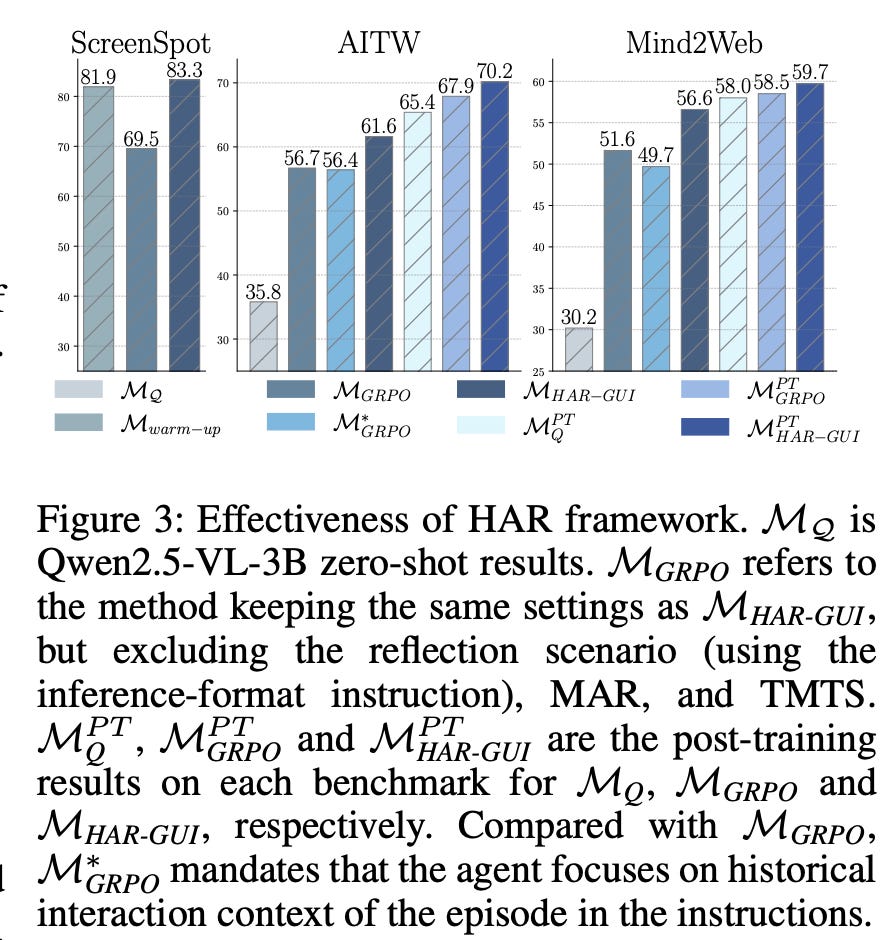
The ablation study in Figure 3 confirms that the magic is truly in the HAR framework. Simply training on errors or forcing an agent to look at history via prompts isn’t enough. What’s working is the combination of the reflective scenario, guidance, and the memory-augmented reward that cultivates this new, more resilient reasoning capability.
The HAR framework is a significant step toward creating more reliable and intelligent GUI agents. By teaching agents to learn from their episodic memory, we move from building simple instruction-followers to developing true problem-solvers that can tackle the long, complex tasks required for real-world automation.
For practitioners and researchers in the AI space, this work provides a clear and effective recipe for enhancing the reasoning capabilities of agentic models, a crucial hurdle to overcome on the path to general-purpose AI assistants.
To dive deeper, you can read the full paper here and find the code on GitHub.