
Musing 44: Explainable Few-shot Knowledge Tracing
A paper out of Tsinghua and Beihang University
Today’s paper: Explainable Few-shot Knowledge Tracing. Li et al. 23 May 2024. https://arxiv.org/pdf/2405.14391
Knowledge tracing (KT) is a well-established problem originated from educational assessment aiming to dynamically model students’ knowledge mastery and predict their future learning performance. With the advancement of deep learning, models using recurrent neural networks (RNNs) and attention mechanisms have gradually become mainstream for knowledge tracing.
So what is KT? It is a technique that aims to track the performance of a learner on specific educational content and using this data to forecast their future learning behaviors and outcomes. Here’s a breakdown of its main components and functions:
Modeling Student Learning: KT uses mathematical or statistical models to represent the process of learning. The most traditional form is the Bayesian Knowledge Tracing (BKT) model, which estimates the probability that a learner has mastered a skill based on their performance over time.
Dynamic Prediction: As new data (e.g., answers to quiz questions) becomes available, the model updates its estimates of a student's knowledge state. This allows for dynamic predictions about a student's current level of understanding and their ability to handle future material.
Personalized Learning Paths: By understanding where a student stands in terms of skill mastery, educators can tailor the learning experience. For example, if a student is struggling with a particular concept, the system might provide additional resources or exercises to help them improve.
Feedback Loop: KT also involves a feedback loop between learners and educational content providers. This helps in adjusting the instructional strategies and content based on individual learning needs and performance patterns.
Despite the numerous attempts and decent success, current KT using AI leaves gaps in reflecting real-world scenarios where teachers evaluate students’ knowledge states. On the one hand, it relies on extensive student exercise records to train deep learning knowledge tracing models to achieve remarkable performance. In contrast, in real teaching scenarios, teachers can analyze students’ mastery of knowledge from a limited number of practices.
Today’s paper introduces an approach for explainable few-shot knowledge tracing which takes a small number of informative student exercise records as input, tracks students’ mastery of knowledge, and predicts future performances through reasoning while providing reasonable explanations.
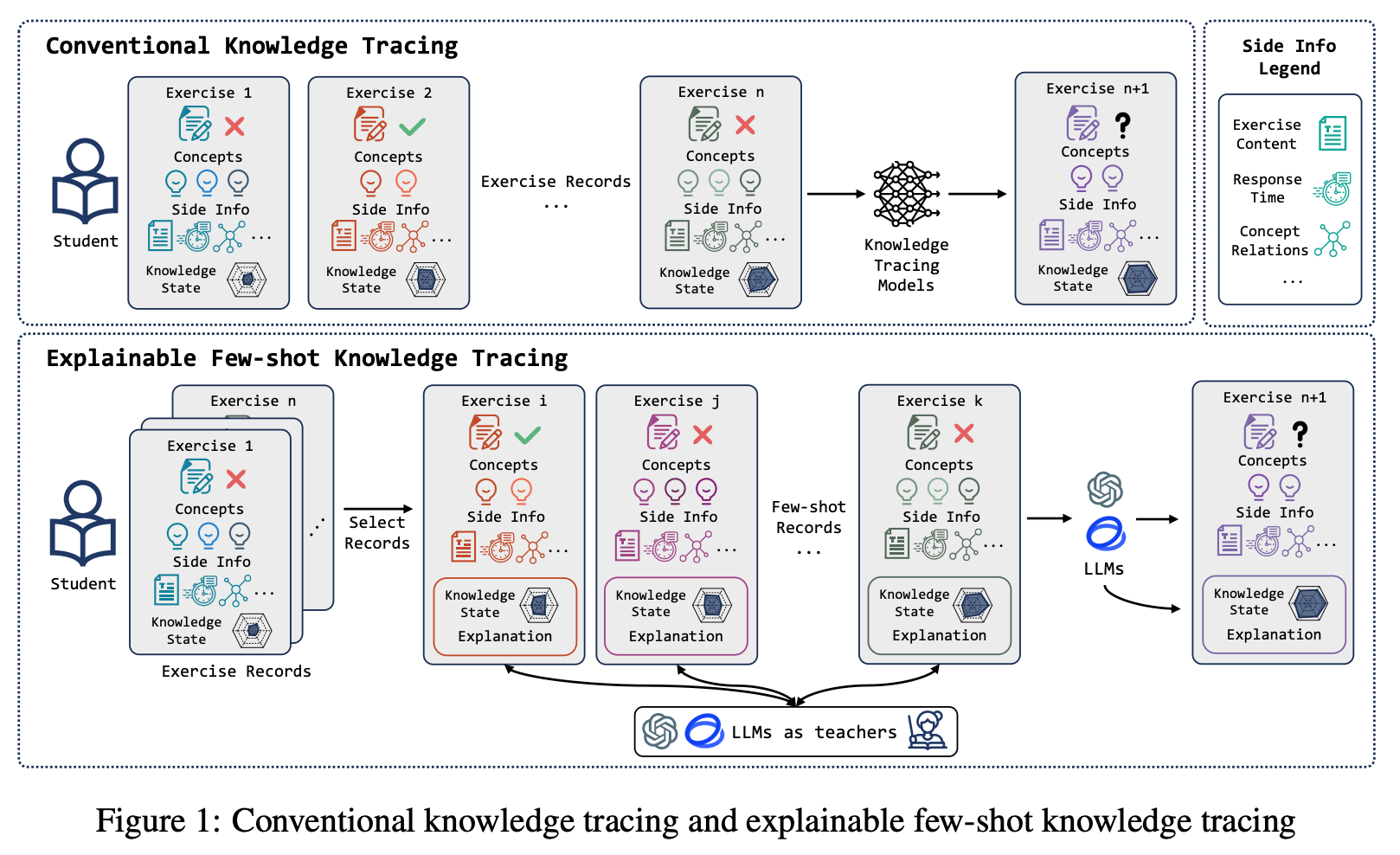
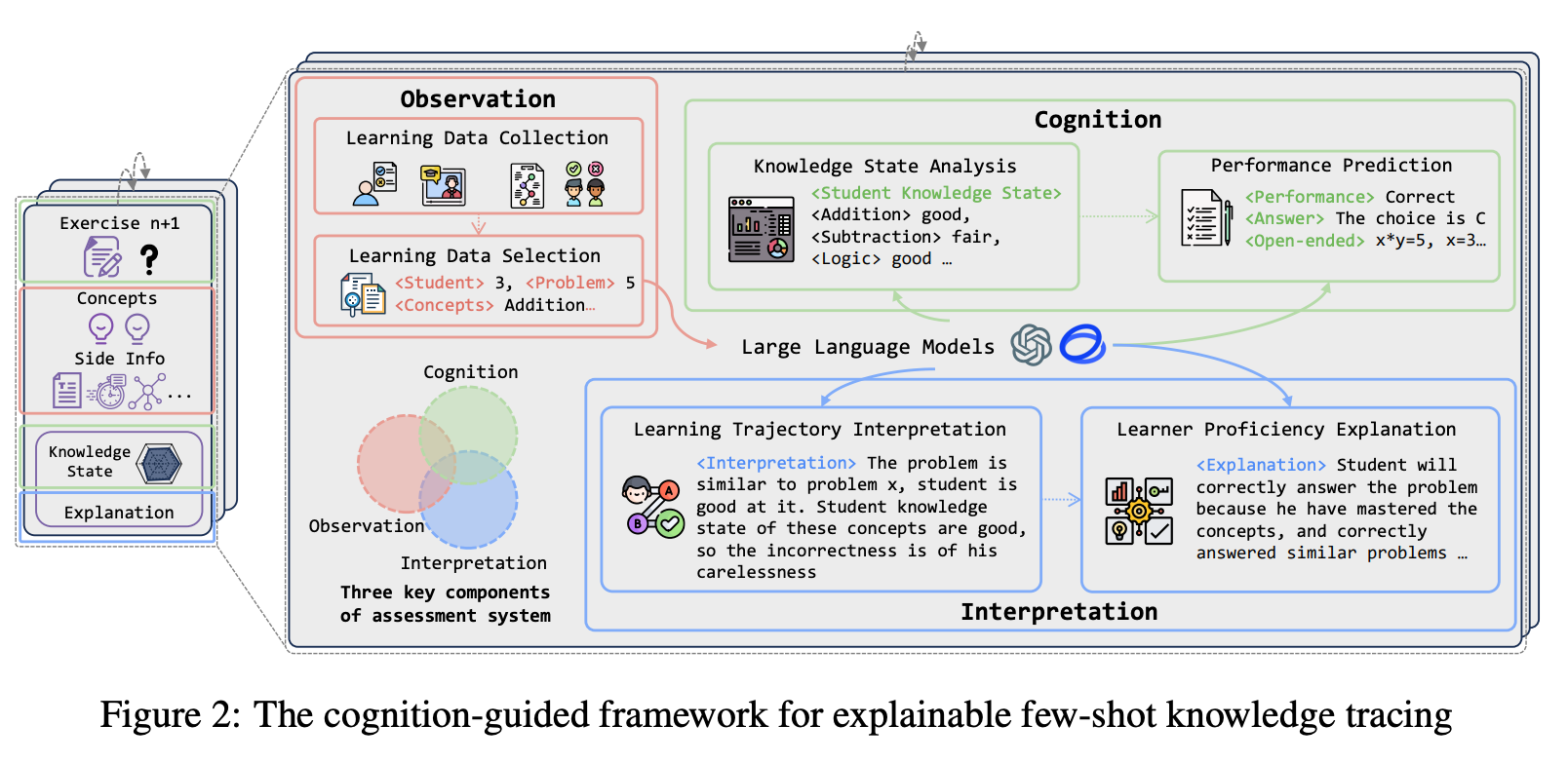
Specifically, the authors introduce a cognition-guided framework that combines large language models and educational assessment principles to practice explainable few-shot knowledge tracing. An architectural overview is provided below:
The authors selected three public datasets for evaluation: FrcSub2 , MOOCRadar, and XES3G5M. They collect accuracy, precision, recall, and F1 scores as evaluation metrics, as the area under the curve (AUC) cannot be employed since LLMs provide binary predictions. They select several commonly employed and competitive baselines in knowledge tracing:
DKT employs LSTM layers to encode the students’ knowledge state and predict their performance on exercises.
DKVMN designs a static key matrix to capture relations between knowledge components and a dynamic value matrix to track the evolution of students’ knowledge.
GKT leverages graph structure to model interactions between exercises.
AKT utilizes an attention mechanism to characterize the temporal distance between questions and the student’s history interactions.
SAKT incorporates a self-attention module to capture latent relations between exercises and student responses.
SAINT adopts a transformer architecture to jointly model sequences of exercises and responses.
The authors compared the best performance of GLM3-6B, GLM4, and GPT-4 across all modes of three datasets with considered baselines. Notably, all considered baselines requires the full training set to achieve best performances, whereas their approach only require a few, and such a small amount is far from enough for the baselines. The best three metrics in each column are marked using bold, underlined, and italics.
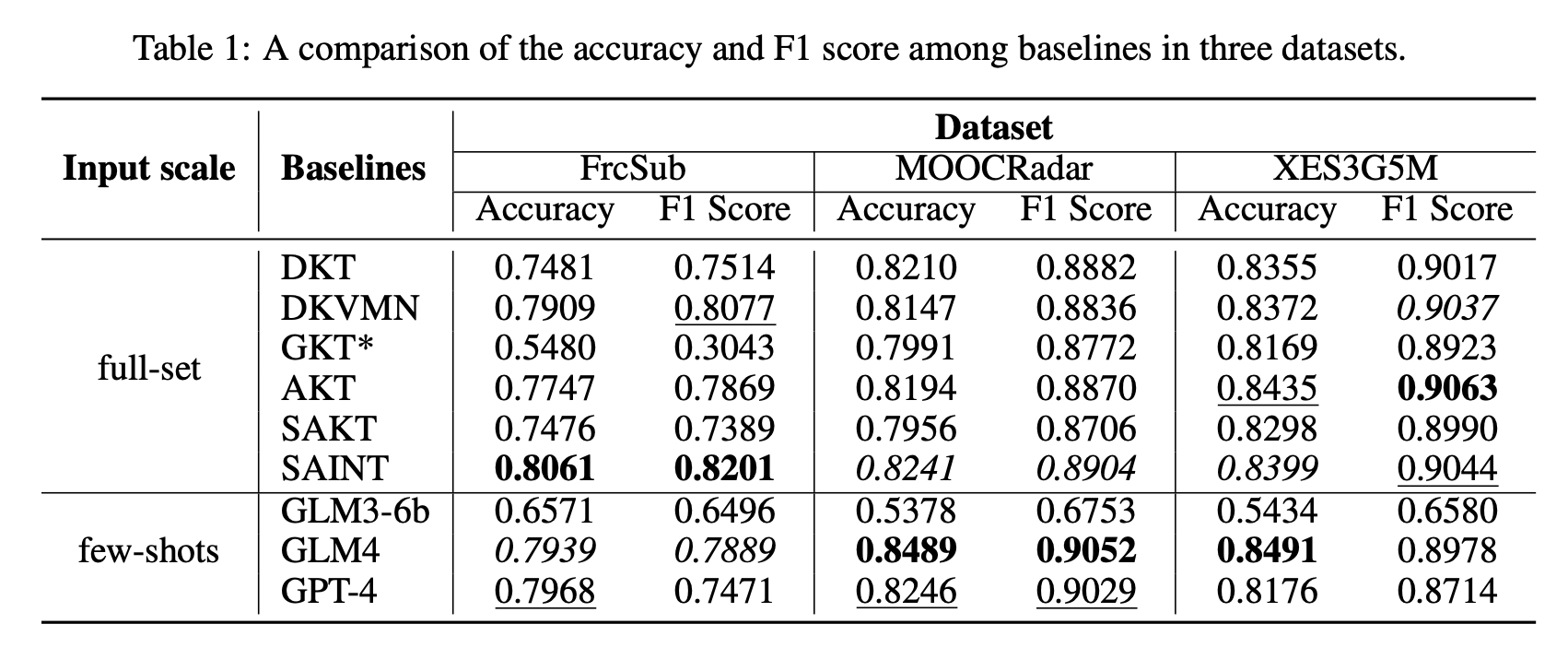
Notably, GLM3-6B did not perform as well as expected, which could be attributed to the extensive input context. During experiments, the authors observed that the GLM3-6B often struggled to follow instructions, indicating that a fine-tuned small model may potentially achieve better performance.
For a case study, the authors randomly select examples of all considered LLMs from the MOOCRadar-moderate. It involves estimating the student’s knowledge state in student history records, predicting student performances, and providing an explanation.

GLM4 & GPT-4 Illustrated in the figure above, the authors highlighted the differences between the outputs of GLM4 and GPT-4 in gray. They observed that both models are able to follow the instructions and generate formatted explanations in most cases. Differences occurs where GPT-4 incorrectly assumed the student had answered Exercise 24 incorrectly and provided an explanation for this assumption. Furthermore, when explaining its prediction, GPT-4 failed to recognize the incorrectness of the student’s performance and instead offered an explanation suggesting the student had answered correctly. This issue was also present in some cases for GLM4, possibly due to the models’ limited context window to accurately identify such shot and specific information.
In closing, the authors formulated the explainable few-shot knowledge tracing task to fill the gap between the conventional knowledge tracing task and real teaching scenarios and proposed a cognition-guided framework to conduct this task. They demonstrate that LLMs can achieve comparable or superior performances to competitive baselines in conventional knowledge tracing while providing more natural language explanations under the proposed framework.
The paper was written clearly, and I was especially impressed with the discussion and case study sections. The authors do highlight some findings in the discussion section that may apply beyond this paper and the specific application of KT that they are looking at.