


Musing 46: LLMs achieve adult human performance on higher-order theory of mind tasks
A paper out of Google Research, DeepMind, University of Oxford and Johns Hopkins

Today’s paper: LLMs achieve adult human performance on higher-order theory of mind tasks. Street et al. 29 May 2024. https://arxiv.org/pdf/2405.18870
Theory of Mind (ToM) is the cognitive ability to attribute mental states—like beliefs, intents, desires, emotions, and knowledge—to oneself and others, and to understand that others have beliefs, desires, and intentions that are different from one's own. This concept is crucial for everyday human social interactions as it enables a person to predict and interpret the behavior of others.
LLMs have been argued to exhibit some ToM competency but much of the literature on LLM ToM has focused on 2nd-order ToM, where the ‘order of intentionality’ (hereafter, ‘order’) is the number of mental states involved in a ToM reasoning process (i.e. a third-order statement is “I think you believe that she knows”). Yet LLMs are increasingly used for multi-party social interaction contexts which require them to engage in higher order ToM reasoning. This is what today’s paper addresses.
The authors examine LLM ToM from orders 2-6. They introduce a novel benchmark: Multi-Order Theory of Mind Question & Answer (MoToMQA). MoToMQA is based on a ToM test designed for human adults, and involves answering true/false questions about characters in short-form stories. They assess how ToM order affects LLM performance, how LLM performance compares to human performance, and how LLM performance on ToM tasks compares to performance on factual tasks of equivalent syntactic complexity. They then show that GPT-4 and Flan-PaLM reach at-human or near-human performance on ToM tasks respectively (see below).
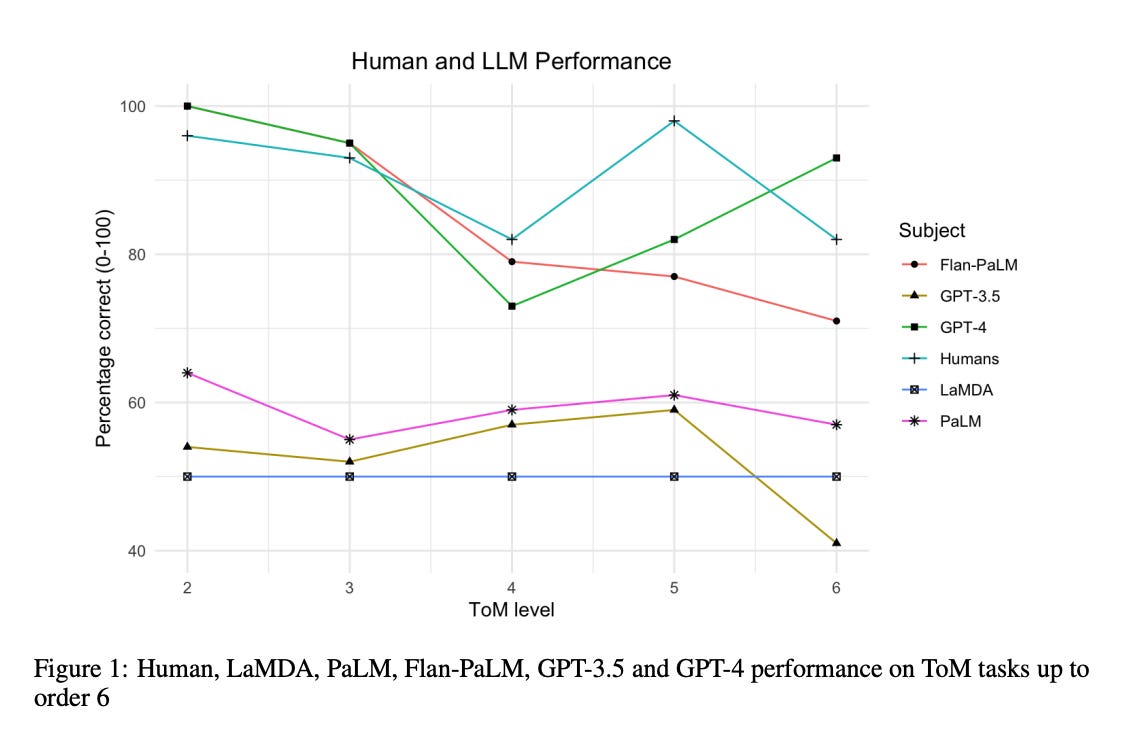
A large part of the paper is focused on the human creation of the ToM benchmark that the authors use for the study. I’m not reproducing those details here, but it’s a fascinating read in itself. Instead, I’m jumping straight to the results and what the authors found. The table below provides details on how the different models perform.
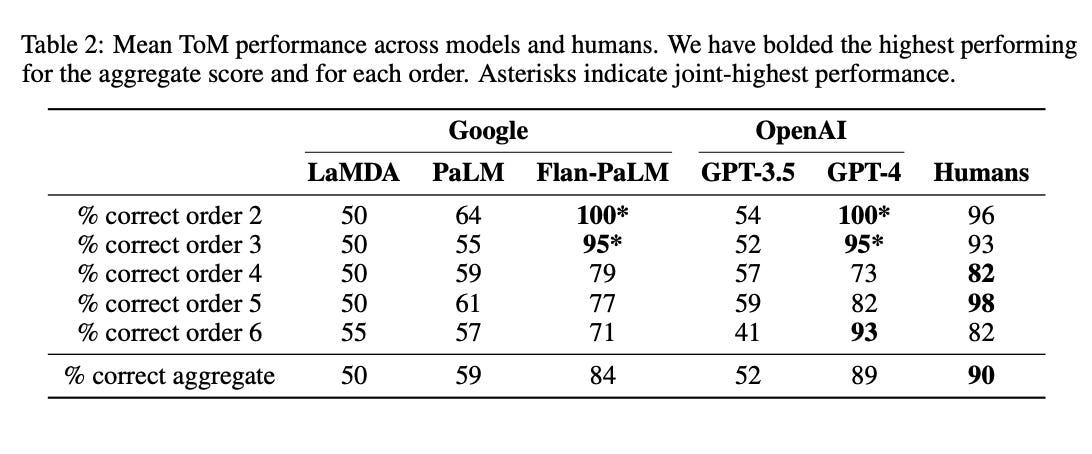
According to these results, GPT-4 and Flan-PaLM performed strongly on MoToMQA compared to humans. At all levels besides 5, the performance of these models was not significantly different from human performance, and GPT-4 exceeded human performance on the 6th-order ToM task. Because GPT-4 and Flan-PaLM were the two largest models tested, with an estimated 1.7T and 540B parameters, respectively, the data shows a positive relationship between increased model size and ToM capacities in LLMs. This could be a result of well-known “scaling laws”, which dictate a breakpoint in size after which models have the potential for ToM.
GPT-4 achieved 93% accuracy on 6th order tasks compared to humans’ 82% accuracy. Because this seems to lack external validity on its surface (for anyone who has used GPT-4 a lot), the authors try to explain this as “the recursive syntax of 6th order statements creates a cognitive load for humans that does not affect GPT-4.”
In closing, I think the real (between the lines) message from the paper is not LLMs have ToM, which in all honesty, even the authors are unlikely to fully claim, but the problem with such tests in the first place. In my own research, I have seen a similar problem in the area of machine common sense. If LLMs are answering common sense questions correctly, is this definitive proof that they have common sense? Or do we need to design significantly richer tests that don’t look like the SAT? I think this paper provokes similar questions.