
Musing 82: WALL-E: World Alignment by Rule Learning Improves World Model-based LLM Agents
Interesting contribution out of Australian AI Institute, Tencent and UMD College Park

Today’s paper: WALL-E: World Alignment by Rule Learning Improves World Model-based LLM Agents. Zhou et al. 9 Oct. 2024. https://arxiv.org/pdf/2410.07484
Large language models (LLMs) have demonstrated success in handling complex reasoning, generation, and planning tasks, but they are not yet reliable enough to serve as agents in specific open-world environments, such as games, VR/AR systems, medical care, education, and autonomous driving. A key issue contributing to these failures is the gap between the commonsense reasoning with prior knowledge embedded in pretrained LLMs and the specific, hard-coded dynamics of these environments. This discrepancy results in incorrect predictions of future states, hallucinations, or violations of fundamental laws during the decision-making process of LLM agents.
While significant attention has been given to aligning LLMs with human preferences in post-training, "world alignment" with environmental dynamics has been insufficiently explored in the development of LLM agents. Additionally, many existing LLM agents are model-free, meaning their actions are executed directly in real environments without being validated or optimized in advance using a world model or simulator, leading to safety concerns and suboptimal performance.
Today’s paper describes a system called WALL-E (World Alignment by Rule Learning) that seeks to align LLMs with the specific dynamics of their deployed environments. It combines LLM-based reasoning with newly learned rules from real-world interactions to create a more reliable world model. This world model can then be used to predict the outcomes of actions, making "LLM" agents better suited for dynamic, open-world environments.

In Figure 1 above, WALL-E's rule-learning process is illustrated through the example of mining a diamond in the game Minecraft. Initially, the LLM agent makes a plan to mine resources, but fails due to a misalignment between its knowledge and the environment's actual rules (for instance, trying to mine iron ore with a wooden pickaxe, which is ineffective). By observing real-world outcomes and comparing them to predictions, WALL-E learns the necessary rule: a proper tool is required to mine certain materials. Once this rule is incorporated, the LLM agent adjusts its actions—ultimately using the correct tool (an iron pickaxe) to successfully mine the diamond. This process highlights how rule learning allows WALL-E to bridge the gap between the LLM's general knowledge and the environment’s specific dynamics, leading to successful task completion.
Figure 2 below provides a high-level architectural overview and how WALL-E operates in the context of model-predictive control (MPC) to improve the alignment between the LLM's internal world model and the real environment. It shows how WALL-E compares predicted trajectories generated by the LLM's world model with real trajectories observed in the environment. When discrepancies (like failure in mining due to using the wrong tool) occur, WALL-E uses rule learning to update its world model. This new knowledge is then applied to improve future action planning through MPC.

The rule-learning process in WALL-E, as depicted in Figure 3 of the paper below, is a central contribution of the work. It is easier to understand by revisiting the example in Figure 1. First, the process compares the predicted trajectories from the LLM-based world model with the actual, real-world trajectories observed when the agent takes actions. Misalignments between these two—such as predicting success but encountering failure—are identified. For example, if the LLM predicts that mining a diamond with a stone pickaxe will succeed but the real environment shows that it fails, this triggers the learning process.
Once a misalignment is detected (Step 2 in the figure below), the LLM is prompted to infer new rules from the real trajectory. These rules are intended to capture the specific environmental dynamics that the LLM initially failed to consider. For example, the rule "using a stone pickaxe to mine diamonds will fail" would be learned based on the real-world experience of failure when this action is attempted.
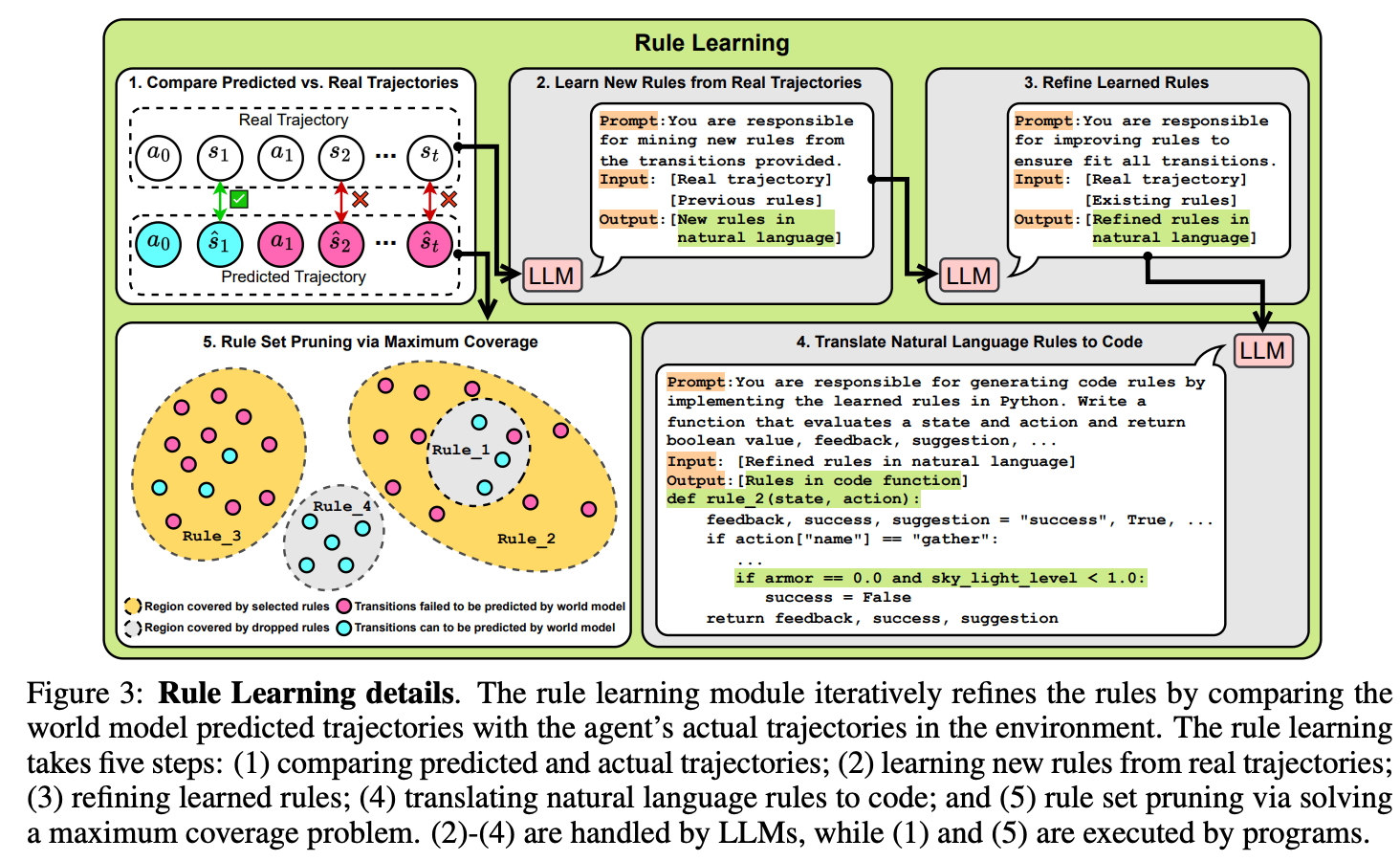
Third, after learning new rules, the LLM refines them by further analyzing the real trajectories. This is meant to help the rules generalize. For instance, the rule might be refined to specify that certain types of tools are required for certain materials, ensuring broader application of the rule.
Fourth, once the LLM has formulated the rules in natural language, the next step is to translate these rules into executable code. This code allows the LLM agent to implement the rules programmatically during future actions. For example, the rule might be codified as a function that checks whether the tool being used is appropriate for the material being mined.
Finally, to avoid excessive or redundant rules, WALL-E employs a pruning process. It selects the minimal set of rules that maximally covers the previously failed transitions (i.e., instances where the LLM's predictions did not align with the real-world outcome). This optimization is designed to yield a rule set that is both efficient and effective, covering only the core rules that correct the LLM's misalignments. For this, the authors use a relatively simple greedy algorithm that is also provided in the appendix of the preprint.
Now, on to experiments. The authors evaluate WALL-E on open-world environments using the Minecraft and ALFWorld benchmarks. The authors employ the standard evaluation pipeline provided by MineDojo’s TechTree tasks. These tasks can be categorized into six levels of increasing difficulty: Wood, Stone, Iron, Gold, Diamond, and Redstone. ALFWorld is a virtual environment designed as a text-based simulation where agents perform tasks by interacting with a simulated household environment, and includes six distinct task types, each requiring the agent to accomplish a high-level objective, such as placing a cooled lettuce on a countertop.
In conducting a detailed comparison of WALL-E and existing baseline methods in Table 1 and 2 below (for Minecraft), the authors demonstrate its superior performance in terms of success rate, planning efficiency, and token cost consumed by LLMs across diverse tasks. According to Table 1, WALL-E outperforms other baselines by an impressive margin of 15–30%. While the integration of the LLM world model leads to additional token costs compared to model-free methods, the authors argue that WALL-E demonstrates remarkably high sample efficiency, which is sufficient to offset the additional consumption caused by the world modeling. Specifically, the method requires 8–20 fewer replanning rounds than other baselines, resulting in overall token usage that is only 60–80% of that observed in other methods (Table 2). The authors also point out that the advantage of WALL-E becomes more apparent in harder environments.

Table 3 similarly reports performance on ALFWorld. Performance is again impressive, with WALL-E outperforming other rival models/baselines.

Finally, the authors also conduct an ablation study wherein they assess the significance of different components in WALL-E. The study specifically involved removing the learned rules and the world model separately to evaluate their impact on WALL-E's overall performance. Based on the results in Table 4 below, several conclusions were drawn:
(1) Whether the learned rules are applied to the agent or the world model, their inclusion significantly boosts performance, with the success rate improving by approximately 20% to 30%. This highlights the role that rule learning plays in WALL-E's effectiveness.
(2) When the learned rules are incorporated into the world model, they lead to nearly a 30% increase in success rate, whereas applying the rules within the agent results in around a 20% improvement. This difference may be due to the strong connection between the learned rules and the state information.
(3) Model-predictive control (MPC) using a world model without applying any rules does not significantly improve WALL-E's performance in terms of success rate or the number of replanning rounds.

In closing, I thought this was an interesting paper that shows that LLMs can effectively serve as world models for agents, but that in order to do so, they need to be aligned with environment dynamics through rule learning. The authors’ neuro-symbolic approach bridges the gap between LLMs’ prior knowledge and specific environments without gradient updates. Most importantly, the method seems to be efficient: the rule learning converges swiftly by the fourth iteration in most cases, outperforming buffered trajectory methods in both efficiency and effectiveness. These results suggest that minimal additional rules suffice to align LLM predictions with environment dynamics, opening the door a little wider for deploying model-based agents in complex environments.