
Musing 146: Evolving Excellence: Automated Optimization of LLM-based Agents
Fascinating paper out of the United Kingdom

Today’s paper: Evolving Excellence: Automated Optimization of LLM-based Agents. Brookes et al. 9 Dec 2025. https://arxiv.org/pdf/2512.09108
The rapid transition of Large Language Model (LLM) agents from experimental prototypes to complex production pipelines has revealed a critical bottleneck: the inherent fragility of their configurations. While sophisticated architectures like ReAct and Tree of Thoughts offer reasoning capabilities, real-world performance is frequently compromised by suboptimal prompts, tool descriptions, and parameter settings that interact in non-obvious ways. Current optimization methods largely rely on manual trial-and-error, a process that is not only labor-intensive but results in brittle systems unable to generalize across tasks.
In today’s paper, the authors explore how evolutionary algorithms can replace intuition-based tuning with a systematic, black-box optimization framework. By treating agent configuration as a high-dimensional search problem, they demonstrate how automated, semantically aware genetic operators can uncover substantial gains in accuracy and cost-efficiency without requiring architectural modifications.
The proposed solution to this configuration bottleneck is Artemis, a platform designed to automate the tuning workflow while remaining agnostic to the underlying agent architecture. As illustrated in Figure 1 below, the system introduces a “no-code” interface that fundamentally changes how practitioners interact with optimization tasks. rather than requiring engineers to manually locate and modify individual prompt files or parameter sets, the platform utilizes semantic search to automatically discover optimizable components based on natural-language goals. An engineer need only define the objective, such as “maximize accuracy while reducing API calls”, and the system identifies the relevant structural elements within the codebase, effectively decoupling the optimization logic from the agent’s internal implementation.
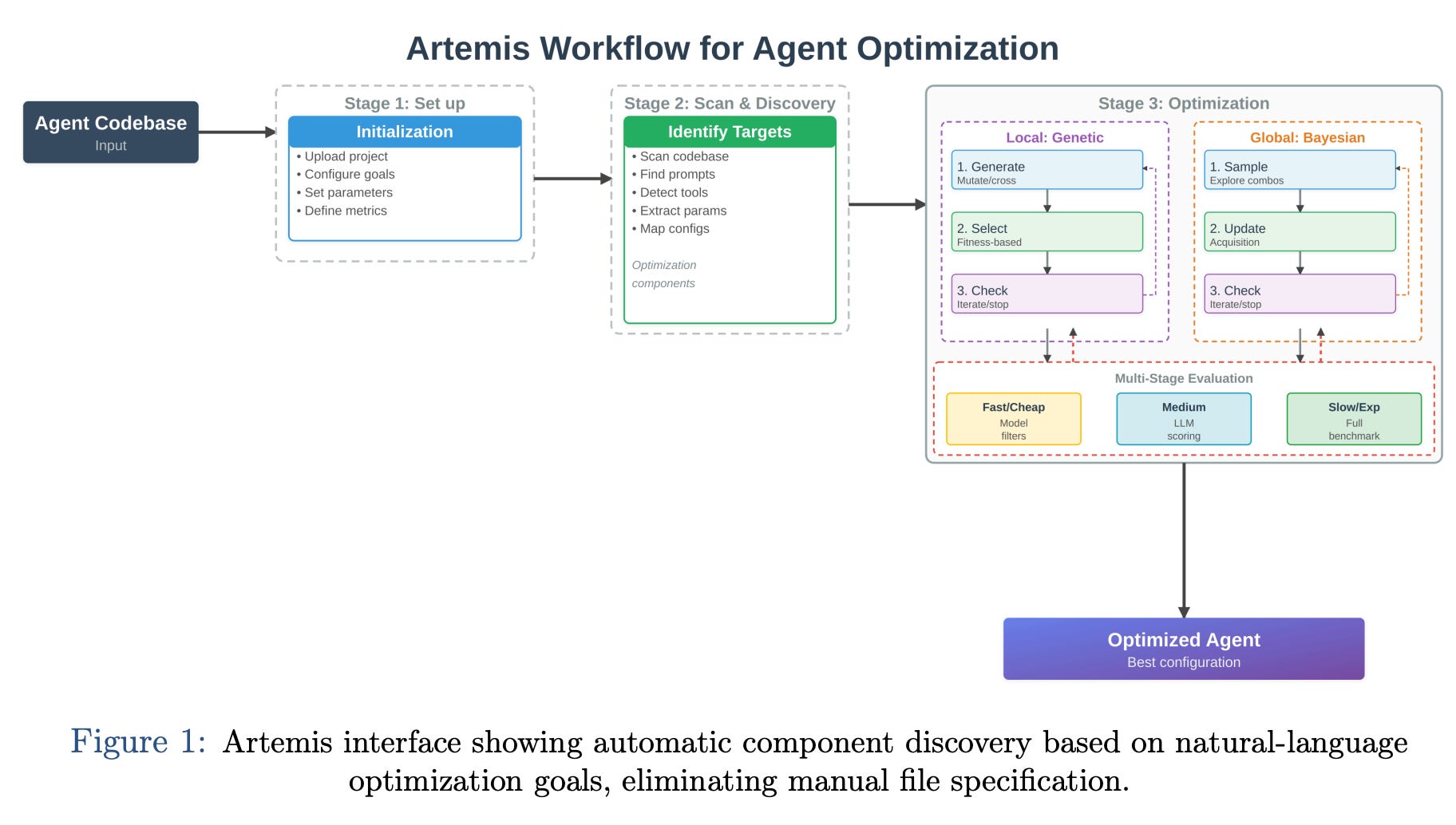
Under the hood, this automated discovery powers a specialized evolutionary engine. Unlike traditional genetic algorithms that might randomly perturb values and break semantic validity, the platform employs LLM-driven genetic operators to perform “semantically aware” mutations. The system generates populations of candidate configurations, treating natural language prompts and discrete parameters as evolving traits. By using execution logs and benchmark feedback as fitness signals, it iteratively refines these configurations through intelligent crossover and mutation. This allows the optimization process to explore the high-dimensional intersection of prompts, tools, and model settings, capturing subtle interdependencies that are virtually impossible to identify through manual inspection or isolated component tuning.
To execute this optimization loop effectively, the platform relies on a sophisticated orchestration layer comprising three critical mechanisms:
First, it employs component discovery to parse the codebase and identify mutable elements (prompts, tool definitions, and hyperparameters) without manual tagging.
Second, the system utilizes semantic genetic operators powered by LLM ensembles; rather than performing random bit-flipping, these operators mutate text and code while preserving semantic validity, making sure that evolved configurations remain executable.
Finally, to manage the computational cost of iterative testing, the platform implements a hierarchical evaluation strategy. This mechanism filters candidate configurations using lightweight proxy scorers (such as model-based evaluation) before committing to expensive full-benchmark execution, thereby balancing the depth of the evolutionary search with the practical constraints of runtime costs.
The empirical validation of this framework across several domains and tasks suggests that automated optimization can yield gains that often elude manual tuning. In the domain of competitive programming, the system was applied to the ALE Agent on the AtCoder Heuristic Contest. Starting from a baseline acceptance rate of 66.0%, the optimization process achieved a 13.6% improvement, raising the rate to 75.0%.
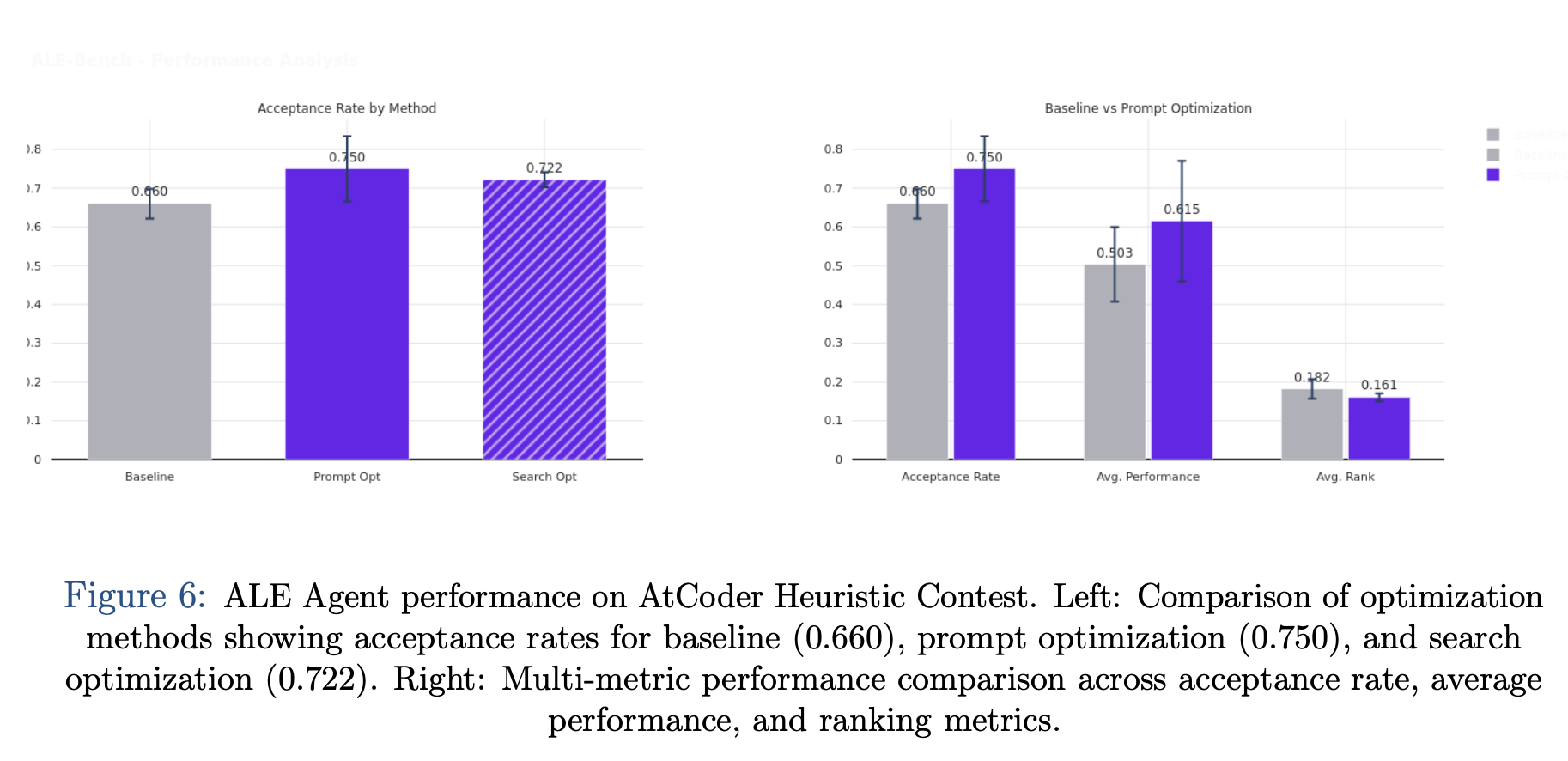
Qualitative analysis of the evolved configurations revealed a shift from generic instructions, such as “consider edge cases”, to highly organized protocols requiring explicit problem decomposition and self-correction checklists. While the computational investment was significant, the resulting agent demonstrated a level of robustness in algorithmic reasoning that manual engineering had failed to instantiate.
Beyond reasoning tasks, the framework demonstrated strong utility in performance-oriented coding and open-source model tuning. For the Mini-SWE Agent, tasked with optimizing Python code performance on the SWE-Perf benchmark, the system uncovered a statistically significant 10.1% overall performance gain. The evolutionary process discarded the agent’s original “general improvement” heuristic in favor of a “bottleneck-driven” strategy, leading to dramatic specific gains, such as a 62% improvement in the astropy library.

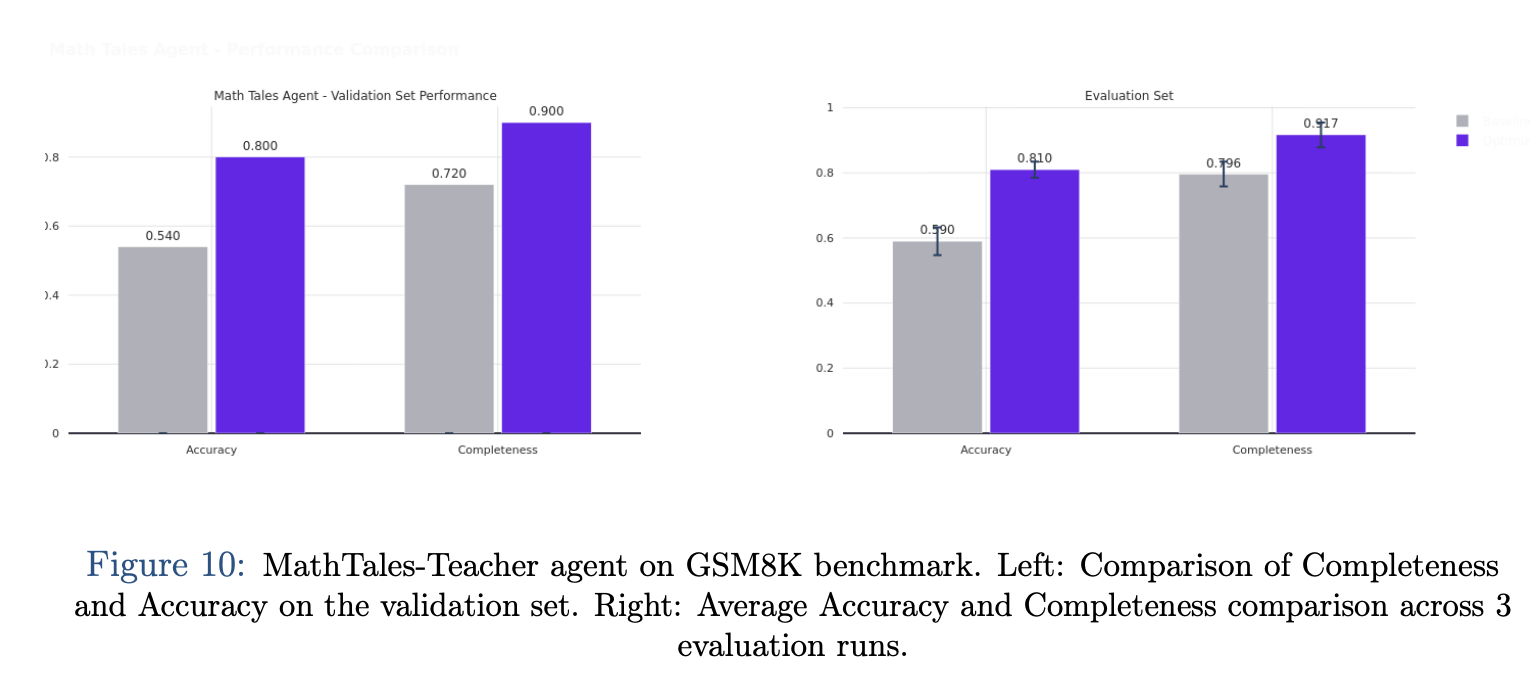
Similarly, when applied to the MathTales-Teacher Agent—powered by the smaller, open-source Qwen2.5-7B model—the platform achieved a 22% increase in accuracy on primary mathematics problems. This result is particularly notable as it confirms that evolutionary optimization is not limited to frontier commercial models but is equally effective at stabilizing the often erratic behavior of locally deployed SLMs.
Perhaps the most pragmatic result, however, emerged from the evaluation of the CrewAI Agent on the Math Odyssey benchmark, where the objective was shifted from raw performance to efficiency. Here, the optimization process successfully identified a configuration that reduced token consumption by 36.9% while maintaining statistical parity with the baseline’s accuracy. By systematically refining verbose prompts and adjusting cutoff parameters, it located a Pareto-optimal configuration that significantly lowered inference costs without compromising the agent utility. This finding highlights a key value proposition for practitioners: automated optimization serves not only to maximize benchmark scores but also to impose necessary economic constraints on production systems.
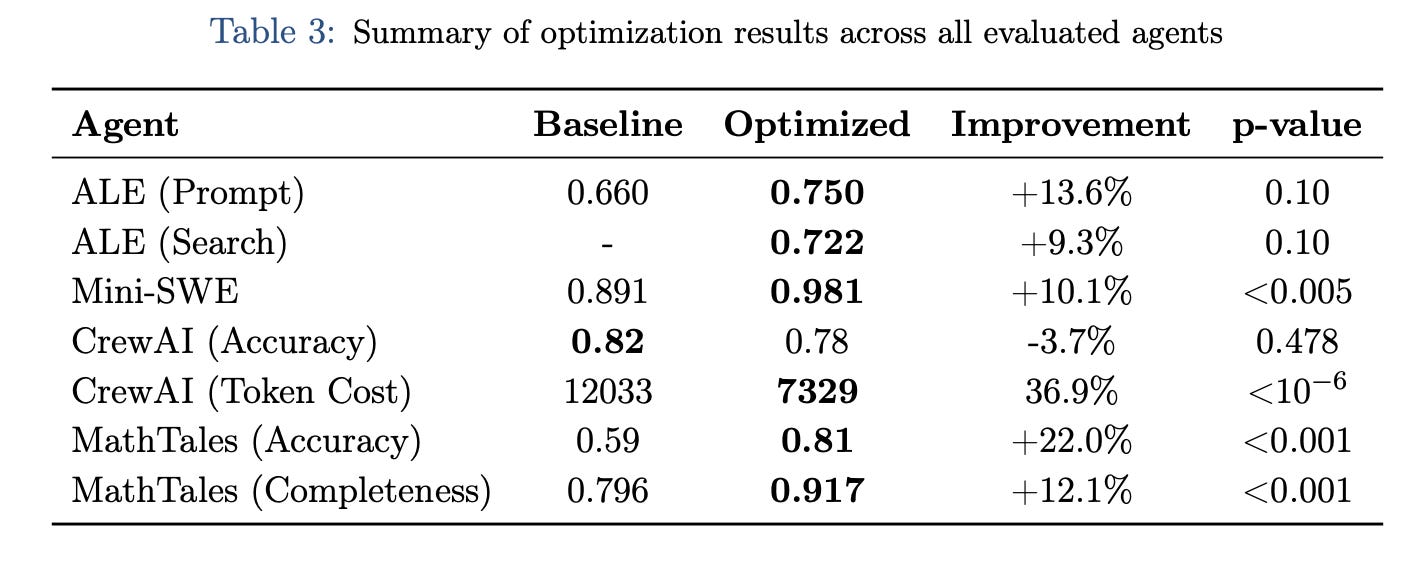
A summary of the results across all evaluated agents in Table 3 below suggests some impressive performance gains. The magnitude of improvement correlates strongly with the baseline agent’s initial maturity. Where configurations were generic or under-specified, as with the MathTales and ALE agents, the framework delivered double-digit percentage gains of 22.0% and 13.6%, respectively. Conversely, in scenarios where correctness was already high, such as the CrewAI implementation, the evolutionary search pivoted effectively to secondary objectives, securing a massive 36.9% reduction in operational costs (p < 10⁻⁶) while maintaining statistical parity in accuracy. Notably, the strong statistical significance observed across the code optimization and educational domains (p < 0.005) provides rigorous evidence that these improvements are driven by systematic structural evolution rather than random variance, validating the utility of evolutionary operators for both performance maximization and resource efficiency.
In closing this musing, the findings suggest that the future of robust agentic engineering lies not in manual intuition but in automated, evolutionary refinement. However, this transition is not without its caveats. The efficacy of such optimization is intrinsically linked to the “headroom” available in the initial configuration: well-tuned systems may encounter a performance ceiling, shifting the optimization value proposition from raw accuracy to cost efficiency. Furthermore, the substantial computational expense required for these evolutionary cycles, often spanning hundreds of hours, demands a careful analysis of the return on investment, just as the potential for overfitting to specific benchmarks requires rigorous validation on held-out datasets.
Ultimately, while frameworks like Artemis do not replace the need for sound architectural design, they offer a necessary, systematic mechanism to bridge the gap between an agent’s theoretical capabilities and its deployed reliability.
Stellar write-up on the Artemis paper. The shift from trial-and-error to evolutionary search is overdue, but what really caught my attention is how they got 36.9% cost reduction without sacrificing accuracy. That kind of Pareto optimization is gonna be critical for productin agents where token budgets actually matter, not just benchmark wins.