
Musing 79: Zero-Shot Decision Tree Induction and Embedding with Large Language Models
An intriguing paper on the mingling of the classic and the recent

Today’s paper: "Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models. Knauer et al. 27 Sep. 2024. https://arxiv.org/pdf/2409.18594
Which of us doesn’t remember decision trees with some fondness (yes, even young students)? I encountered mine for the first time as an undergraduate student at the University of Illinois at Urbana-Champaign, when I took an introductory junior-level survey course on AI in the CS department. I had a sci-fi view of AI at that point; what I now recognize as artificial ‘general’ intelligence (AGI). At the time, and for many years thereafter (and before), AI research was limited to more narrow domains like face recognition or entity resolution. I ended up doing an entire PhD thesis on the latter, as did many others. Today, of course, LLMs have brought about a serious discussion on AGI, which has always been the original vision, going back to the ‘founding’ of AI as a named discipline in the late 1950s.
The point in reminiscing about all this is that decision trees, naive Bayes and other models like random forests, logistic regression, and simple multi-layer perceptrons, all staples now in classic machine learning libraries like Python’s scikit-learn, formed the bread and butter of introductory courses on AI. Without learning about these, it is still not possible to gain a deep and applied understanding of the phenomenon of learning itself. And that, of course, is crucial for then going into other areas of machine learning, including deep learning and large language models.
Today’s paper is one of the rare ones, to my knowledge, that shows how LLMs can help us with the more classic models by being used for zero-shot decision tree induction. For those who don’t remember, or haven’t seen, what a decision tree looks like, here’s a short example:
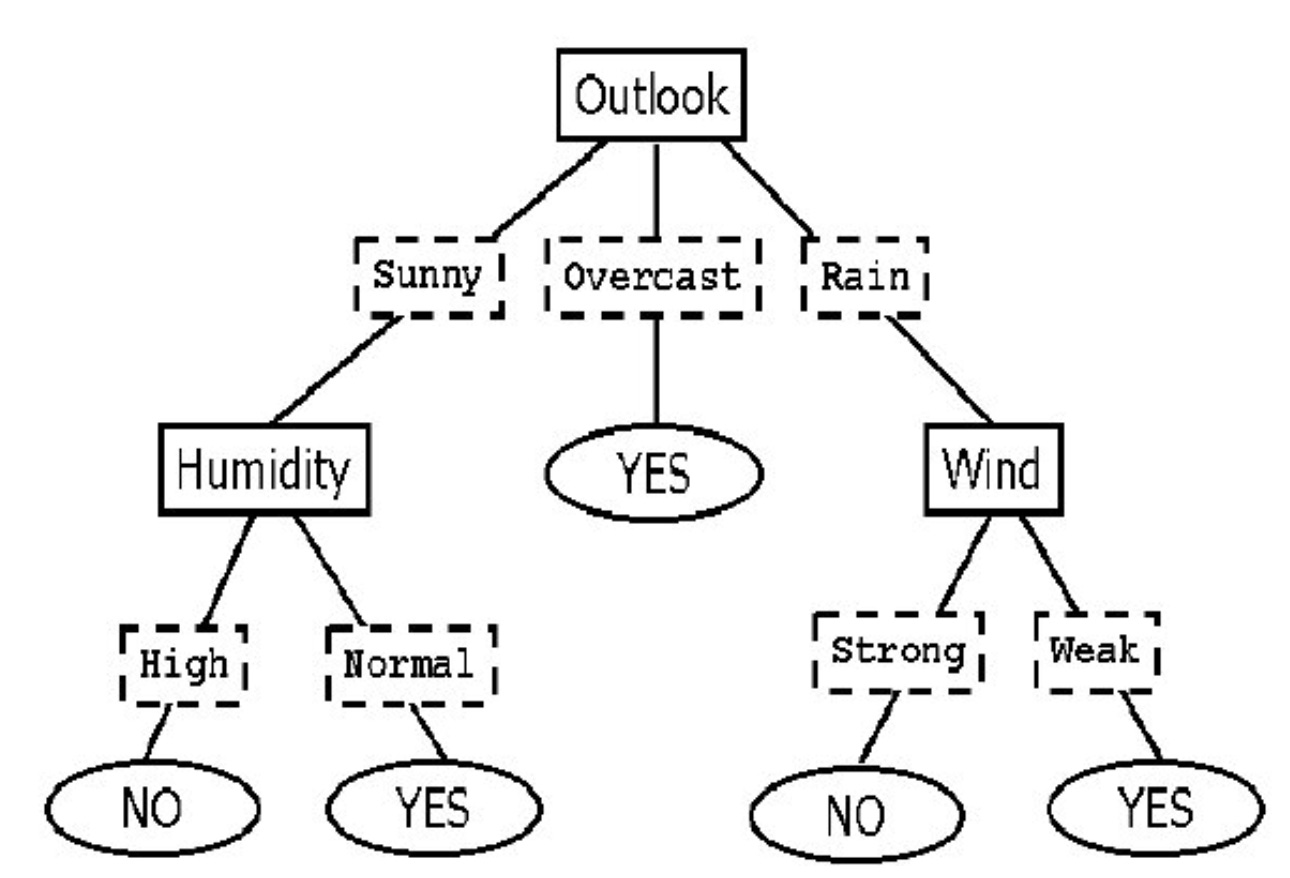
In this (classic) example, a decision tree is used for deciding whether conditions are good for playing tennis outdoors. If it’s sunny, and humidity is normal, I’ll play. If there’s rain and the wind is strong, I won’t.
In today’s paper, the authors show how state-of-the-art LLMs can be used for building intrinsically interpretable machine learning models, i.e., decision trees, without access to the model weights and without any training data. This is really the key contribution of the paper. The authors then demonstrate how their zero-shot decision trees can also serve as feature representations for downstream models. Finally, the authors offer a systematic comparison of their decision tree induction and embedding approaches with state-of-the-art machine learning methods on 13 public and 2 private tabular classification datasets in the low-data regime .
The approach involves a simple prompting method to induce the decision tree, which is provided in the paper. The LLM is prompted with feature names and instructed to build a decision tree of a specified maximum depth, typically capped at two for interpretability. The LLM uses its knowledge of the world, accumulated from pretraining on vast amounts of text and data, to identify the most important features and construct a decision tree.
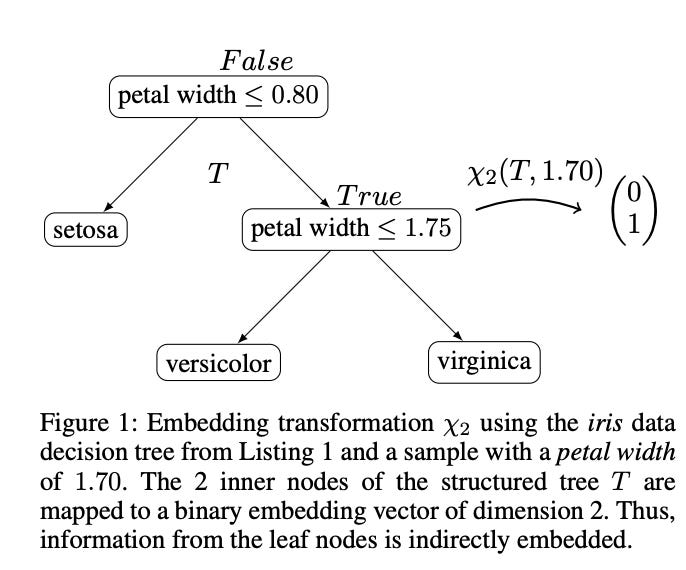
Figure 1 below demonstrates how zero-shot decision tree generation can be converted into a structured feature representation, which can then be processed by other machine learning models. A decision tree is generated using the well-known Iris dataset, where the feature "petal width" is used to classify different flower species. The transformation takes the binary decision tree and encodes the truth values of its inner nodes into a binary vector. In this case, the binary vector represents whether the conditions in the decision tree (such as whether petal width is greater than or less than a specific threshold) are met. This vector can then be used as an embedding for downstream models, allowing for further predictive modeling.
Moving on to experiments, for their decision tree induction experiments, the authors used 3 state-of-the-art LLMs as well as 5 machine learning baselines, i.e., 2 data-driven intrinsically interpretable predictive models, 2 automated machine learning (AutoML) frameworks, and 1 off-the-shelf pretrained deep neural network. The results for the median test F1-score for their induction experiments can be found in Table 1 below. On the public data, the knowledge-driven trees achieved a competitive performance to data-driven trees on individual datasets - without having seen any of the training data. At 67%/33% train/test splits, for instance, Gemini 1.5 Pro achieved a better median test balanced accuracy to OCTs on labor (+0.05) and Claude 3.5 Sonnet even reached a better core than both data-driven interpretable baselines on boxing1 (+0.05 and + 0.09). On other datasets, the results are similarly impressive.
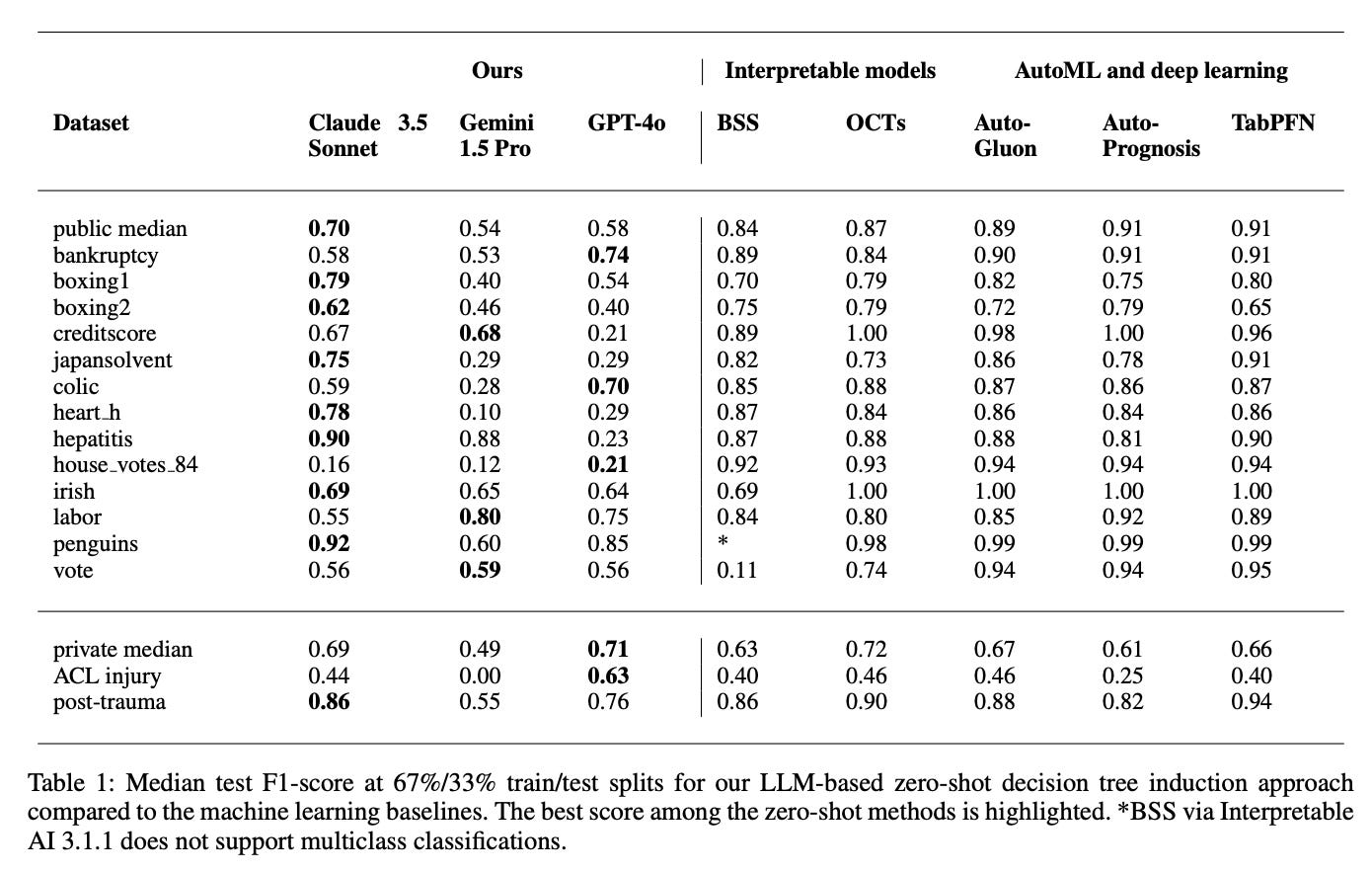
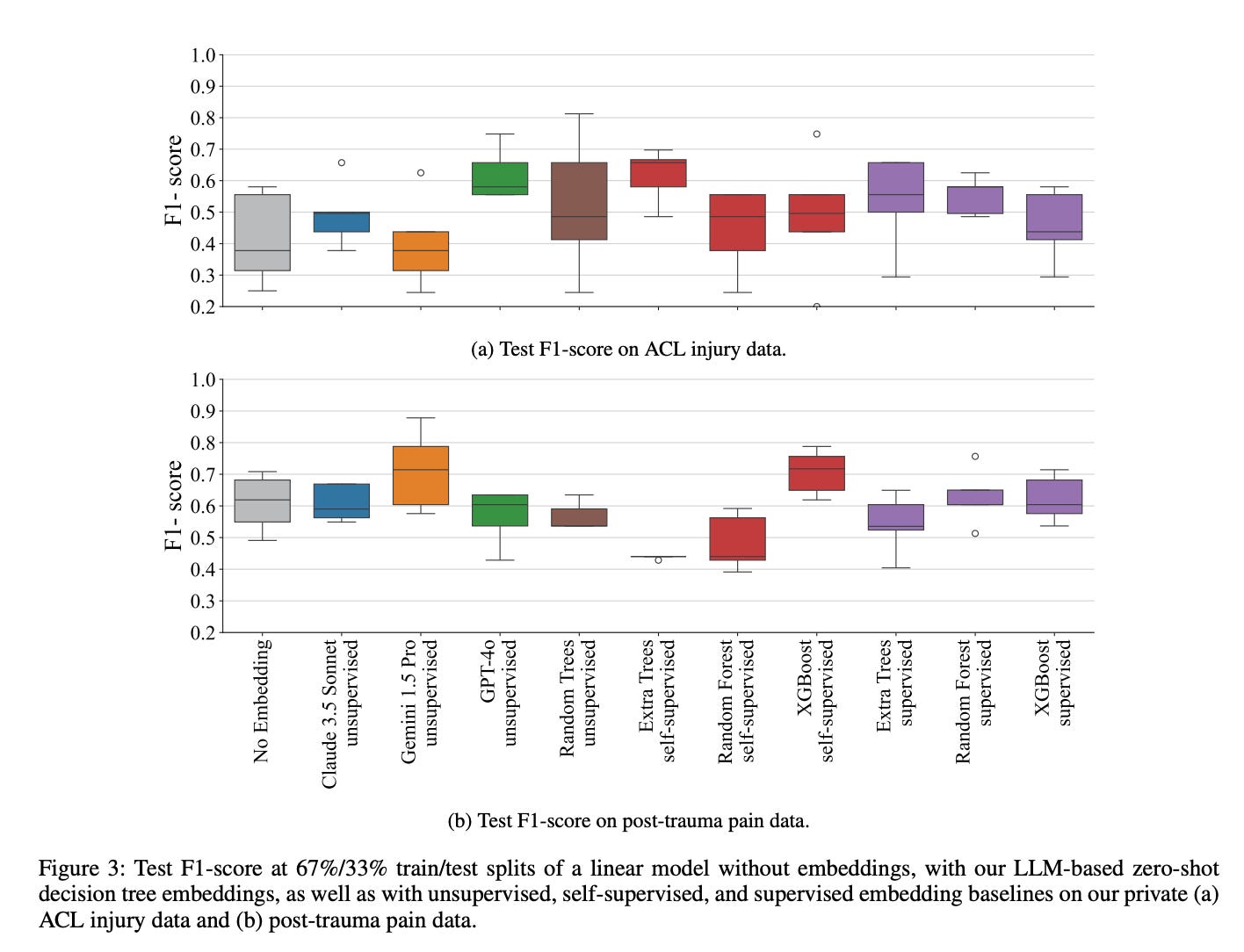
Figure 3 below shows test F1-score boxplots and test balanced accuracy boxplots for the private datasets. On individual datasets, the median test F1-score and balanced accuracy improved compared to no embedding by up to +0.33 and +0.30. On the ACL injury data, GPT-4o increased the median test F1-score and balanced accuracy compared to no embedding by +0.20 and +0.20 and was only outperformed by self-supervised extra trees embeddings with improvements of +0.28 and +0.30, respectively.
In closing, we’ve seen by now that LLMs provide powerful means to leverage prior knowledge in the low-data regime. In this work, the authors presented how this condensed world knowledge can be used within state-of-the-art LLMs to induce decision trees without any training data. Zero-shot trees can even surpass data-driven trees on some small-sized tabular datasets, while remaining intrinsically interpretable and privacy-preserving. However, it bears pointing out that their conclusions are so far based on small-sized tabular classification datasets and do not necessarily extend to other settings. On a more positive, exciting front, different probabilistic classifiers like logistic regression could also potentially be generated following the general template and approach laid out here.