
Musing 34: Evaluating Large Language Models for Structured Science Summarization in the Open Research Knowledge Graph
Examining the performance of state-of-the-art LLMs in recommending research dimensions for scholarly papers.

Today’s Paper: Evaluating Large Language Models for Structured Science Summarization in the Open Research Knowledge Graph. Nechakhin et al. 3 May 2024. https://arxiv.org/pdf/2405.02105
The rapid increase in scholarly publications presents a significant challenge for researchers who aim to efficiently explore and navigate the extensive landscape of scientific literature. This surge in publications demands the development of strategies that surpass traditional keyword-based search methods to support effective and strategic reading practices. In response, the structured representation of scientific papers has become a valuable method for enhancing FAIR research discovery and comprehension. By detailing research contributions in a structured, machine-actionable format relative to key research properties or dimensions, such structured papers allow for easy comparison. This provides researchers with a systematic and quick overview of research advancements within specific domains, allowing them to stay informed about ongoing developments.
Today’s paper aims to address some of the challenges in doing so by evaluating state-of-the-art LLMs. Its key contributions include:
Comparative Analysis: It performs a detailed comparison between properties manually curated in the ORKG and those generated by state-of-the-art LLMs like GPT-3.5, Llama 2, and Mistral. This analysis provides a comprehensive evaluation from multiple angles including semantic alignment, mapping accuracy, cosine similarity via SciNCL embeddings, and expert surveys.
Methodological Development: The study pioneers a systematic approach for assessing the suitability of LLMs for structuring scientific summaries, addressing the multidisciplinary nature of scientific research and the challenges it poses in standardizing data description.
Insightful Findings: The results reveal moderate alignment between LLM-generated properties and human-annotated ORKG properties, suggesting that while LLMs have potential as recommendation systems, they require further fine-tuning to better mimic human expertise and align with scientific tasks.
Future Research Direction: It highlights the need for improved model tuning and adaptation to specific scientific domains, proposing future research pathways to refine LLM capabilities in scientific summarization.
Practical Implications: By demonstrating the utility and limitations of LLMs in this niche but critical area, the study informs ongoing efforts to enhance the efficiency and accuracy of scientific metadata curation, potentially influencing future developments in research knowledge management platforms like the ORKG.
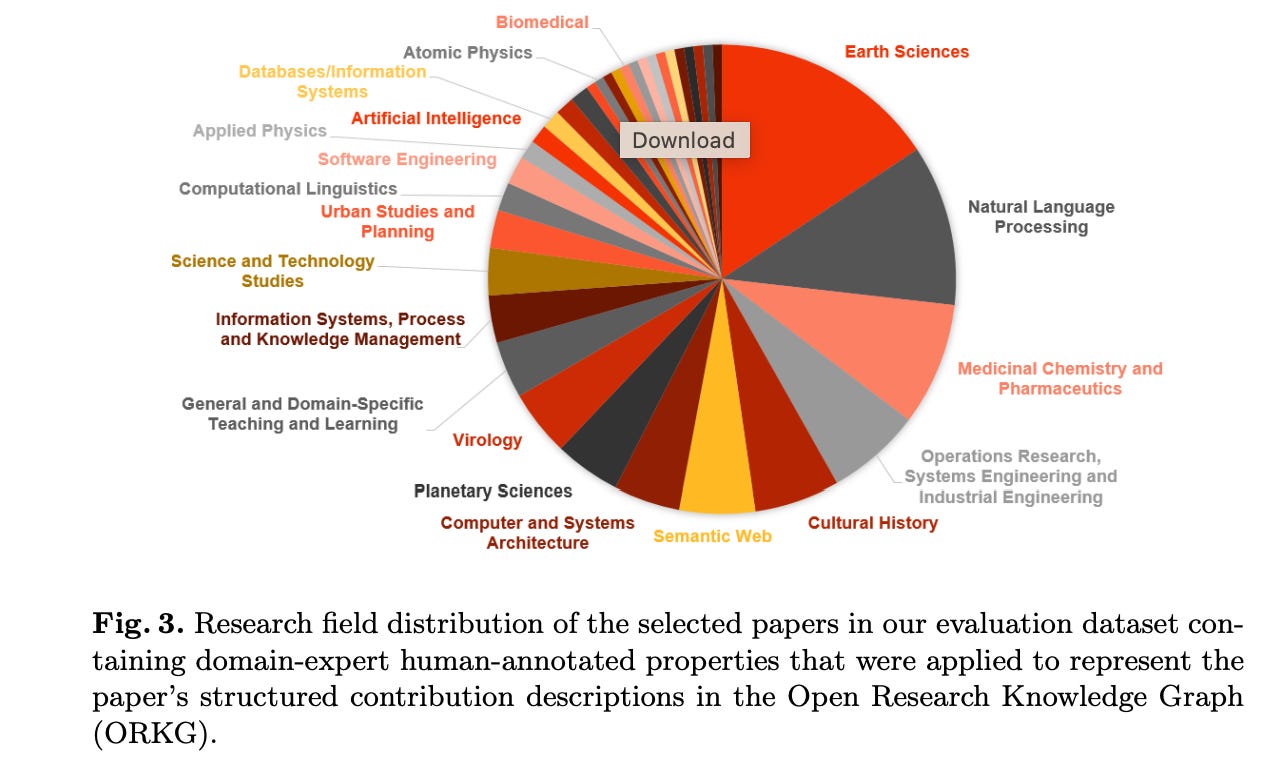
Here’s a figure showing the full distribution of research fields in the authors’ dataset, spanning fields such as Earth Sciences, Natural Language Processing, Medicinal Chemistry and Pharmaceutics, Operations Research, Systems Engineering, Cultural History, Semantic Web and others.
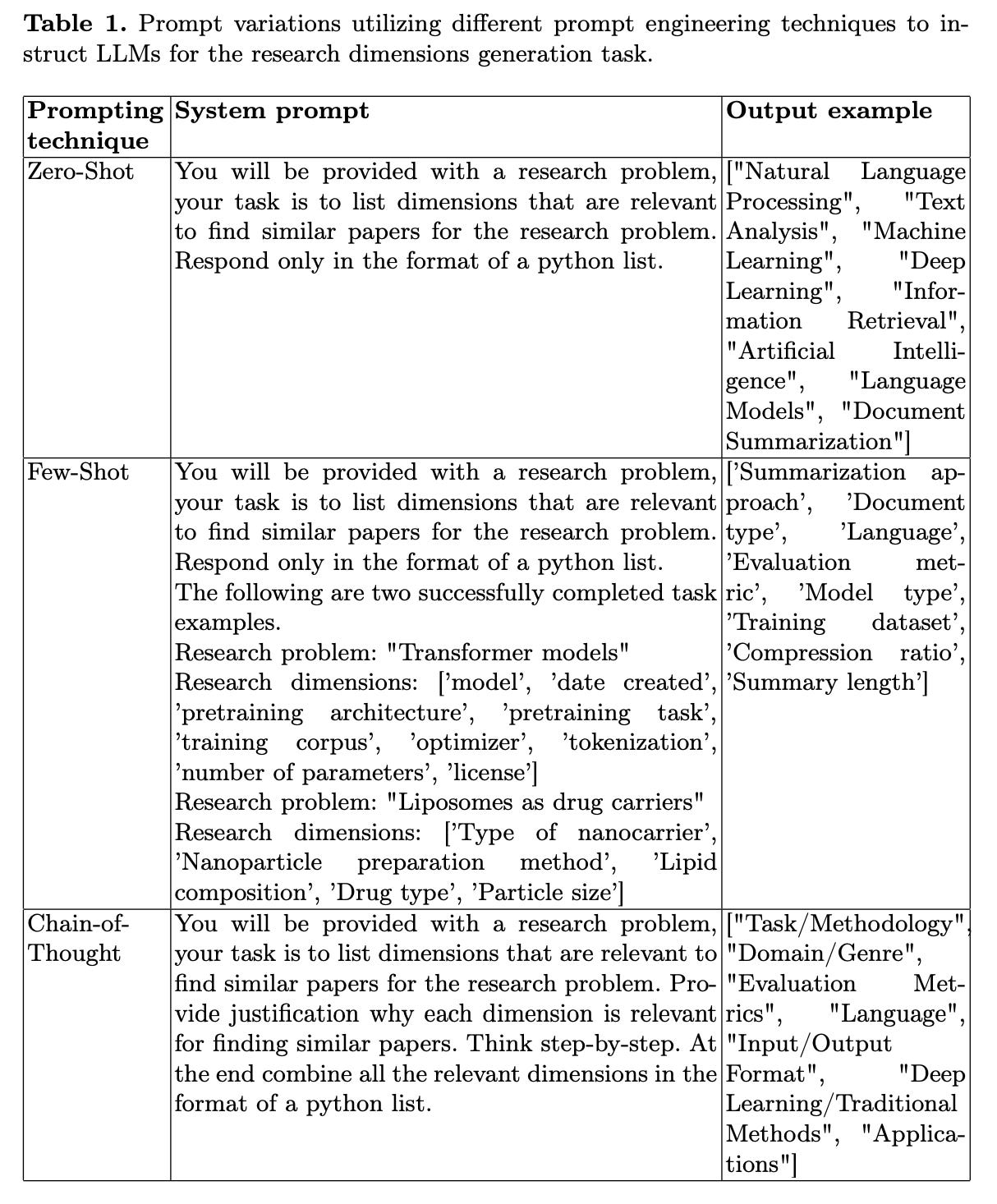
LLM’s performance on a particular task is highly dependent on the quality of the prompt. To find the optimal prompt methodology, the study explores various established prompting techniques, including zero-shot, few-shot, and chain-of-thought prompting:
The authors next conduct several experiments, but to me, the most important study was a survey that they used to evaluate the utility of LLM generated dimensions in the context of domain-expert annotated ORKG properties. The survey was designed to solicit the impressions of domain experts when shown their original annotated properties versus the research dimensions generated by GPT-3.5. The authors selected participants who are experienced at creating structured paper descriptions in the ORKG. These participants included ORKG curation grant participants, ORKG employees, and authors whose comparisons were displayed on the ORKG featured comparisons page. Each participant was given a maximum of 5 surveys, for five different papers they structured respectively, each evaluating properties versus research dimensions. They had the choice to respond to one, some, or all of them. In the end, 23 total responses to the survey were received, corresponding to 23 different papers. The survey itself consisted of five questions, most of which were designed on a Likert scale, to gauge the domain expert assessment of the effectiveness of the LLM-generated research dimensions:
1. How many of the properties generated by ChatGPT are relevant to your ORKG structured contribution? (Your answer should be a number)
2. Considering the ChatGPT-generated content, would you consider making edits to your original ORKG structured contribution?
3. If the ChatGPT-generated content were available to you as suggestions before you created your structured contribution, would it have been helpful?
(a) If you answered "Yes" to the question above, could you describe how it would have been helpful?
4. On a scale of 1 to 5, please rate how well the ChatGPT-generated response aligns with your ORKG structured contribution.
5. We plan to release an AI-powered feature to support users in creating their ORKG contributions with automated suggestions. In this context, please share any additional comments or thoughts you have regarding the given ChatGPT-generated structured contribution and its relevance to your ORKG contribution.
For the first four questions, the results are as follows:
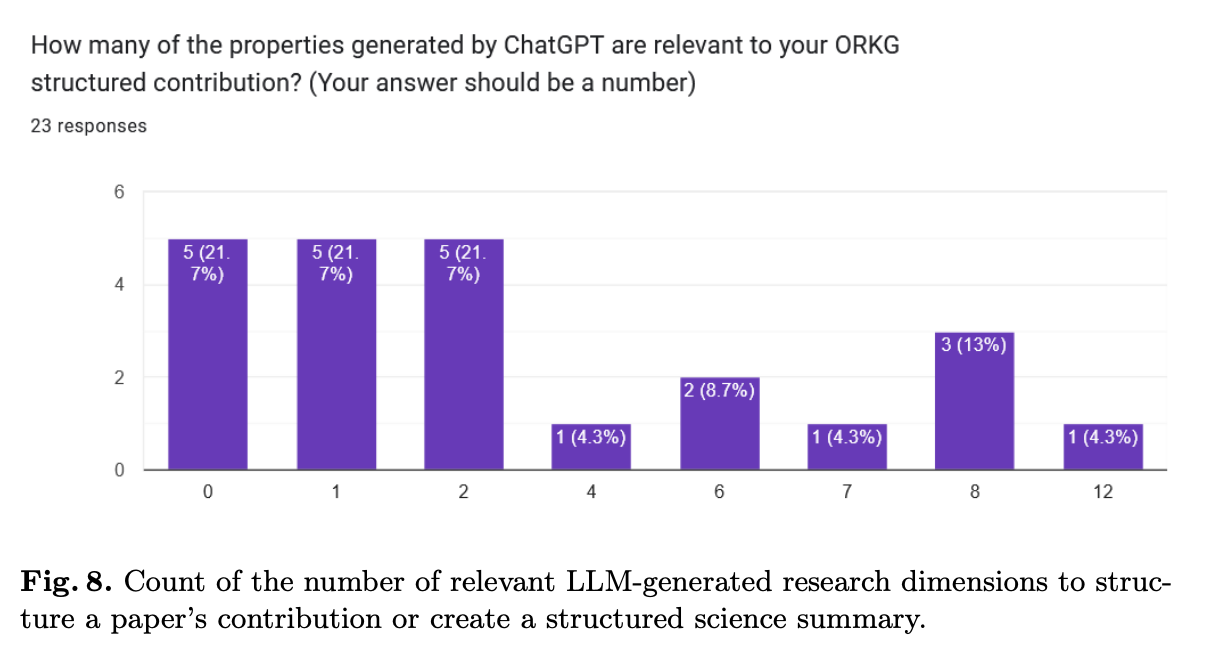
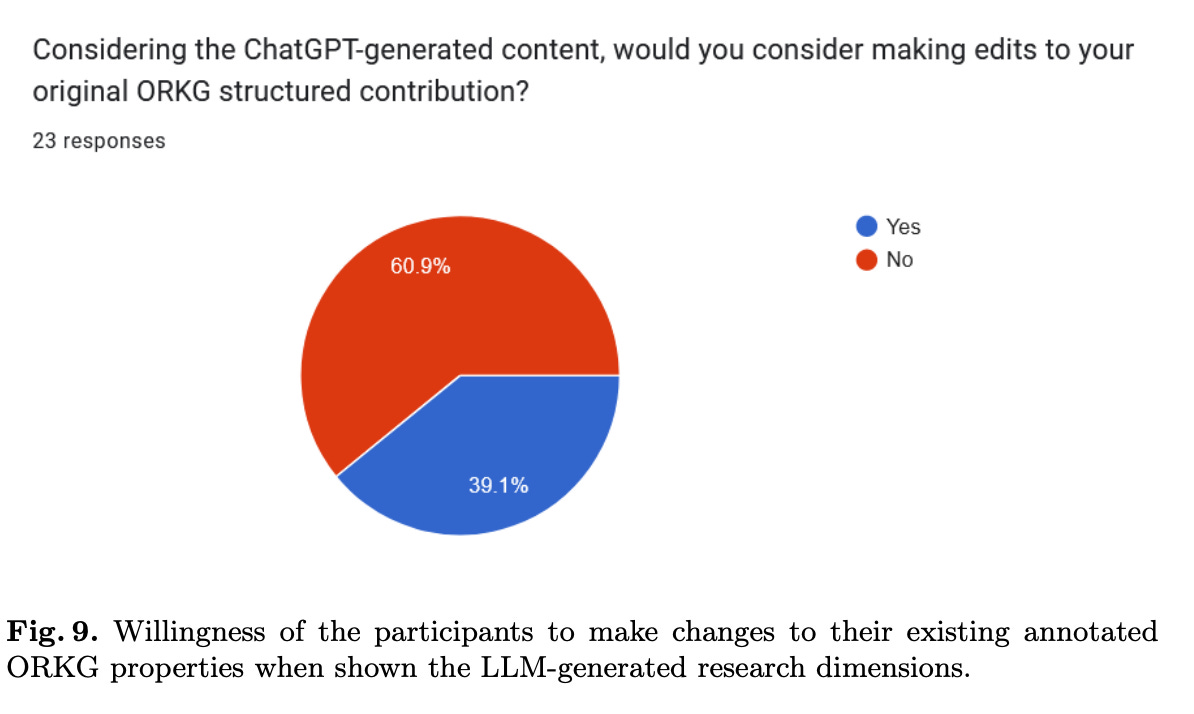
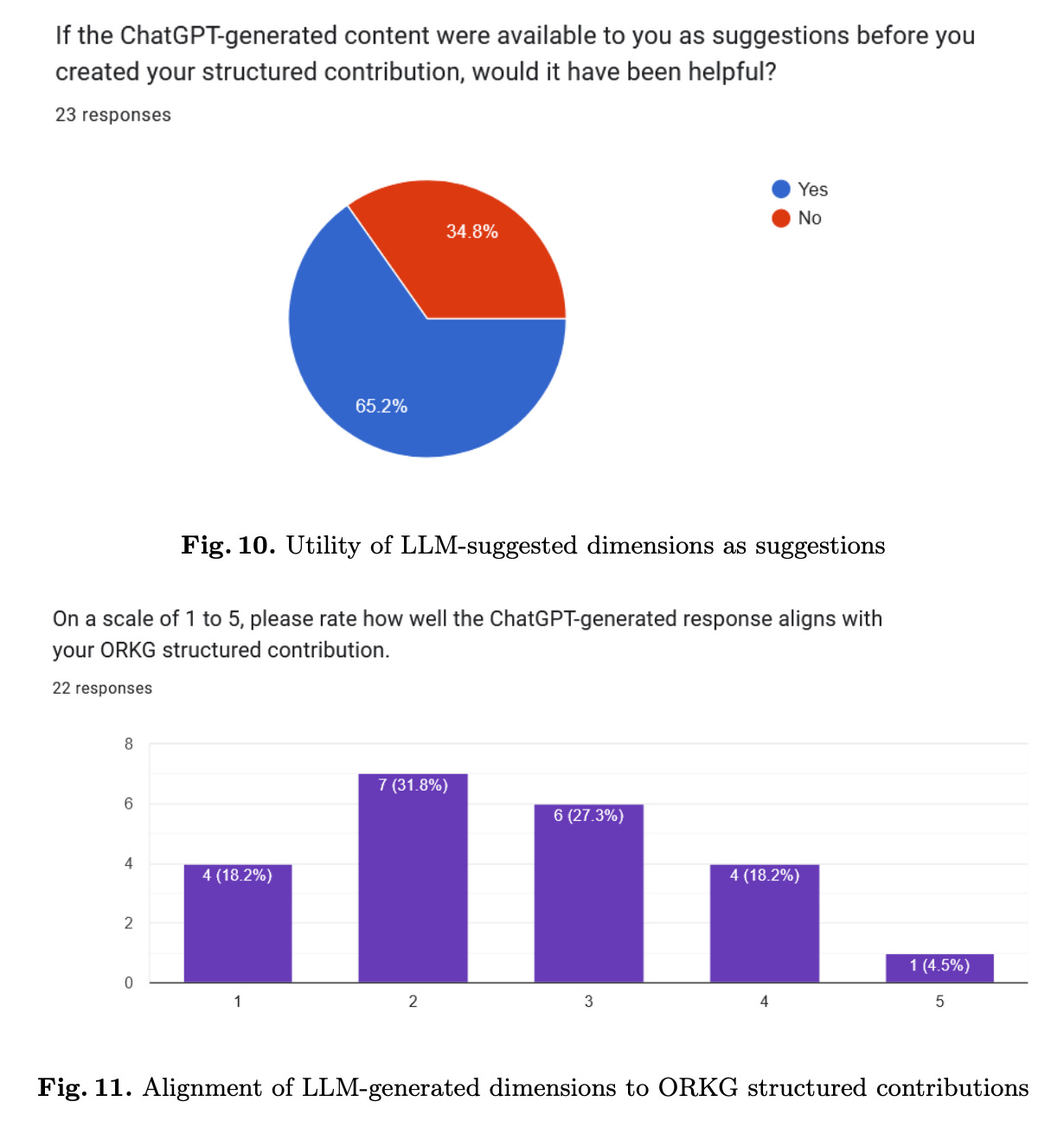
Although the sample size is too small for definitive conclusions, the results are promising. The findings of the survey indicate that LLM-generated dimensions exhibited a moderate alignment with manually extracted properties. Although the generated properties did not perfectly align with the original contributions, they still provided valuable suggestions that authors found potentially helpful in various aspects of creating structured contributions for ORKG. For instance, the suggestions were deemed useful in facilitating the creation of comparisons, identifying relevant properties, and providing a starting point for further refinement. However, concerns regarding the specificity and alignment of the generated properties with research goals were noted, suggesting areas for further refinement.
The paper is long but simple. My final musing is that LLMs do show promise as tools for automated research metadata creation and the retrieval of related work, but further development is necessary to enhance their accuracy and relevance in this domain. Science remains hard.