
Musing 66: SciCode: A Research Coding Benchmark Curated by Scientists
A multi-institutional paper from the liked of Harvard, Stanford and several others

Today’s paper: SciCode: A Research Coding Benchmark Curated by Scientists. Tian et al. 18 July 2024. https://arxiv.org/pdf/2407.13168
In today’s paper, the authors start by stating something that has become increasingly clear to those working with them: LLMs now surpass the performance of most humans except domain experts, and evaluating them has become increasingly challenging. Many established benchmarks struggle to keep pace with the advancements in LM performance and have quickly become saturated, leading to discrepancies between the models’ perceived and actual capabilities. In my own research, I’ve seen this firsthand when evaluating these LLMs on commonsense reasoning.
As a consequence, researchers are developing synthetic challenging benchmarks, often involving models in the construction of evaluation instances. For example, some researchers subsample instances from existing benchmarks that cannot be solved by current models, or augment them to construct more challenging evaluations. However, it is unclear whether such efforts accurately reflect real-world applications and the models’ performance in practical scenarios. Realistic, high-quality, and challenging evaluations are crucial for the continued advancement of LMs.
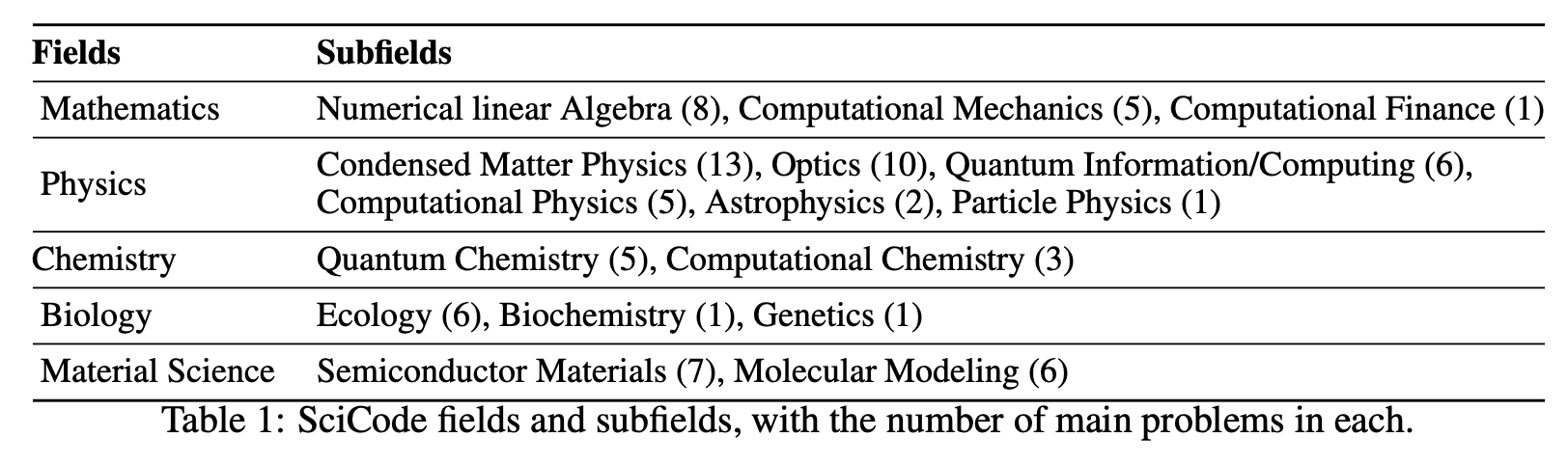
With this motivation in mind, the authors propose SciCode, a benchmark containing code generation problems drawn from diverse natural science fields, including mathematics, physics, chemistry, biology, and materials science. SciCode contains 80 main problems, each decomposed into multiple subproblems, totaling 338. Each problem provides the scientific background when necessary as well as detailed instructions. To solve it, the model must implement multiple Python functions—one for each subproblem—and then integrate them into a complete solution for the main problem. For every main problem and subproblem, SciCode provides gold-standard solutions and multiple test cases, facilitating easy and reliable automatic evaluation. The figure below shows an example.

SciCode is mainly drawn from the scripts that scientists use in their everyday workflow. Many of these have been used in one or more publications, demonstrating their robustness and correctness. However, they are primarily for internal use, which means that they are seldomly open-sourced and often poorly annotated. Consequently, unlike general-domain coding problems, natural science problems have less exposure in most current LLMs’ training data. This offers a unique opportunity to evaluate the models’ ability to generalize to less familiar contexts.
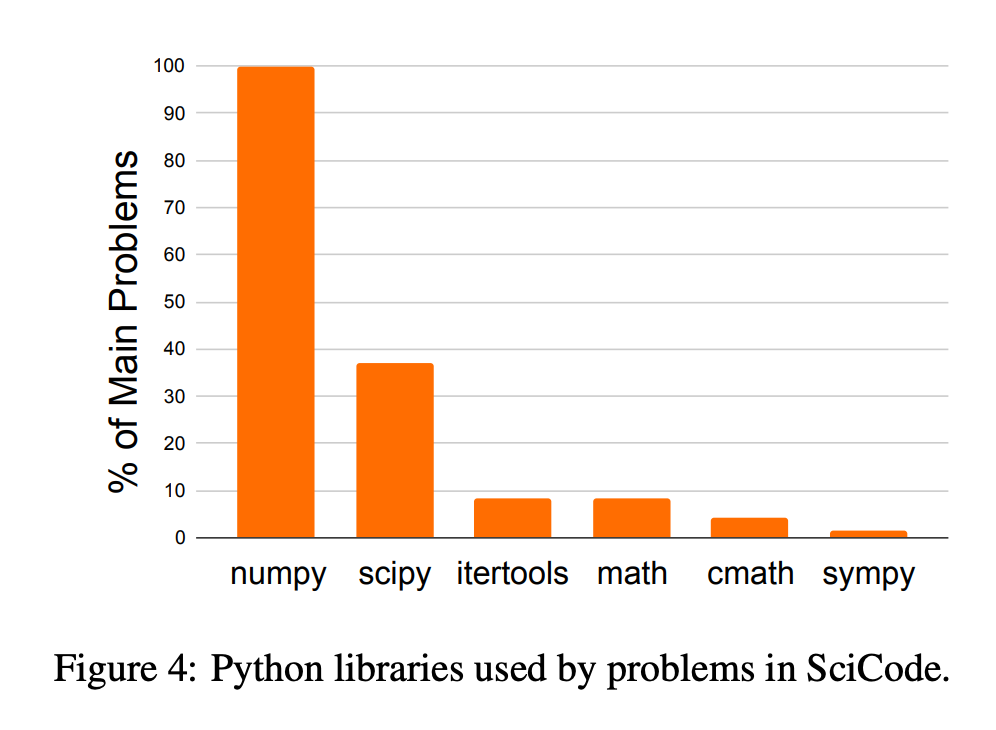
To facilitate evaluation of this new benchmark, the authors had “scientist annotators” use only widely adopted and well-documented packages such as NumPy, SciPy, and SymPy when writing the solution code for their problems, as shown in the figure below. Their test suite involves two key components. (1) Numerical tests list input-output pairs to check if the generated code produces the same outputs as ground truth. (2) Domain-specific test cases, introduced as an additional stage, evaluate whether model-generated solutions align with scientists’ practical needs and further ensure the correctness and applicability of each solution within its specific field. These tests are extracted from real scientific workflows: scientists must design domain-specific test cases to verify code accuracy by reproducing results published in academic papers or matching analytical solutions derived from theoretical models.
Overall, the evaluation design aims to balance the fidelity of the scientific problem with the practicality of the evaluation process, ensuring that the solutions are both accurate and accessible. Moving on to experiments, the authors claim that because this is a challenging benchmark they mainly consider “strong language models”:

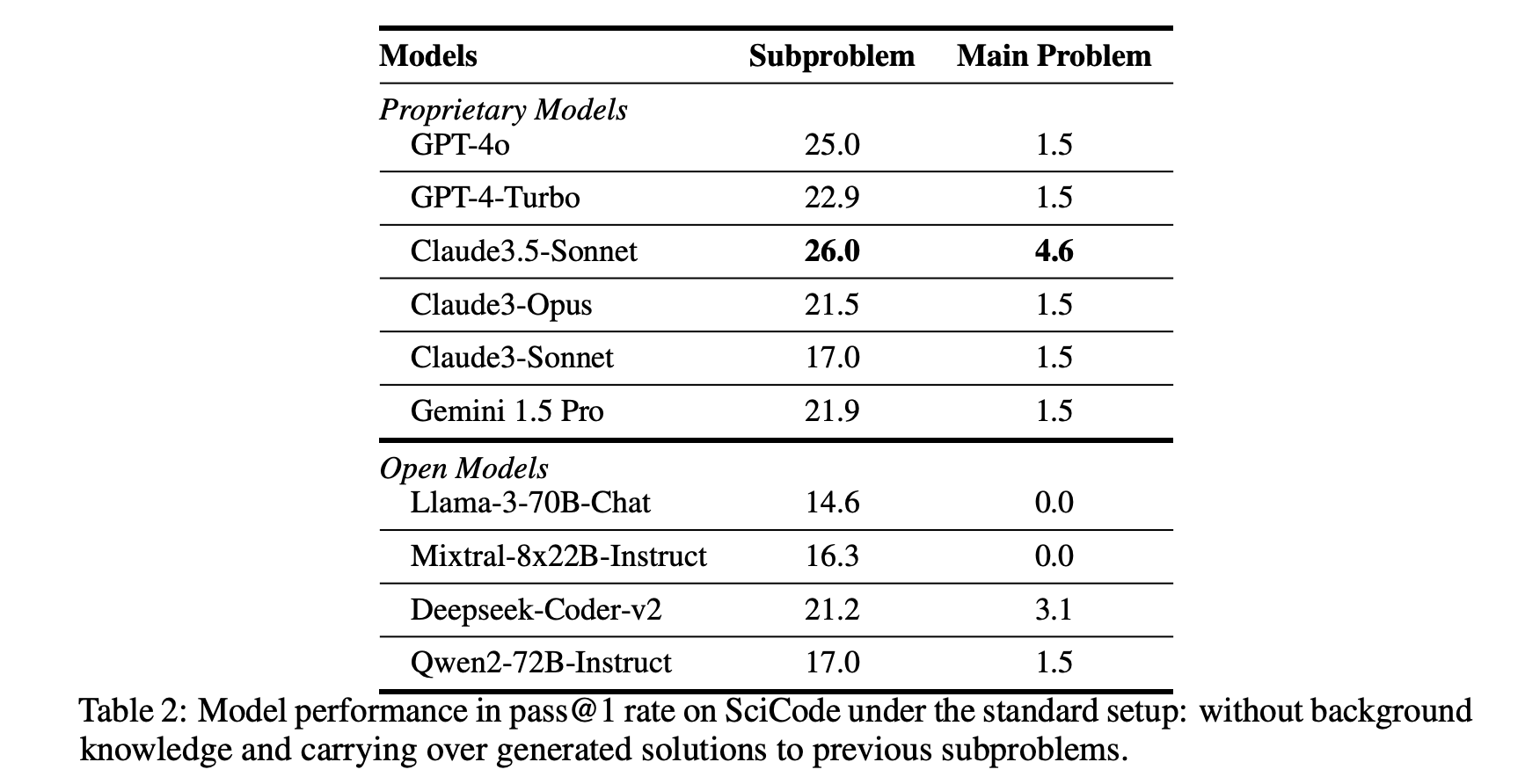
The table below presents results under the standard setup. For the easier subproblem-level evaluation, the state-of-the-art models being tested solve 14%-26% of the subproblems. Among them, Claude3.5-Sonnet achieves the best performance, with a 26.0% pass@1 rate. However, all models perform much worse on the more realistic and challenging main problem evaluation. Claude3.5-Sonnet still performs the best in this setting, but with only a 4.6% pass@1 rate. The authors use these results to confirm that SciCode is a difficult benchmark for current LLMs. Consistent with their observations on proprietary models, open-weight LLMs under test also showed their lack of capabilities in solving any main problem despite being able to solve a number of sub-problems correctly.
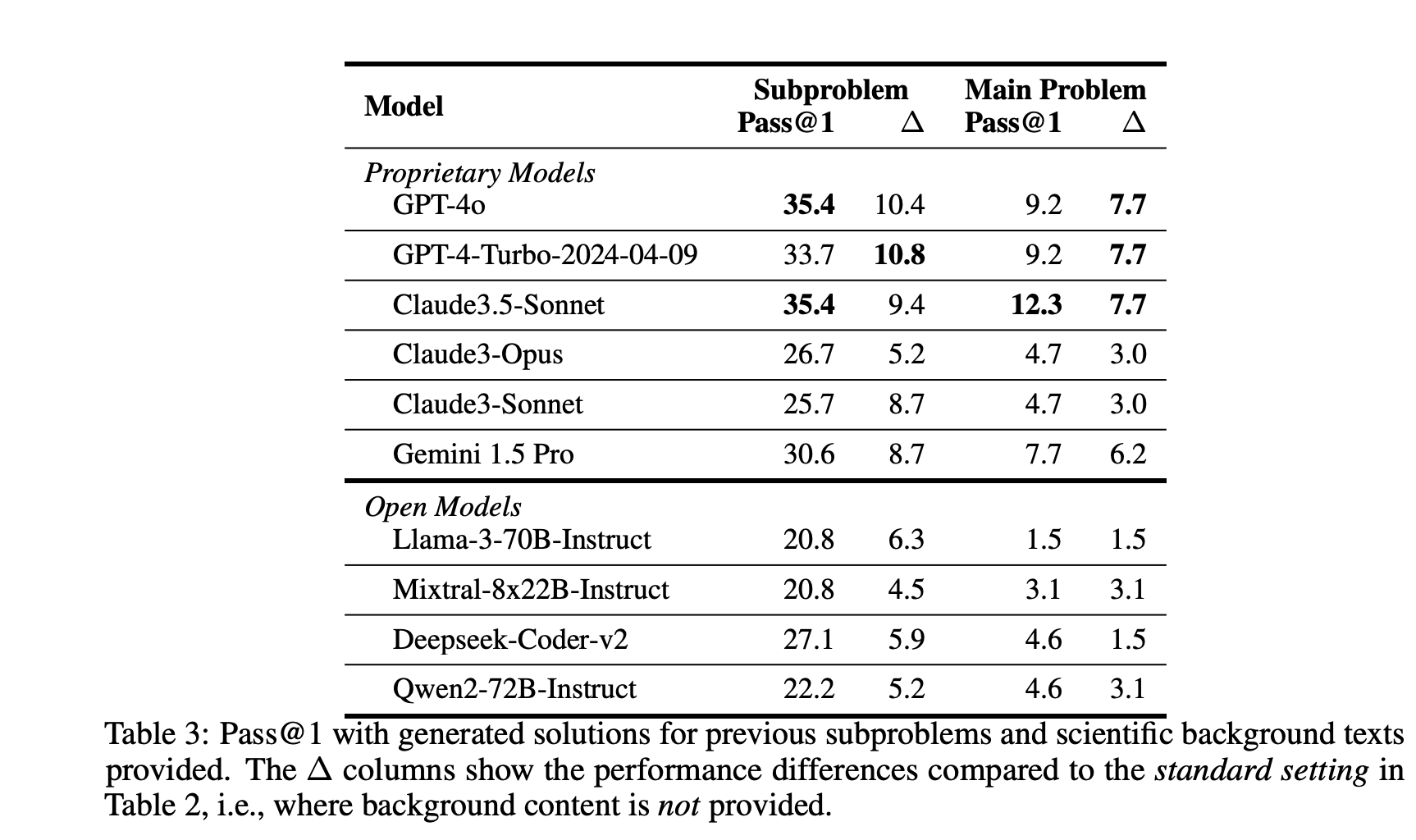
In the table below, the authors also present results when background text authored by scientists is provided to the LLMs and generated solutions to previous subproblems are used. This setting evaluates both the models’ capabilities to faithfully follow the instructions provided in the background as well as their code-generation performance. The ∆ columns indicate performance differences compared to the standard setup.
There are a number of other details and evaluations provided, but these make the point clearly enough. The evaluation is impressive; the authors went out of their way to show that this is a challenging benchmark with validity.
In closing, the authors believe that the availability of this “well-designed benchmark can motivate research into developing new AI methods for accelerating scientific research, an area that has thus far benefited less from recent LM advancements partly due to a lack of commercial incentive.” I agree, although I also think that scale can be an issue here; SciCode doesn’t seem to be as large or extensive (obviously, in my opinion) as some of the other benchmarks that have been proposed. Nevertheless, new benchmarks are always welcome. It is becoming difficult, in fact, to keep up with them. These are interesting times, not just for developing new AI methods, but for evaluating them properly.