
Musing 150: PaperScout: An Autonomous Agent for Academic Paper Search
Fascinating paper out of State Key Lab of Cognitive Intelligence, University of Science and Technology of China

Today’s paper: PaperScout: An Autonomous Agent for Academic Paper Search with Process-Aware Sequence-Level Policy Optimization. Pan et al. 15 Jan. 2026. https://arxiv.org/pdf/2601.10029
Finding the right academic papers is getting harder as the volume of research continues to grow. Traditional search tools often struggle when a researcher has a very specific or complex request, such as finding reinforcement learning papers for protein folding that do not use Transformers. Most current systems follow a set path, like a rigid flowchart, which makes them unable to handle these fine-grained needs. The authors of a new paper introduce PaperScout, an autonomous agent that treats paper searching as a series of active choices. Instead of following a fixed recipe, it looks at what it has found so far and decides what to do next to get the best results.
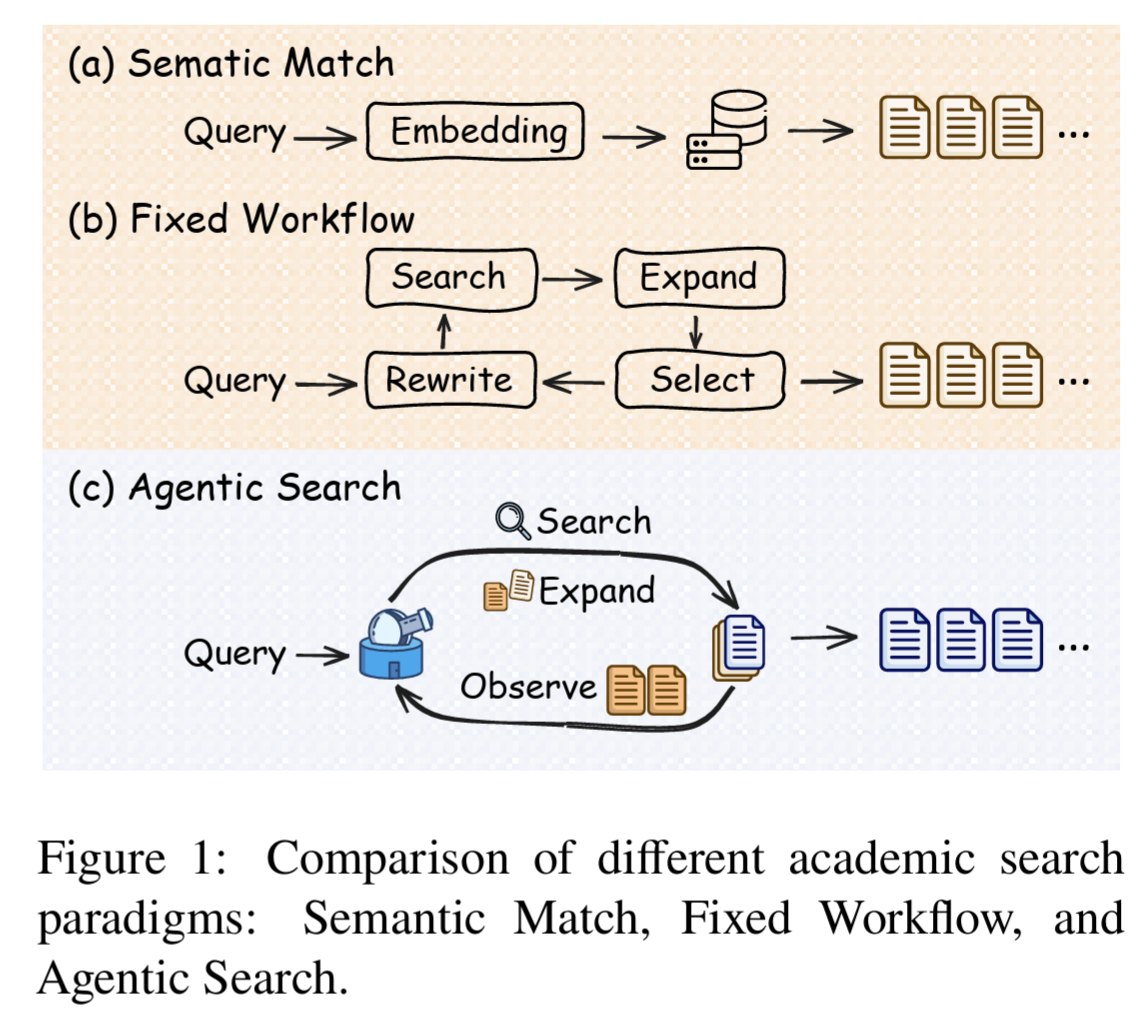
The authors’ approach differs significantly from older methods. As shown in Figure 1 below, traditional semantic matching looks for a simple link between a query and a document, while fixed workflows follow a linear routine. PaperScout moves into the territory of agentic search, where the system constantly observes its progress and picks the best tool for the moment. This allows the tool to adapt to the specific twists and turns of a complex research topic rather than sticking to a one-size-fits-all strategy.
To make this agent smart, the researchers had to rethink how AI models learn. Usually, training happens at a very fine granularity, focusing on individual words or tokens. This often leads to noisy learning because the system gets confused about which specific word led to a successful search result. The authors propose a new framework called Proximal Sequence Policy Optimization, or PSPO. This method manages the training at the level of the entire action the agent takes, such as a complete tool call, rather than just the individual bits of text that make up the command.
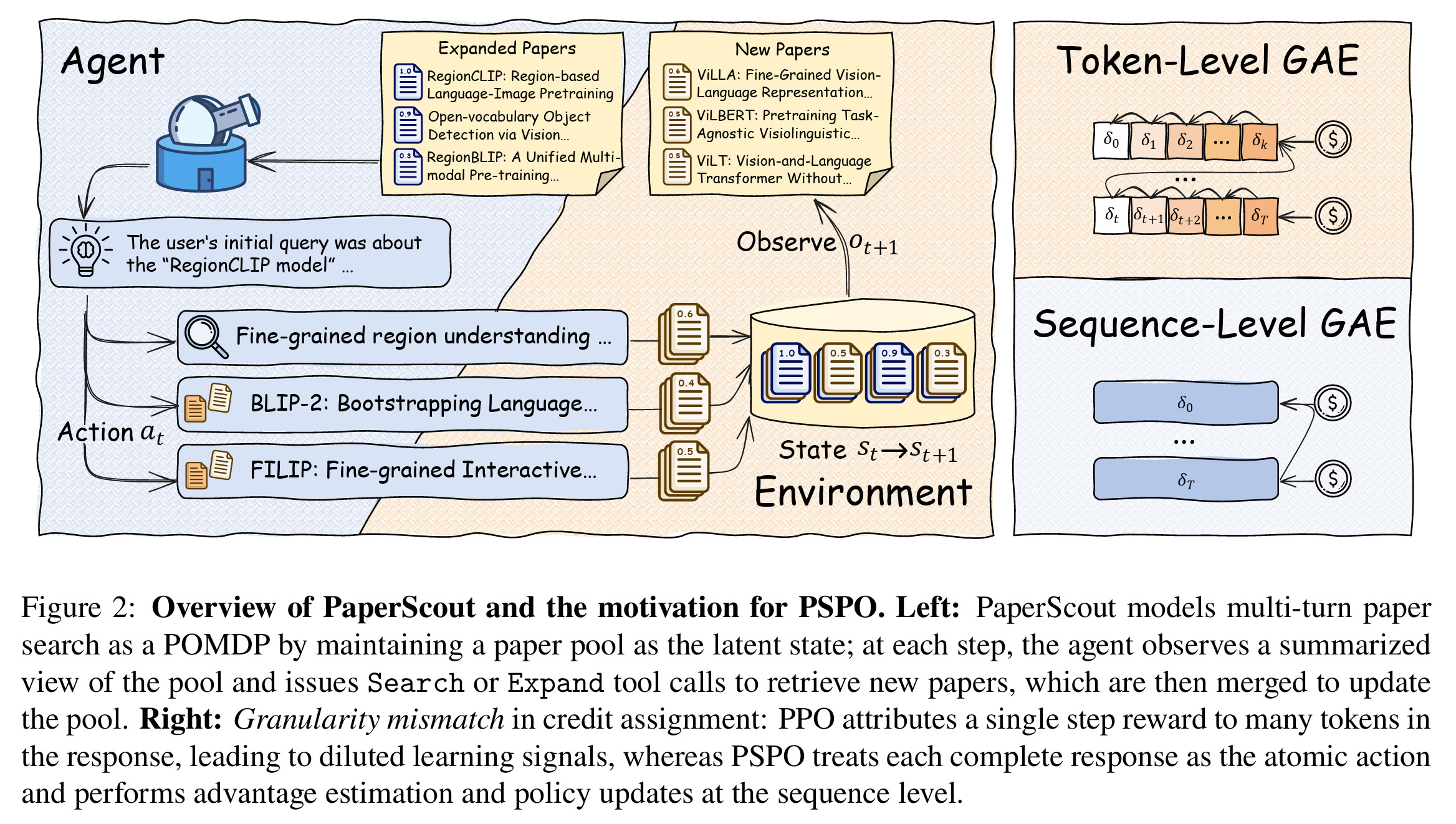
Figure 2 above illustrates this shift in perspective. On the right side of the diagram, we see the difference in how the system attributes success. While standard methods try to give feedback for every tiny step, PSPO treats each complete interaction as the primary unit of learning. This keeps the training much more stable and helps the agent understand the value of its search and expansion choices more clearly. By focusing on the sequence of actions, the system learns to navigate the vast sea of academic papers with much better precision.
The authors tested PaperScout using two main datasets: a large collection of synthetic queries and a set of real-world research questions from experts. They built a custom environment using millions of paper records and local databases to make sure the training was consistent. This setup allowed the agent to practice making thousands of searches and following citation links to see how well it could uncover the specific papers that researchers actually needed.
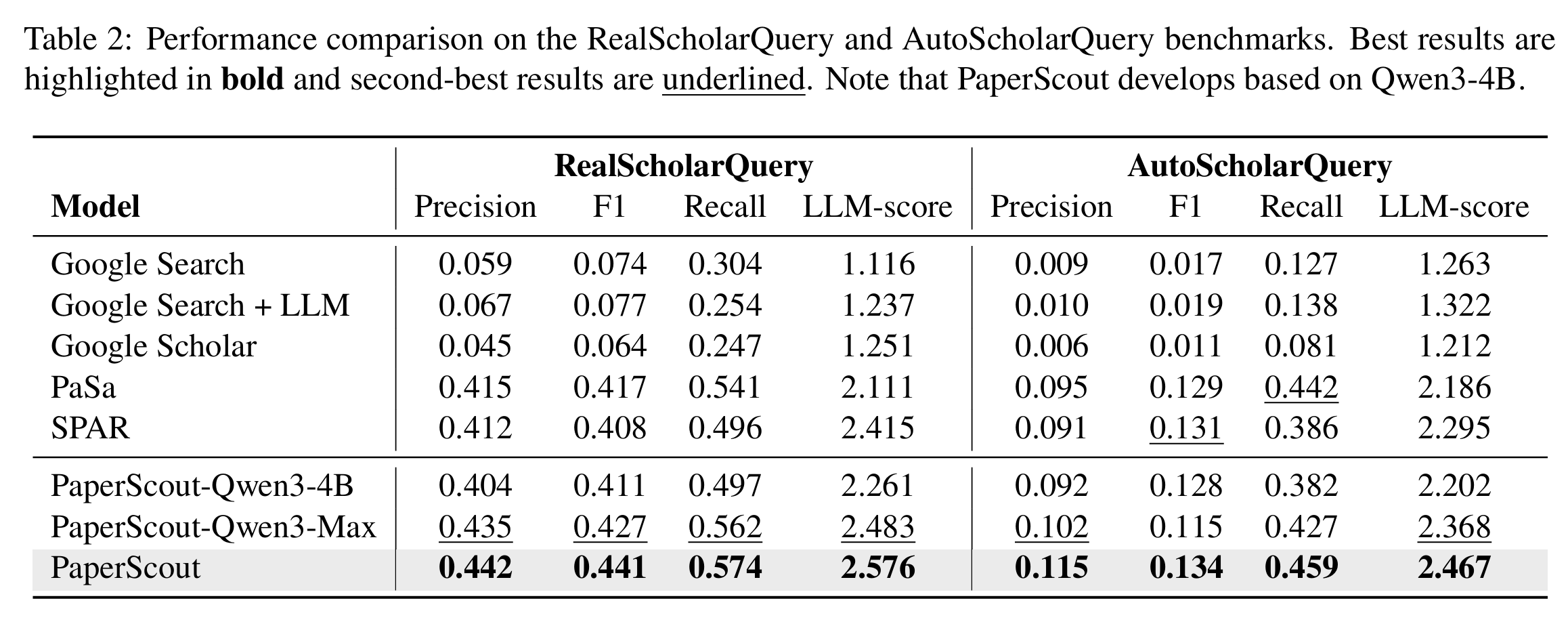
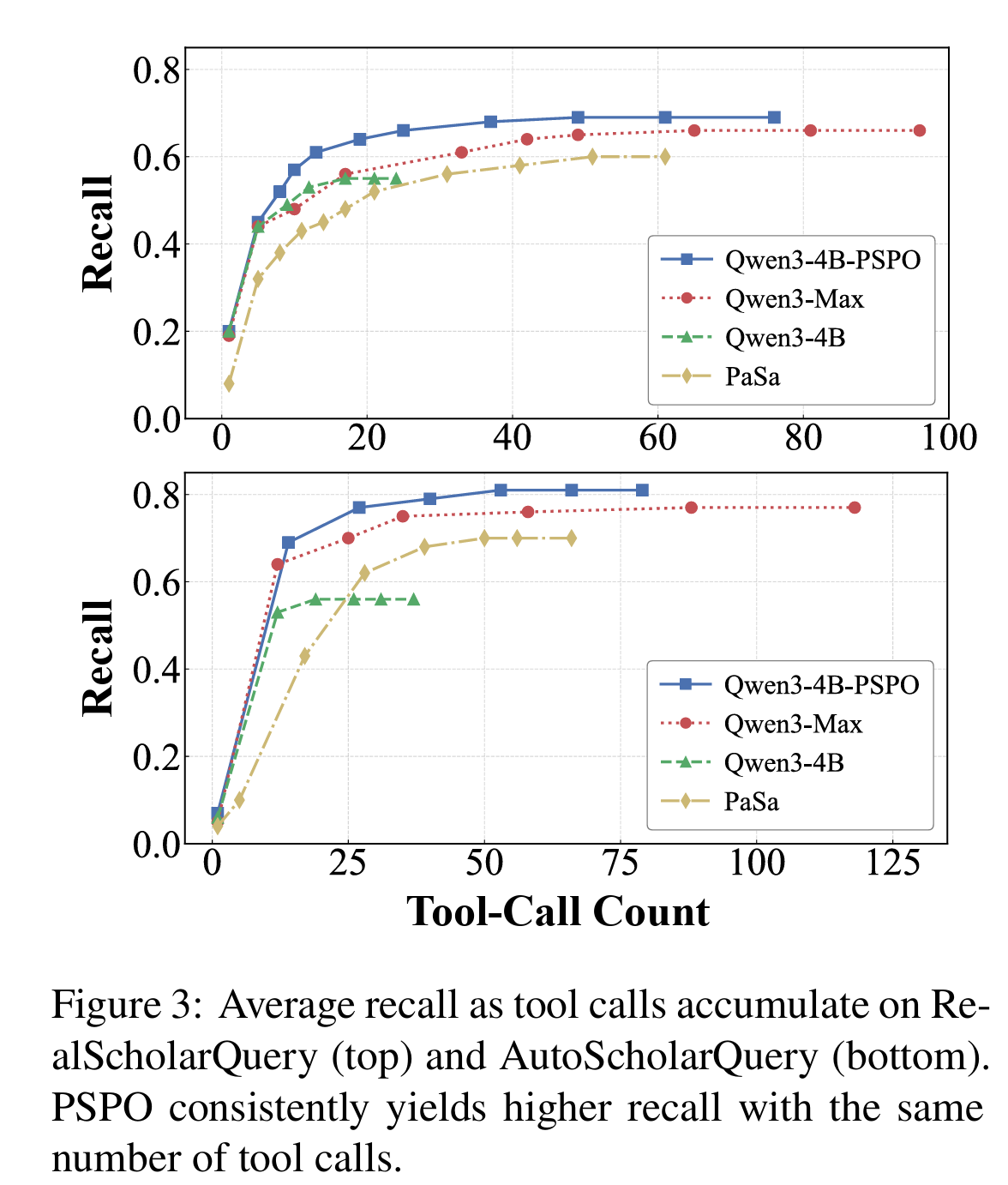
The data suggests that this more flexible approach pays off. According to Table 2 above, PaperScout consistently outperformed standard search engines and other automated tools in both finding relevant papers and maintaining high accuracy. This is not just about finding more papers, but finding the right ones. Figure 3 below shows that PaperScout achieves better recall with fewer tool calls than its competitors. It demonstrates that the agent is making smarter picks at every turn to find high-quality information without wasting resources.
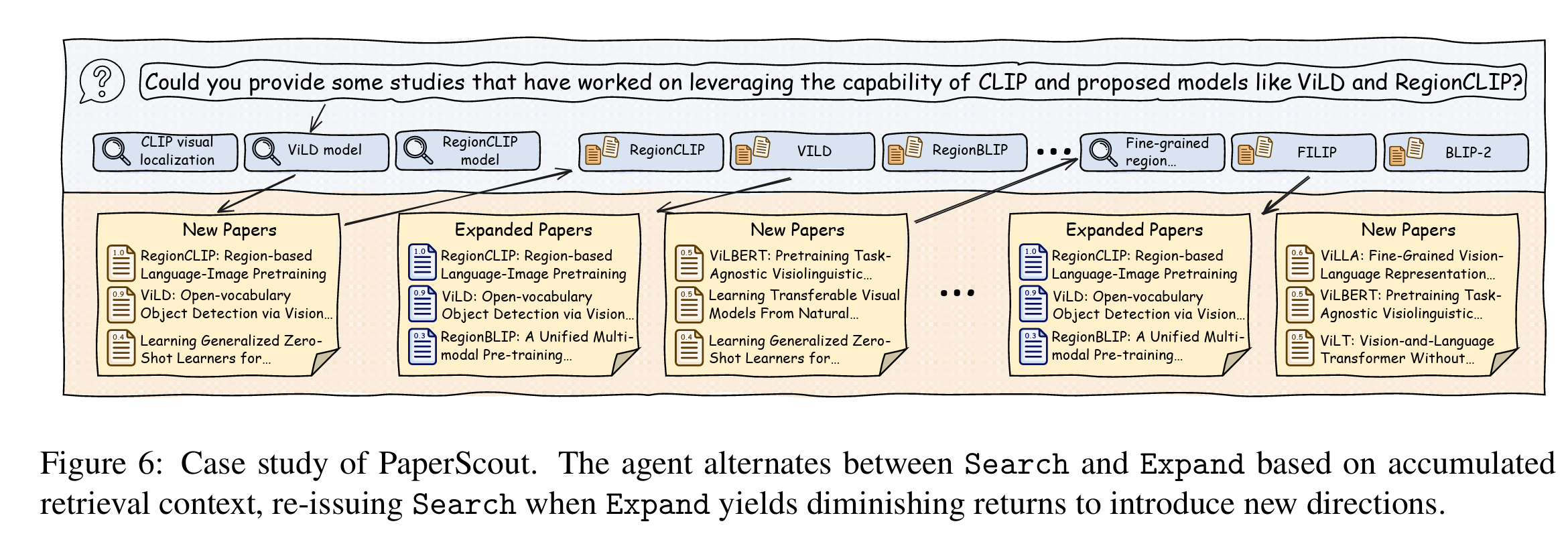
A practical ‘case study’ example in Figure 6 below shows the agent in action. Dealing with a query about specific vision models, the agent starts with several broad searches. When those initial leads become less productive, it does not just keep digging in same spot. Instead, it resets and starts a fresh search in a new direction to find missing pieces of the puzzle. This ability to switch between deep exploration and broad searching mimics how a human researcher might pivot their strategy when they hit a dead end.
In closing this musing, the paper offers a helpful step forward for anyone buried in piles of research. While the current study is mostly focused on computer science and relies on papers that are free to access, its logic is sound. It moves away from the rigid steps of old software and toward something more responsive. The strength of this work lies in how it balances the broad reaching of a search engine with the focused digging of a citation trail, all while staying steady during the learning process.