


Musing 57: Multimodal foundation world models for generalist embodied agents
An interesting collaboration out of Ghent, VERSES AI Research Lab, ServiceNow Research and University of Montreal

Today’s paper: Multimodal foundation world models for generalist embodied agents. Mazzaglia et al. 26 June 2024. https://arxiv.org/pdf/2406.18043
Today’s paper addresses the challenge of extending the capabilities of large pre-trained models (or foundation models), to embodied applications where agents interact physically with their environment. These foundation models have shown impressive generalization abilities in vision and language tasks, but applying them to scenarios where agents must perform physical actions and reason about interactions remains difficult.
Reinforcement learning (RL) is a method for teaching agents complex behaviors through visual and proprioceptive inputs by maximizing a reward function. However, scaling RL to multiple tasks and embodied environments is challenging due to the complex and error-prone process of designing reward functions, which require expert knowledge.
Recent approaches have suggested using visual-language models (VLMs) to specify rewards in visual environments through language, but these methods often require fine-tuning or adapting the visual domain, which can be impractical due to the high costs of labeling and the difficulty of converting some embodied contexts into language.
The authors a novel approach called GenRL, which trains generalist agents using visual or language prompts without requiring language annotations. GenRL introduces multimodal foundation world models (MFWMs), illustrated below, which are designed to connect and align the joint embedding space of a foundation video-language model with a generative world model for RL using unimodal vision-only data.
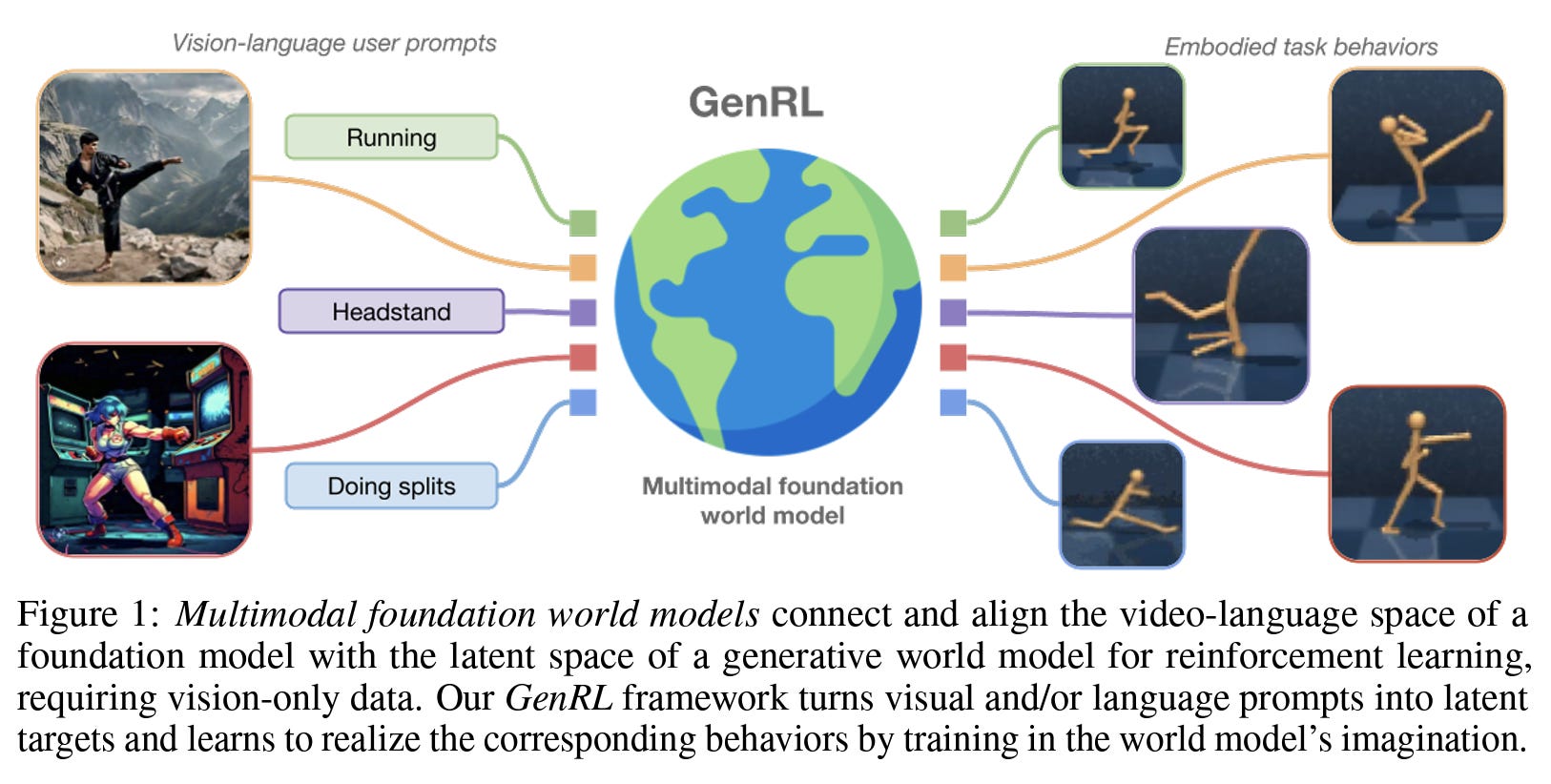
The authors claim that an emergent property of GenRL is the possibility to generalize to new tasks in a completely data-free manner. After training the MFWM, it possesses both strong priors over the dynamics of the environment, and large-scale multimodal knowledge. This combination enables the agent to interpret a large variety of task specifications and learn the corresponding behaviors. Thus, analogously to foundation models for vision and language, GenRL allows generalization to new tasks without additional data and lays the groundwork for foundation models in embodied RL domains. An overview of GenRL is shown below.
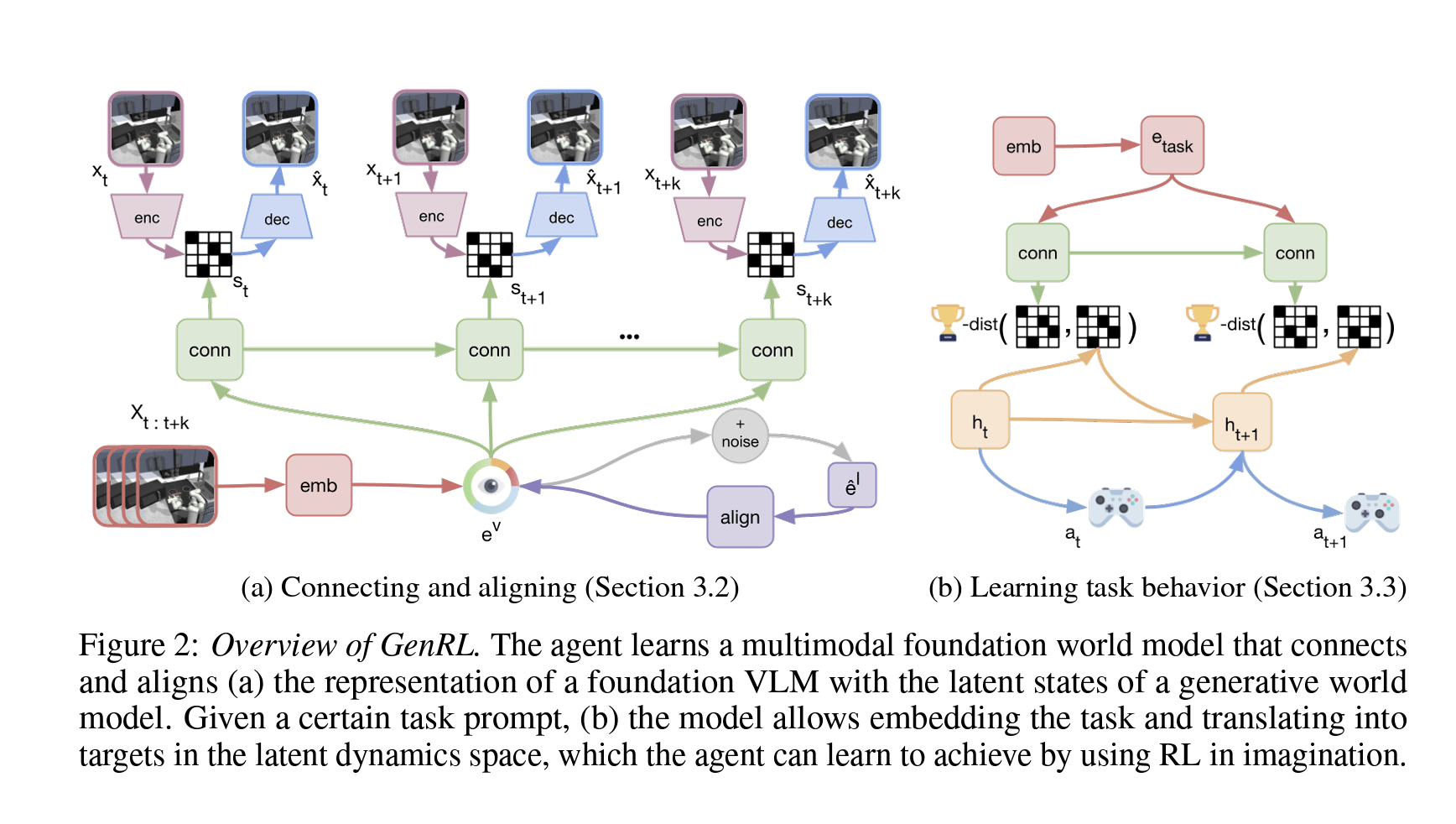
The paper follows with lots of technical details on GenRL itself. As always, the proof is in the (experimental) pudding. The experiments employ a set of 4 locomotion environments (Walker, Cheetah, Quadruped, and a newly introduced Stickman environment) and one manipulation environment (Kitchen), for a total of 35 tasks where the agent is trained without rewards, only from text prompts. The authors claim that this “represents the first large-scale study of multi-task generalization from language in RL.” Details about datasets, tasks, and prompts used can be found in an accompanying appendix.
The authors present results in Table 1 below, with episodic rewards rescaled so that 0 represents the performance of a random agent, while 1 represents the performance of an expert agent. GenRL is found to excel in overall performance across all domains, particularly in dynamic tasks like walking and running in the quadruped and cheetah domains. In contrast, in static tasks such as ‘stickman stand’ and kitchen tasks, other methods occasionally outperform GenRL. The authors explain this by noting that the target-sequences that GenRL infers from the prompt are often slightly in motion, even in static cases. To address this, the target sequence length could be set to 1 for static prompts, but they opted to maintain the method’s simplicity and generality, and acknowledge this as a minor limitation.

In Figure 3 above, the authors assess multi-task generalization, whereby they defined a set of tasks not included in the training data. Although they don’t anticipate agents matching the performance of expert models, higher scores in this benchmark help gauge the generalization abilities of different methods. As shown in the figure, they observe a similar trend as for the behavior extraction results. GenRL significantly outperforms the other approaches, especially in the quadruped and cheetah domains, where the performance is close to the specialized agents’ performance. Both for image-language (-I in the Figure) and video-language (-V in the Figure) more conservative approaches, such as IQL and TD3+BC tend to perform worse. This could be associated with the fact that imitating segments of trajectories is less likely to lead to high-rewarding trajectories, as the tasks are not present in the training data.
There are a bunch of other results, but the ones above show that the method is indeed competitive. In conducting additional analyses, the authors note that “while language strongly simplifies specification of the task, in some cases providing visual examples of the task might be easier.” Similarly as for language prompts, GenRL allows translating vision prompts (short videos) into behaviors. As this is a less common evaluation setting, however, they limit their assessment to qualitative results.

As shown above, they present a set of video grounding examples, obtained by inferring the latent targets corresponding to the vision prompts (right image) and then using the decoder model to decode images (left image). They observe that the agent is able to translate short human action videos into the same actions but for the Stickman embodiment. The claim is that, by applying this approach, it would be possible to learn behaviors from a single video. However, I feel that more results of a quantitative nature are needed, before the claim can be fully accepted at face value, although it is, of course, promising.
Several limitations are noted toward the conclusion of the paper, largely due to inherent weaknesses in GenRL’s components. From the VLMs, GenRL inherits the issue related to the multimodality gap and the reliance on prompt tuning. The authors proposed a connection-alignment mechanism to mitigate the former. For the latter, they presented an explainable framework, which enables prompt tuning by allowing decoding of the latent targets corresponding to the prompts. From the world model, GenRL inherits a dependency on reconstructions, which offers advantages such as explainability but also drawbacks, such as failure modes with complex observations. In future work, some of these limitations can be addressed, along with expanding the scope of GenRL.
Overall, I thought the paper was strong, and the authors were forthcoming about where the method was working well and where (sometimes) baselines were winning. It’s always refreshing to see results contextualized in that manner, as opposed to a method that beats all baselines at all tasks. The method itself is an exciting one, and further reinforces the power of foundation models for all kinds of tasks that they were arguably not designed for originally, if they are used and adapted in the right way.