

Musing 32: Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust
Musing 32: Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust
A paper out of Princeton and Microsoft that was recently accepted to FACCT 2024

Today’s paper: “I’m Not Sure, But…”: Examining the Impact of Large Language Models’ Uncertainty Expression on User Reliance and Trust. Kim et al. 1 May 2024. https://arxiv.org/pdf/2405.00623
Large language models (LLMs) are transforming everyday life, with millions of people using them for tasks like searching for information, writing, and programming. However, the deployment of LLMs also poses significant risks, as they can produce outputs that are fluent and plausible but incorrect. This potential for error has led to disastrous outcomes due to overreliance, where individuals act based on false information. This issue received considerable public attention in 2023 when a lawyer mistakenly included fake judicial opinions generated by an LLM in a court document.
Such risks are a major concern for regulators who are creating new frameworks to govern AI, such as the Draft AI Act in the European Union and the NIST AI Risk Management Framework in the United States. These frameworks emphasize the need to develop methods to prevent overreliance on AI systems, a challenge that remains difficult to address as some mitigation efforts, like providing explanations, have proven ineffective or counterproductive.
To combat overreliance, the research community has suggested that LLMs and their applications should communicate the uncertainty of their outputs to users. The concept of expressing uncertainty in AI-assisted decision-making is not new and has been shown to help calibrate trust, increase vigilance, and enhance performance in these settings. However, given their broad application range, diverse user bases, and the evolving public perception, LLMs present new challenges and questions regarding their use.
To deploy LLMs responsibly, establishing best practices for expressing uncertainty is essential to fulfill the intentions of regulations like those proposed in the Draft EU AI Act. In this context, today’s paper conducts a study to examine how individuals perceive and respond to expressions of uncertainty by an LLM when using a fictional LLM-infused search engine for medical information. This scenario was chosen because the accuracy of search results is critical, particularly for high-stakes medical queries, where overreliance could pose serious risks. Furthermore, LLM-infused search engines are widely used, heightening the relevance of this study.
The focus was on natural language expressions of uncertainty for several reasons. First, such search engines already employ hedging language. Second, social science research indicates that expressing certainty or uncertainty through natural language is often preferred and seen as more intuitive than numerical expressions. Third, this method integrates uncertainty directly into the natural interactions of LLM applications, rather than relegating it to peripheral or introductory materials that users might ignore.
Inspired by the literature on uncertainty communication in both AI systems and human interactions, the study also explored how different perspectives in expressing uncertainty—comparing first-person expressions like "I’m not sure, but..." with general statements such as "It’s not clear, but..."—impact user perception and reliance.
The authors designed a between-subjects experiment with some within-subjects comparisons, which they conducted on Qualtrics. Participants complete a set of information-seeking tasks. Each task involves determining the correct yes-or-no answer to a challenging, factual question in the medical domain with or without access to responses from a fictional LLM-infused search engine, “AI system A.” The presence and form of system responses provided to participants depend on their experimental condition. Specifically, participants are randomly placed into one of four experimental conditions:
• Control: Participants see AI responses without any expression of uncertainty.
• Uncertain1st: Participants see AI responses and half of the time these responses include uncertainty expressed in the first person, with personal pronouns (e.g., “I’m not sure, but it seems...”).
• UncertainGeneral: Participants see AI responses and half of the time these responses include uncertainty expressed in a general perspective, without personal pronouns (e.g., “There is uncertainty, but it seems...”). •
No-AI: Participants are not told about the AI system and do not see AI responses.
Control is a baseline to which the conditions Uncertain1st and UncertainGeneral are compared to understand the impact of uncertainty expressions. No-AI is a second baseline to understand the impact of access to the AI system. The experiment is divided into three components. In the first, participants are introduced to the study and to AI system A (if applicable). They are given several task comprehension questions and are asked to complete an example task.
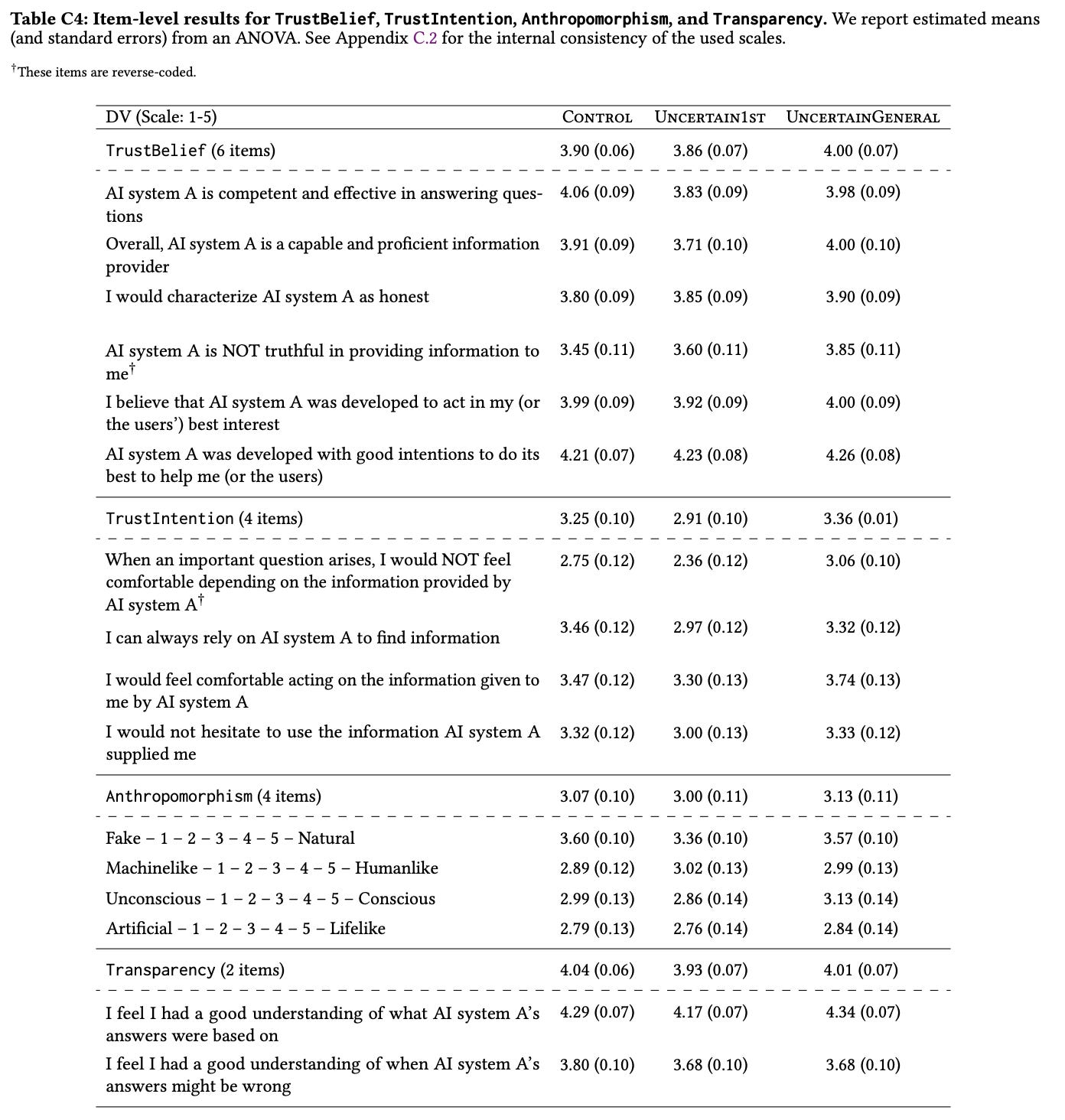
A total of 404 participants were involved, with findings indicating that certain expressions of uncertainty, particularly first-person, significantly reduced participants' overreliance on incorrect answers, thereby improving accuracy and modifying trust in the LLM's outputs. The table below was the most interpretable I could find. Compared to Control, the Uncertain numbers are higher on questions like “I would characterize the AI system as honest” and in other measures of trust and believe (4 versus 3.9).
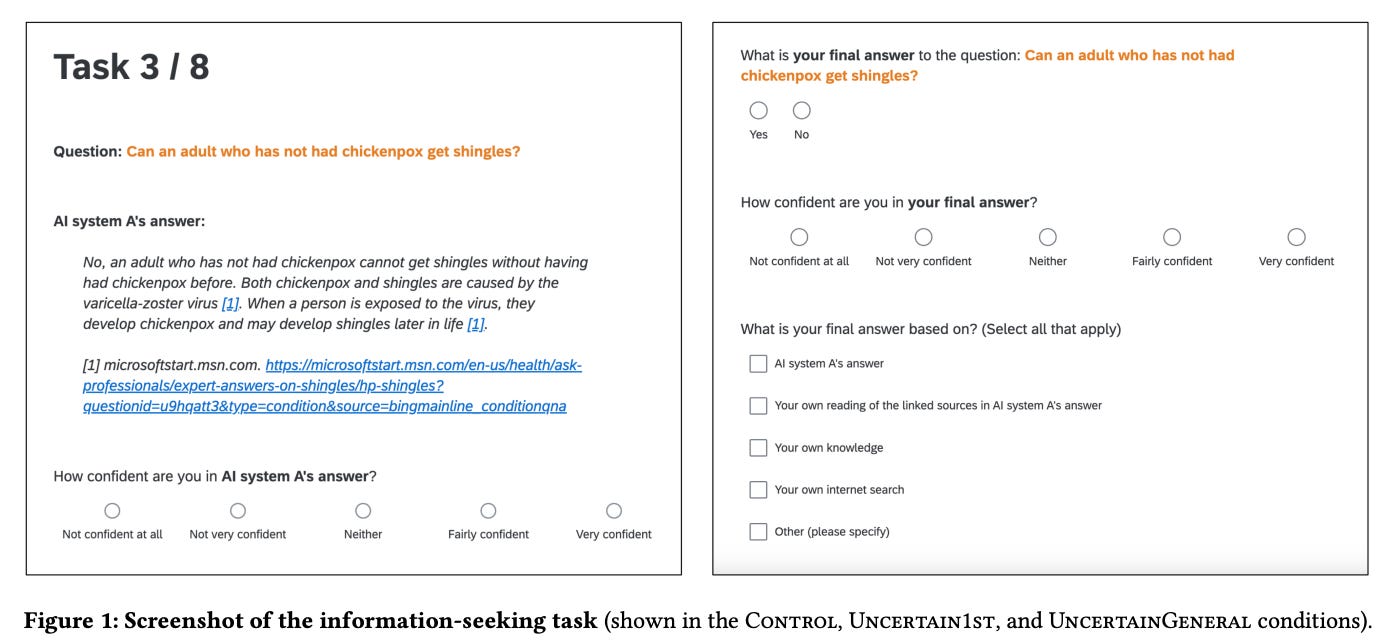
Here’s an interesting example of what’s happening here in practice, from the appendix:

My last thoughts are is that this is a most interesting study, involving real users’ participants, which is much needed today. Far too many papers are studying LLMs without seeing how users actually respond to different aspects of LLMs in action. Studying uncertainty is clearly an important step in the movement toward building responsible AI.