
Musing 64: Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
A paper out of Baichuan Inc. and Tianjin University

Today’s paper: Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning. Wang et al. 15 July 2024. https://arxiv.org/pdf/2407.10718
Large language models (LLMs) have transformed the landscape of human-computer interaction (HCI) by offering unprecedented capabilities in understanding and generating human-like text. LLM-based agents, which are systems designed to harness these models, effectively orchestrate LLM capabilities to address complex tasks. These agents use human-designed frameworks that utilize the inherent knowledge within LLMs, often employing structured workflows that maximize the potential of in-context learning and zero-shot capabilities. Such strategies allow these agents to engage in sophisticated dialogues and problem-solving scenarios that mirror human cognitive processes. By incorporating prior human knowledge into the workflow, LLM-based agents can process and utilize information with a level of proficiency that was previously unattainable.
The authors argue that, despite this progress, LLM-based agents are often limited by their inability to engage in complex questions of reasoning in real-world scenarios, where there are many reasoning steps. LLMs especially struggle when tasks demand lengthy, complex reasoning chains, often resulting in error propagation and a steep decline in accuracy. This complexity not only impedes their practical deployment, but also restricts their adaptability and scalability in various LLM applications, which underscores the need for an approach that has simple design while improving the reasoning capabilities of LLM-based agents.
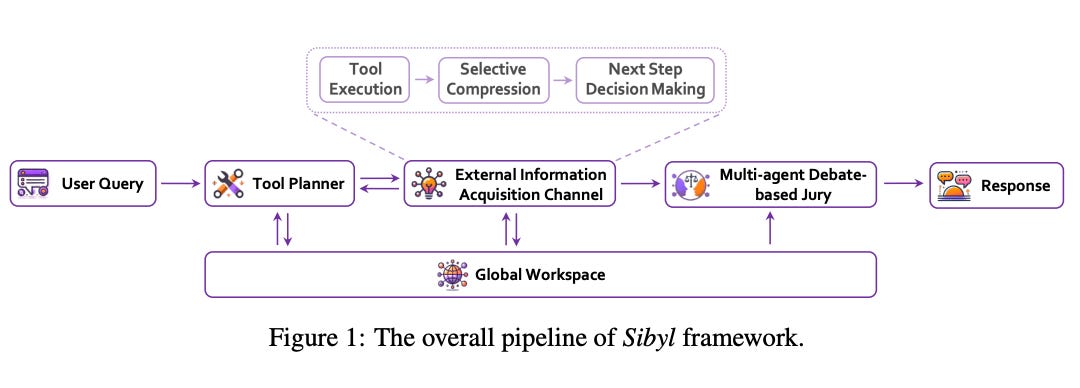
To address the identified limitations in long-term reasoning and system complexity, today’s paper introduces Sibyl, a simple yet powerful LLM-based agent framework. The system is compartmentalized into four main modules (as shown above): tool planner, external information acquisition channel, a jury based on multiagent debate and a global workspace. The inner design of Sibyl is inspired by functional programming principles, emphasizing reusability and statelessness between operations. This is realized through the use of QA functions instead of dialogues in internal LLM inference requests, allowing for each LLM inference to operate independently without the need to maintain a persistent state.
The details behind the system are covered in the paper itself, but one point worth mentioning is that the framework “places a strong emphasis on enhancing capabilities for long-term memory, planning, and error correction–elements vital for complex, long-distance reasoning.” By doing so, the authors argue that Sibyl mimics the Kahneman dual-process model of System 1 and System 2 thinking. It implements shared long-term memory by incorporating a global workspace that all modules share, which is designed from the ground up and stores information with an incremental state-based representation language. This language selectively compresses past events, adding only information increments relevant to problem solving, rather than simply appending all incoming data.
Additionally, it summarizes the outcomes from its tools, and plans subsequent steps based on the assessment of current progress. This involves strategic thinking about which pieces of information are necessary and how they should be processed moving forward. Also implemented is a “Jury” mechanism, which utilizes a multiagent debate format for self-critique and correction. This process allows the model to utilize the information stored in the global workspace efficiently to refine responses and ensure accurate problem solving.
On to experiments, always the most important portion in any such paper. Evaluations are conducted on the GAIA dataset, a benchmark tailored for general AI assistants. It is designed to reflect tasks that align closely with human perceptual capabilities, including visual, auditory, and textual modalities. It challenges general-purpose assistants with complex reasoning tasks that even require dozens of steps to solve, similar to those encountered by humans. Such a design significantly magnifies the impact of error propagation, providing a robust evaluation of problem-solving and error-handling capabilities for LLM-based agents.
Several established baselines are used: : 1) GPT-4, with and without manually configured plugins, 2) AutoGPT-4, which integrates AutoGPT with a GPT-4 backend, 3) An LLM-based agent implemented by AutoGen, a framework designed for automating complex multi-agent scenarios, and 4) FRIDAY, an advanced agent utilizing OS-Copilot for automating a broad spectrum of computer tasks, capable of interfacing with various operating system elements including web browsers, code terminals, and multimedia.
The results of the experiments on both the test and validation sets of the GAIA dataset are presented in Tables 1 and 2 below.
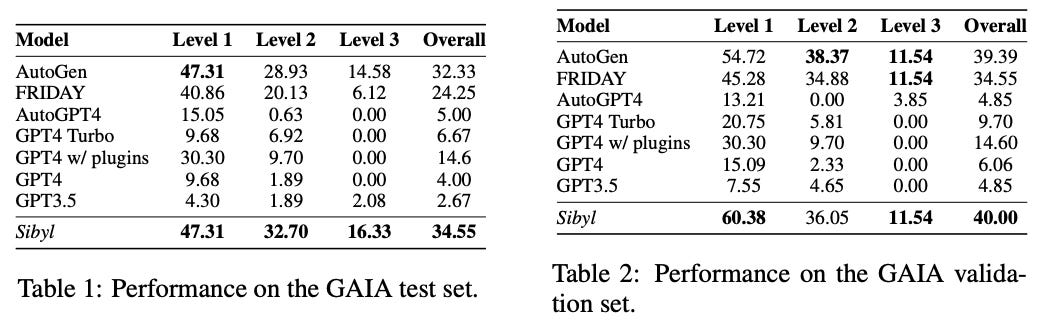
Sibyl outperforms other models in the GAIA private test set, particularly in the more challenging Level 2 and Level 3 scenarios. This improvement is noteworthy given that these levels require longer steps for humans to solve, demonstrating Sibyl’s enhanced ability to mitigate error propagation in complex reasoning processes. Furthermore, the comparison of performances on the test and validation sets indicates that Sibyl exhibits superior generalization capabilities. The smaller decline in accuracy from validation to test set (40.00 to 34.55) compared to AutoGen (39.39 to 32.33) and FRIDAY (34.55 to 24.25) underscores Sibyl’s robustness across different operational environments.
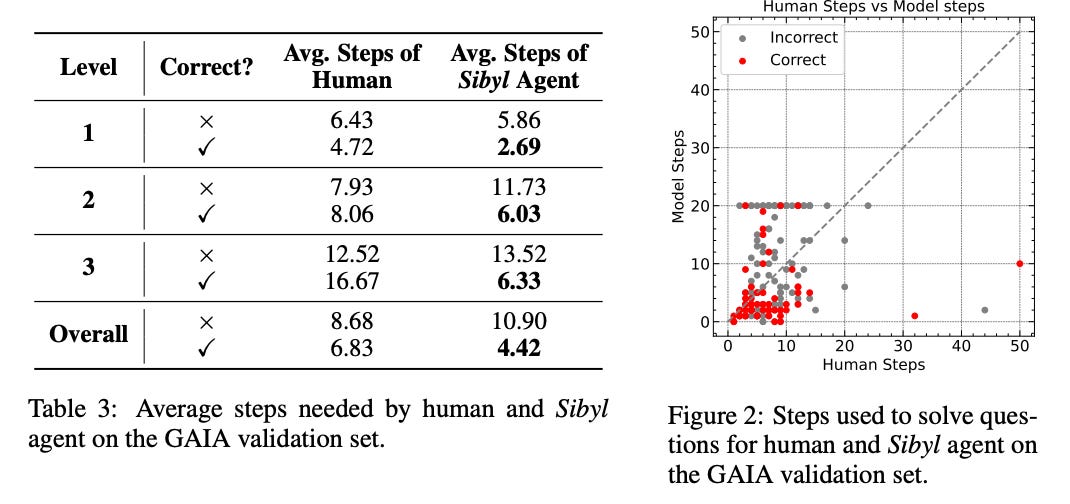
The authors also analyze the number of steps required to solve problems compared to humans. As shown in Table 3 above, in problems where the Sibyl agent was correct, it consistently outperformed humans in efficiency, using significantly fewer steps in levels 1 through 3. Further insights are gained from Figure 2, which plots the number of steps taken by humans versus those taken by the Sibyl agent for each question in the GAIA validation set. These results demonstrate that despite being limited to a maximum of 20 reasoning steps, the Sibyl agent exhibited a high level of reasoning efficiency, indicating strong capability to mitigate unnecessary reasoning and suppress error propagation.
In closing, the framework seems to be impressive, although I feel that its true prowess will only become clear once it’s evaluated on more benchmarks and datasets. The code is available at https://github.com/Ag2S1/Sibyl-System so folks can definitely try it out for themselves.