


Musing 50: Towards a Personal Health Large Language Model
A paper out of Google

Today’s paper: Towards a Personal Health Large Language Model. Cosentino et al. 11 June 2024. https://arxiv.org/pdf/2406.06474
LLMs have the potential to revolutionize health, and Google is one of the Big Tech giants investing deeply in this space. Today’s paper introduces the Personal Health Large Language Model (PH-LLM) as a specialized version of Gemini, which has been improved to generate insights and recommendations for improving personal health behaviors related to sleep and fitness patterns. The authors assess the model’s effectiveness through three tasks: coaching recommendations, multiple-choice exams testing expert knowledge, and prediction of subjective patient-reported outcomes (PROs).
The coaching recommendation tasks, focused specifically on sleep and fitness, utilize individual sleep metrics to offer insights, identify potential etiological factors, and provide customized advice to enhance sleep quality. The fitness tasks incorporate data from training load, sleep, health metrics, and subjective feedback to tailor daily recommendations for physical activity intensity. To benchmark LLM performance in personal health behavior understanding and reasoning, a unique personal health case study dataset is created, comprising long-form questions based on summarized personal health behavior data, vertical-specific evaluation rubrics, and expert human responses for 857 case studies within the sleep and fitness domains.
Through human and automated evaluations, the authors show that Gemini Ultra 1.0 nearly matches expert performance in fitness tasks, while the fine-tuning of PH-LLM helps to close the performance gap with experts in sleep coaching. Additionally, the model explores the extent of personal health knowledge embedded in Gemini models and uses multimodal capabilities for predicting PROs in sleep.
The paper is a long one with lots of details, and it’s not worth covering all of that here in a long musing. I’ll focus instead on what I believe are the key innovations. Let’s start with the architecture below. As shown, the model is fine-tuned from Gemini for applications in personal health, capable of performing interpretation of time-series sensor data from wearables (i.e., Fitbit and Pixel Watch) for analysis and recommendations in sleep and fitness.

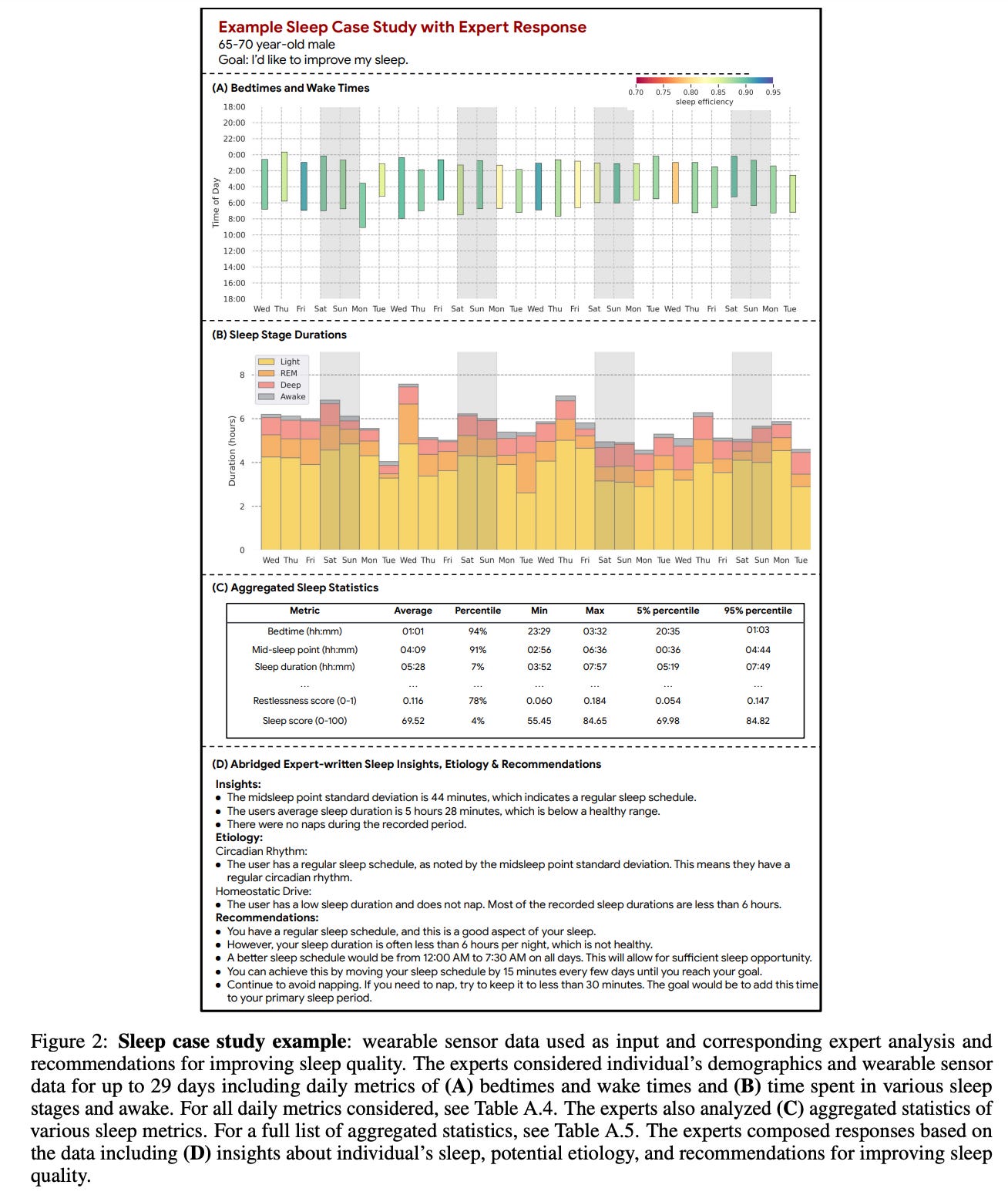
Another innovation is the sleep case studies, where the authors recruited six domain experts in sleep medicine to craft guidance in the second person narrative, fostering a direct and personalized dialogue with the user. The six sleep experts all possessed advanced degrees (M.D., D.O., or Psy.D.) in sleep medicine and professional sleep medicine work experience ranging from 4 to 46 years. All experts were trained to read and interpret wearable data and map outputs to their corresponding sleep medicine literature counterparts. Experts were instructed to use best practices in goal-setting, emphasizing the creation of recommendations that are Specific, Measurable, Achievable, Relevant, and Time-bound (SMART). The data was sampled to achieve a representative group across age and gender. As illustrated below, demographics information (age and gender), daily sleep metrics (e.g., bedtimes, wake times, and sleep stage durations), and aggregated sleep statistics (e.g., average bedtime) were selected collaboratively with the experts:
For the model, the authors fine-tuned Gemini Ultra 1.0 on the dataset of coaching recommendations and called it PH-LLM. They use the case studies from the training, validation, and test sets for model training and selection (457 case studies for sleep and 300 case studies for fitness). For each of the sleep and fitness domains, they randomly split the dataset into separate training, validation, and test splits using a 70:15:15 ratio. They used the same prompts that were given to the baseline model to form prompt-response pairs for model tuning. Since each section was treated as a separate example, this resulted in 1,371 prompt-response pairs for sleep and 1,500 prompt-response pairs for fitness across the training, validation, and test sets.
This is also one of the rare CS papers where, following the study, the authors performed semi-structured 30-minute interviews with the experts who participated in creating, editing, and evaluating the case studies. Semi-structured interviews explored the following questions:

Let’s jump into the key experimental results:
Performance on Coaching Recommendations: PH-LLM was rigorously evaluated against a dataset of 857 case studies across sleep and fitness domains. It demonstrated performance close to expert levels, particularly in fitness, where no statistical difference was observed between the model and human experts. For sleep, although still slightly behind experts, PH-LLM showed significant improvement after fine-tuning.
Multiple Choice Exams: PH-LLM scored 79% on sleep-related exams and 88% on fitness-related exams. These scores not only surpassed the average performance of human experts but also exceeded the passing thresholds required for professional certifications in those fields.
Prediction of Patient-Reported Outcomes (PROs): PH-LLM utilized multimodal data to predict self-reported sleep quality outcomes effectively. The model matched the performance of a suite of discriminative models traditionally used for this purpose, showing its ability to integrate and interpret complex, longitudinal sensor data.
Key insights also emerged from the qualitative study:
Complexity in Creating and Editing Case Studies: The process of creating and editing case studies from scratch was described as complex, requiring substantive effort to ensure the text was not only medically accurate but also applicable and personalized to individual health data.
Utility of Numerical Data: The numerical data from wearable devices was instrumental in providing insights into individual health patterns and behaviors. But…extracting meaningful and contextually relevant information from this data was challenging and required significant expertise.
Effectiveness of the Model: The responses generated by PH-LLM were highly rated, especially after fine-tuning, suggesting that the model used domain knowledge and user data appropriately. The fine-tuning process helped improve the model’s ability to make relevant recommendations and interpret complex health data accurately.
Training and Quality Control: Extensive training for experts involved in evaluating the model outputs was important for maintaining high-quality assessments. This training ensured that the evaluations were rigorous and provided meaningful feedback for further model improvement.
Challenges in Personalization: One of the main challenges highlighted was the difficulty in personalizing health recommendations based solely on sensor data. Experts noted that while the model could generate general advice effectively, deeper personalization required more subtle interpretation of data that could be challenging to automate fully.
Areas for Model Improvement: Feedback also pointed to specific areas where the model could be improved, such as improving its ability to understand and integrate longitudinal health data more effectively and refining its recommendations to be more context-sensitive and personalized.
The work does have some limitations. First, the distribution of case study rubric ratings were skewed quite high, making differentiation across models and expert responses challenging. While some case study sections and evaluation rubric principles did show significant differentiation, further training of expert raters to increase inter-rater reliability or adjudicating existing responses could increase signal strength of model performance. Second, owing to inter-rater variability, the authors chose to have each expert rate all responses for a given case study. While this made direct comparison of candidate responses straightforward, it introduced the potential for experts to identify expert vs model responses based on style or other non-material factors, and thus introduce conscious or unconscious biases into ratings.
So there’s still work to be done, but this is an important step in developing such models for healthcare. It seems the paper is going or is undergoing peer review, and the authors state at the end of the preprint that “Case study inputs and associated expert and model responses for the holdout evaluation set will be made publicly available upon peer-reviewed publication.” I’m looking forward to that.