
Musing 20: Hypothesis Generation with Large Language Models
A paper out of the University of Chicago on whether LLMs can generate novel 'scientific hypotheses'

Today’s paper: Hypothesis Generation with Large Language Models. Zhou et al. 5 Apr 2024. https://arxiv.org/pdf/2404.04326.pdf
A number of my colleagues and I have always had the dream of an AI (whether or not we build it) that is able to make autonomous scientific progress that is worthy of a Nobel prize, or an equivalent. For example, can an AI discover a novel theory of economics? Be capable of proving a theorem that hasn’t been proven by a human? Prove or disprove the famous P=NP [?] conjecture in theoretical computer science?
Of course, we’re far from that at present…or are we? That’s what my brief musing today will address (I’ve kept it deliberately short and sweet, since not all readers here are scientists!). The title of the paper really says it all. It’s not claiming that an LLM can do science completely on its own, but it is looking at a particularly creative element in scientific research: the formulation of interesting hypotheses that, when investigated, will lead to novel scientific insights.
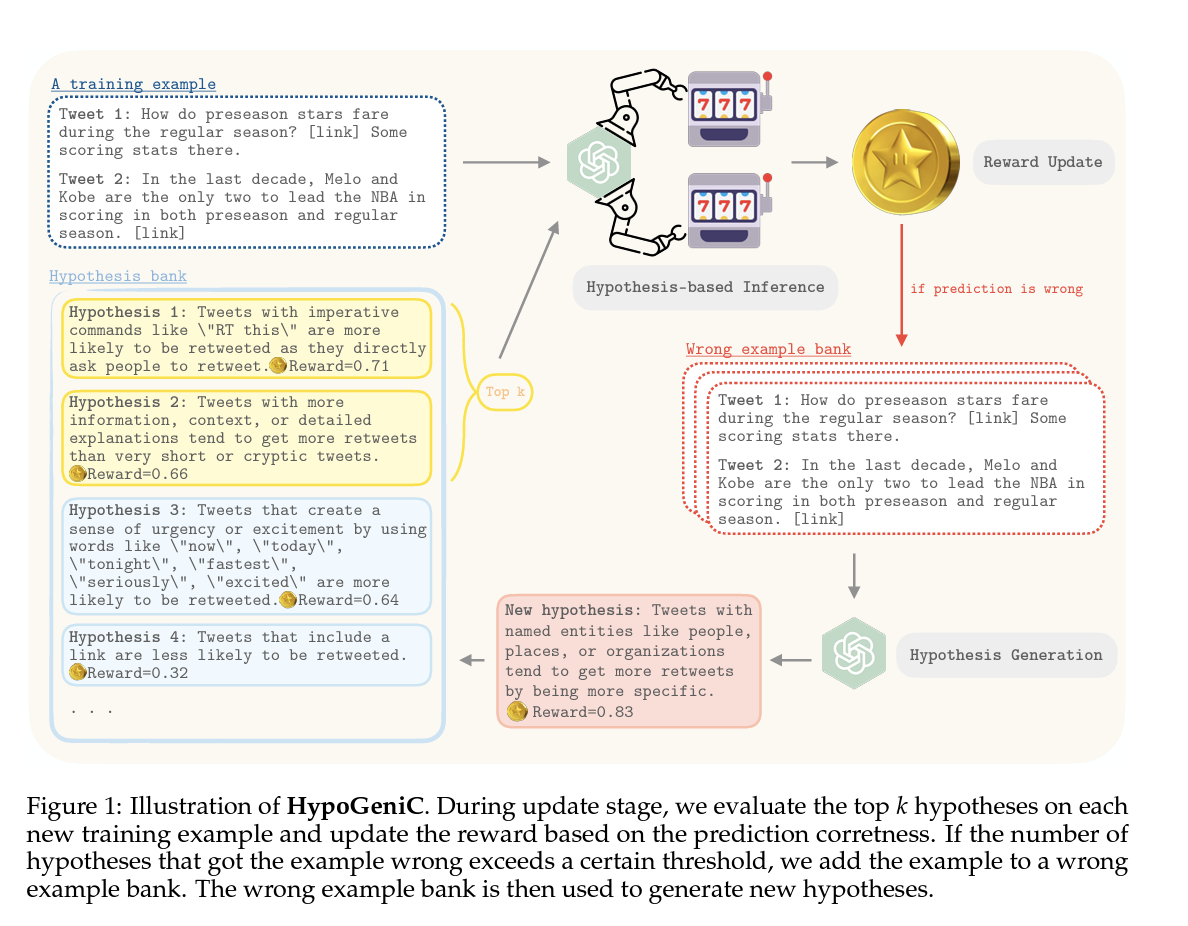
This paper specifically explores the potential of large language models (LLMs) to generate novel hypotheses, particularly focusing on data-driven hypothesis generation. The authors present a computational framework, HypoGeniC (Hypothesis Generation in Context), which iteratively generates and updates hypotheses to improve predictive performance in classification tasks. This approach is inspired by the multi-armed bandit problem, utilizing a reward function to balance exploration and exploitation during hypothesis generation. Key contributions include:
Introduction of a Novel Computational Framework: The paper proposes HypoGeniC, a novel framework for generating and evaluating hypotheses with LLMs. This method starts with generating initial hypotheses from a few examples and iteratively updates them to enhance their quality and predictive power.
Improvement Over Existing Methods: The generated hypotheses significantly outperform few-shot in-context learning and supervised learning benchmarks in both synthetic and real-world datasets. For example, accuracy improvements include 31.7% on a synthetic dataset and varying degrees (13.9%, 3.3%, and 24.9%) on three real-world datasets, demonstrating the robustness of the hypotheses across different settings.
Generation of High-Quality, Interpretable Hypotheses: The framework not only corroborates existing human-verified theories but also uncovers new insights, thereby contributing to the body of knowledge in the field. This quality ensures that the hypotheses are not only useful for improving classification performance but also valuable for advancing scientific understanding.
Cross-Generalization Capability: Hypotheses generated are not only applicable to the LLMs they were produced from but also show effectiveness when applied to other models. This indicates the general applicability of the generated hypotheses across different large language models.
Robustness Across Datasets: The generated hypotheses are shown to be robust across different datasets, including out-of-distribution sets, where they can outperform the oracle fine-tuned models like RoBERTa.
Speaking of experiments, the results are quite promising!
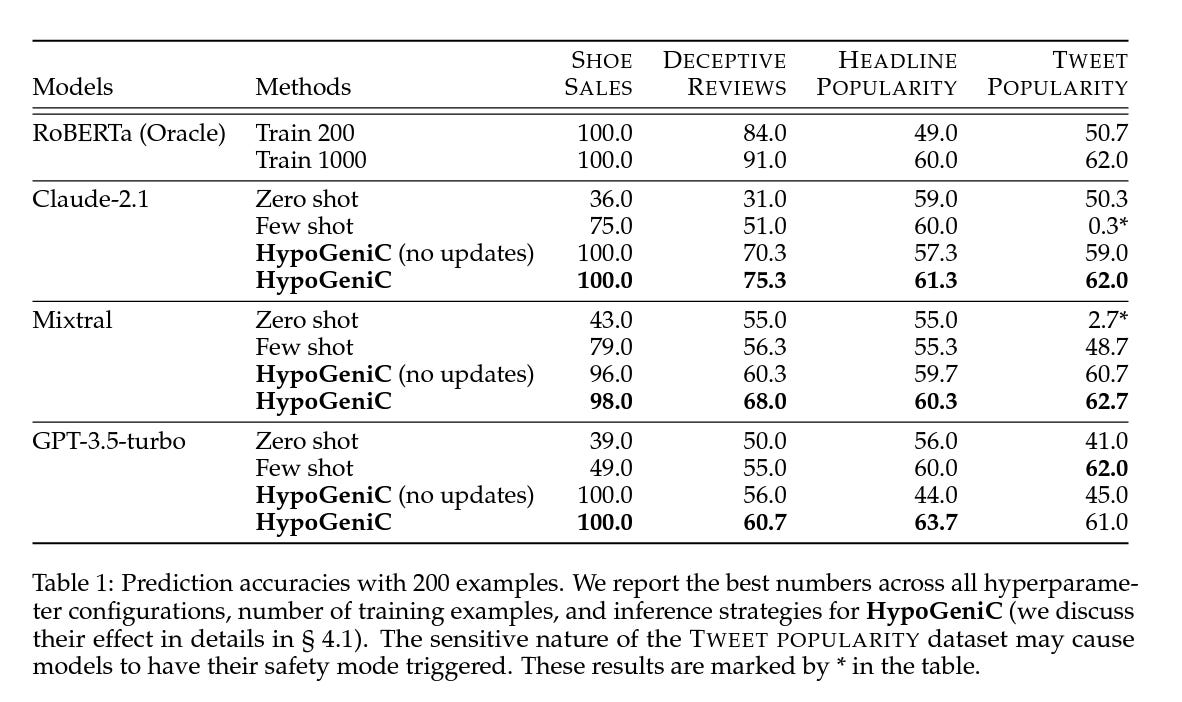
Also, the authors conduct some qualitative analysis that reveal some interesting details. On a synthetic dataset, all models were found to identify the correct hypothesis underlying something like “Shoe Sales” e.g., that "customers tend to purchase shoes that match the color of their shirts." On real-world datasets, the authors compared their generated hypotheses with those found in existing literature, confirming the validity of some while uncovering new insights that prior studies had not addressed. Examples of these hypotheses are shown in Table 4 in the main paper, with a complete list available in Appendix D. The hypotheses corroborated useful features highlighted in the literature, and the automatic evaluation of hypothesis quality also revealed negative findings. More details are provided in Section 4.3 of the paper.
Final thoughts: the paper is one of several that is probing LLM’s ability to be ‘creative.’ While we might equate that with writing poems or creating art, creativity is also required in science, through ‘interesting’ hypothesis generation. As the saying goes, identifying a good problem is half the battle in scientific research. There’s all the wild stuff we can think of, like cheap nuclear fusion, Star Trek-style replicators, and time travel. But realistically, our bread and butter as scientists is to find interesting, but relatively ‘doable’, hypotheses that we can then publish in Nature.
The LLM is not all there yet, but this paper shows that it’s getting there. Will scientists one day be out of a job too?