
Musing 70: The Clever Hans Effect in Unsupervised Learning
A fascinating academic-industrial paper on the perils of evaluating unsupervised learning.

Today’s paper: The Clever Hans Effect in Unsupervised Learning. Kauffmann et al. https://arxiv.org/pdf/2408.08041. 15 Aug. 2024.
Unsupervised learning is an important sub-area of machine learning that has rapidly become prominent. It aims to get around the fundamental limitations of supervised learning, such as the lack of labels in the data or the high cost of acquiring them. Unsupervised learning has achieved successes in modeling the unknown, with applications including uncovering new cancer subtypes or extracting novel insights from large historical corpora.
Because unsupervised learning does not rely on task-specific labels makes it a good candidate for core AI infrastructure; additionally, it is also a key technology behind ‘foundation models’ which extract representations upon which various downstream models can be built. The most obvious application is the large language models (LLMs).
The authors argue that the growing popularity of unsupervised learning models creates an urgent need to carefully examine how they arrive at their predictions. This is essential to ensure that potential flaws in the way these models process and represent the input data are not propagated to the many downstream supervised models that build upon them.
In today’s paper, the authors purport to show for the first time that unsupervised learning models largely suffer from Clever Hans (CH) effects, also known as “right for the wrong reasons”. I was not specifically aware of this terminology, although the phrase ‘right for the wrong reasons’ has been of interest in my own research (for example, in the domain of machine common sense). The authors find that unsupervised learning models often produce representations from which instances can be correctly predicted to be e.g. similar or anomalous, although largely supported by data quality artifacts. The flawed prediction strategy is not detectable by common evaluation benchmarks such as cross-validation, but may manifest itself much later in ‘downstream’ applications in the form of unexpected errors, e.g. if subtle changes in the input data occur after deployment. This is shown in the figure below.
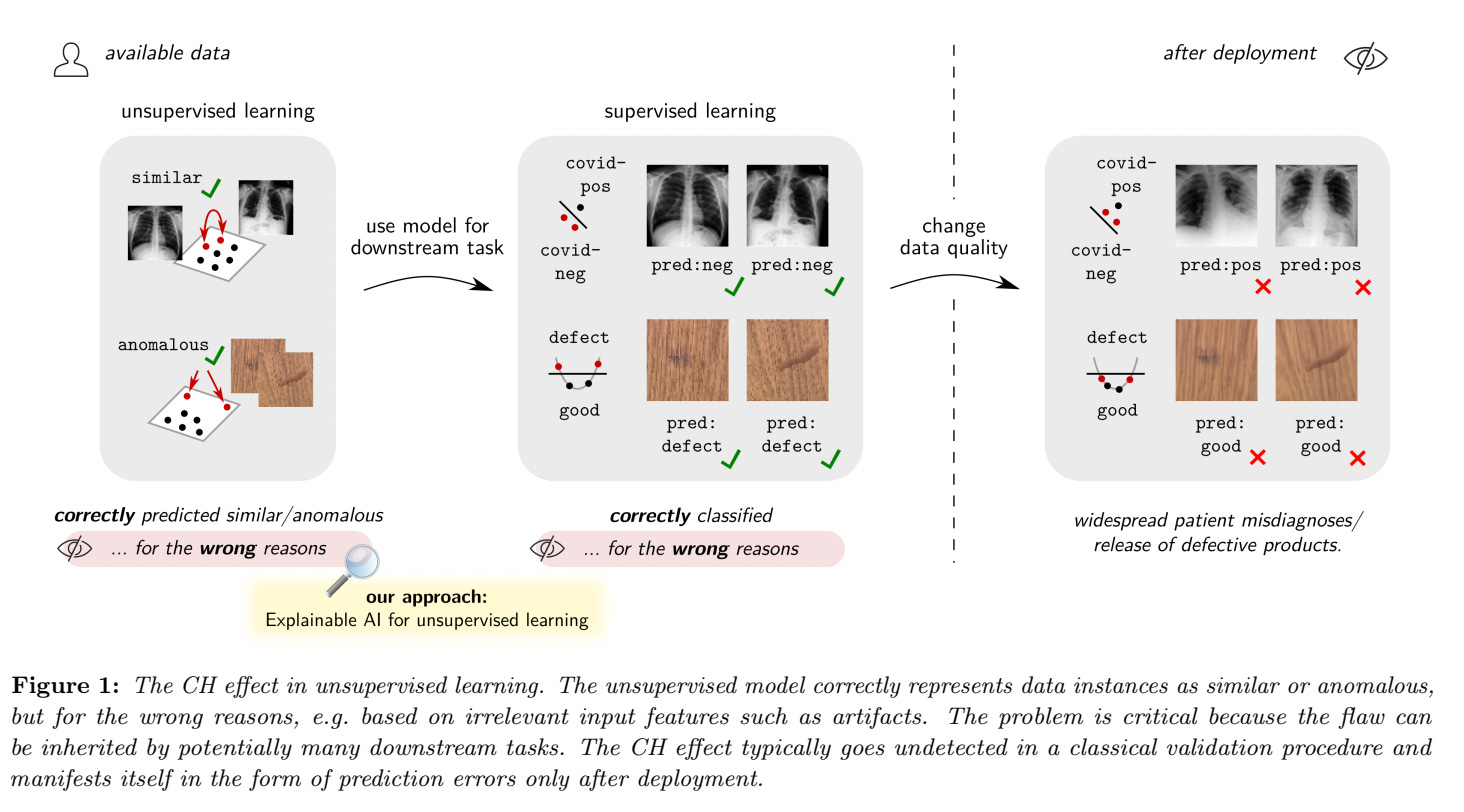
While CH effects have been studied quite extensively for supervised learning, the lack of similar studies in the context of unsupervised learning, together with the fact that unsupervised models supply many downstream applications, is a cause for concern.
To uncover and understand unsupervised Clever Hans effects, the authors propose to use Explainable AI (here techniques that build on the LRP or layer-wise relevance propagation explanation framework). It is not necessary to understand this method to understand the authors’ results. The key thing to note is that their proposed use of these techniques allows them to identify at scale which input features are used (or misused) by the unsupervised ML model, without having to formulate specific hypotheses or downstream tasks.
Let’s jump to results. The authors first consider an application of representation learning in the context of detecting COVID-19 cases from X-ray scans. Simulating an early pandemic phase characterized by data scarcity, the authors use a dataset aggregation approach where a large, well-established non-COVID-19 dataset is merged with a more recent COVID-19 dataset aggregated from multiple sources.
They then feed this data into a pre-trained PubMedCLIP model, which has built its representation from a very large collection of X-ray scans in an unsupervised manner. Based on the PubMedCLIP representation, they train a downstream classifier that separates COVID-19 from non-COVID-19 instances with a class-balanced accuracy of 88.6% on the test set (see Table 1 below). However, a closer look at the structure of this performance score reveals a strong disparity between the NIH and GitHub subgroups, with all NIH instances being correctly classified and the GitHub instances having a lower class-balanced accuracy of 75.2%, and, more strikingly, a false positive rate (FPR) of 40%.
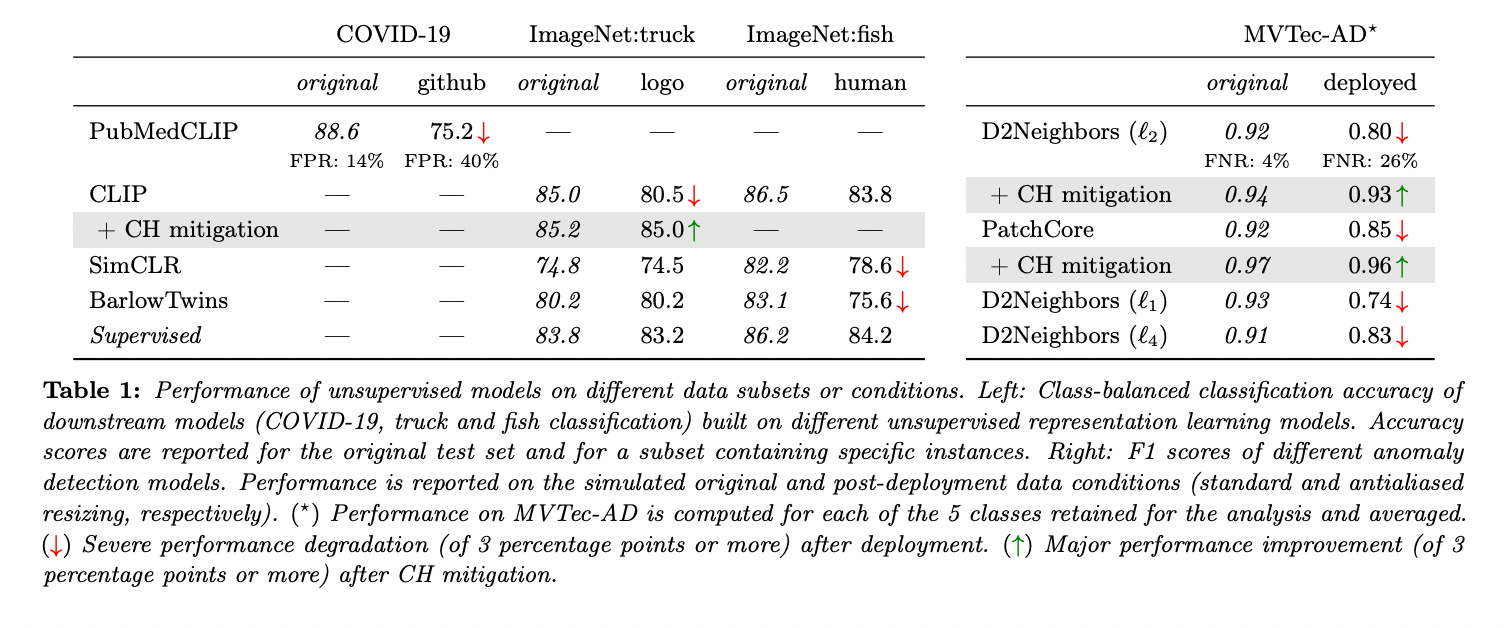
Considering that the higher heterogeneity of instances in the GitHub dataset is more characteristic of real-world conditions, such a high FPR prohibits any practical use of the model as a diagnostic tool. The authors take pains to emphasize that this deficiency could have been easily overlooked if one did not pay close attention to (or did not know) the data sources, and instead relied only on the overall accuracy score.
Investigating further, using the BiLRP technique, the authors investigate whether PubMedCLIP represents different instances as similar based on a correct strategy or a ‘Clever Hans’ strategy. The output of BiLRP for two exemplary pairs of COVID-positive instances is shown in the figure below (left). The BiLRP explanation shows that the modeled similarity between pairs of COVID-positive instances comes from text-like annotations that appear in both images. This is a clear case of a CH effect, where the modeled similarity is right (instances share being COVID-positive), but for the wrong reasons (similarity is based on shared textual annotations).
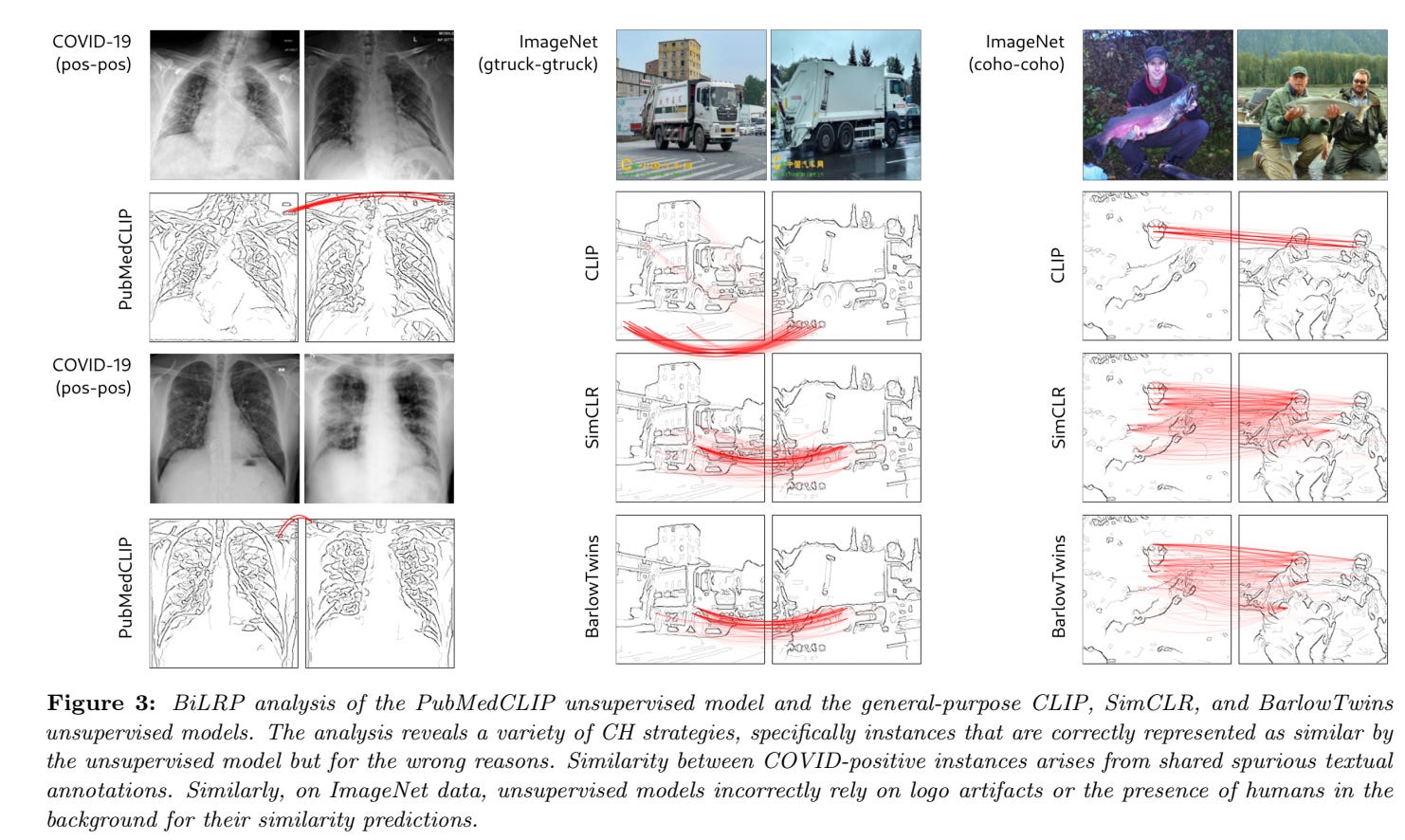
The unmasking of this CH effect by BiLRP warns of the risk that downstream models based on these similarities (and more generally on the flawed representation) may inherit the CH effect. This a posteriori explains the excessively high (40%) FPR of the downstream classifier on the Github subset, as the model’s reliance on text makes it difficult to separate Github’s COVID-positive from COVID-negative instances. Other datasets (than the COVID dataset) are also explored, with the conclusions being qualitatively similar.
The authors also explore the Clever Hans effect on anomaly detection, but the application above makes the point quite well. They argue convincingly that the CH effects detected by BiLRP analysis have concrete negative practical consequences in terms of the ability of unsupervised models and downstream classifiers to predict uniformly well across subgroups and to generalize. In comparison, the baseline supervised model generally shows more stable performance between the original data and the newly defined subsets. A detailed analysis of the structure of the prediction errors for each classification task, supported by confusion matrices, is given in the supplementary material.
One limitation of the study might be said to be that it only focuses on image applications. However, as the authors point out, extension to other data modalities is actually straightforward. Explainable AI techniques such as LRP, which are capable of accurate dataset-wide explanations, operate independently of the type of input data. They have recently been extended to recurrent neural networks, graph neural networks, transformers, and state space models, which represent the state of the art for large language models and other models of structured data. Thus, the authors’ analysis could be extended to analyze other instances of unsupervised learning, such as anomaly detection in time series or the representations learned by large language models.
In closing, this paper is yet another reminder of why we need to be more careful, even skeptical, of claims along the lines of “my system has exceeded the state of the art” by x percent. For supervised learning, this phenomenon was already well known (although uncomfortable to acknowledge for many), but this paper has quite rigorously laid out the phenomenon for unsupervised learning. Its findings deserve to be widely disseminated and discussed.