
Musing 85: Improve Vision Language Model Chain-of-thought Reasoning
Interesting paper out of Apple and CMU

Today’s paper: Improve Vision Language Model Chain-of-thought Reasoning. Zhang et al. 21 Oct. 2024. https://arxiv.org/pdf/2410.16198
Chain-of-thought (CoT) reasoning has proven to be a tried-and-tested technique for buttressing the reliability of Vision-Language Models (VLMs). As VLMs are increasingly applied to more complex tasks, the ability to reason through these problems becomes all the more important. However, current training methods often depend on datasets that emphasize short answers with limited rationale, which limits the models' capacity to generalize to more comprehensive tasks. To address these challenges, today’s paper introduces distilled CoT data, along with supervised finetuning (SFT) and reinforcement learning (RL) strategies, to improve the reasoning capabilities of VLMs.
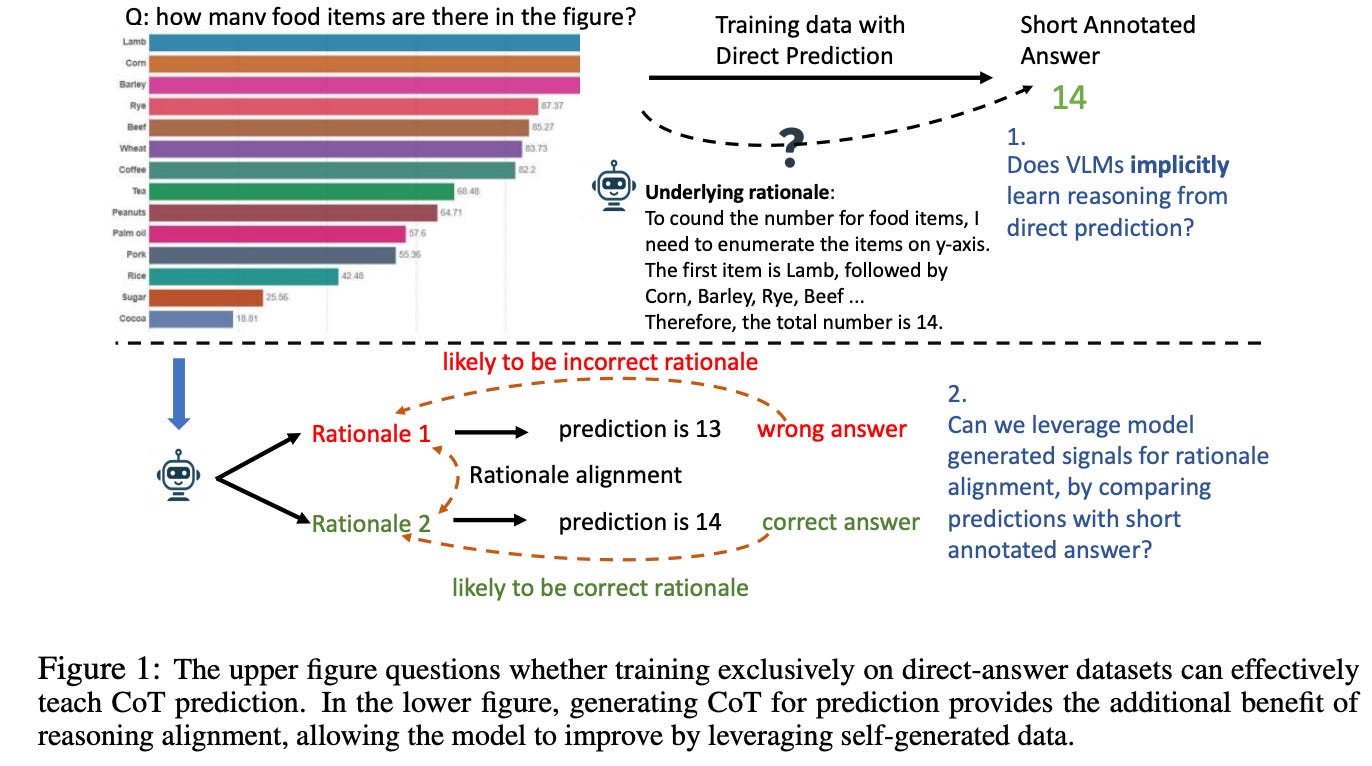
For example, when asked to determine the number of food items in a bar graph (as shown in Fig. 1), a human would typically count each bar before arriving at the total. However, writing out this process is more cumbersome than simply stating the answer, such as “14.” As a result, the annotated training data largely consists of short answers with minimal reasoning explanations. This leads to a key question: Does training on direct predictions inherently teach the model to perform chain-of-thought reasoning? Findings from this study show that after training on 26,000 direct predictions from the ChartQA dataset, direct prediction accuracy improved by 2.9 points (from 70.2 to 73.1), while CoT prediction accuracy only increased by 0.6 points (from 71.2 to 71.8). CoT reasoning underperformed in comparison to direct predictions, highlighting the limitations of current training approaches in enhancing CoT reasoning.
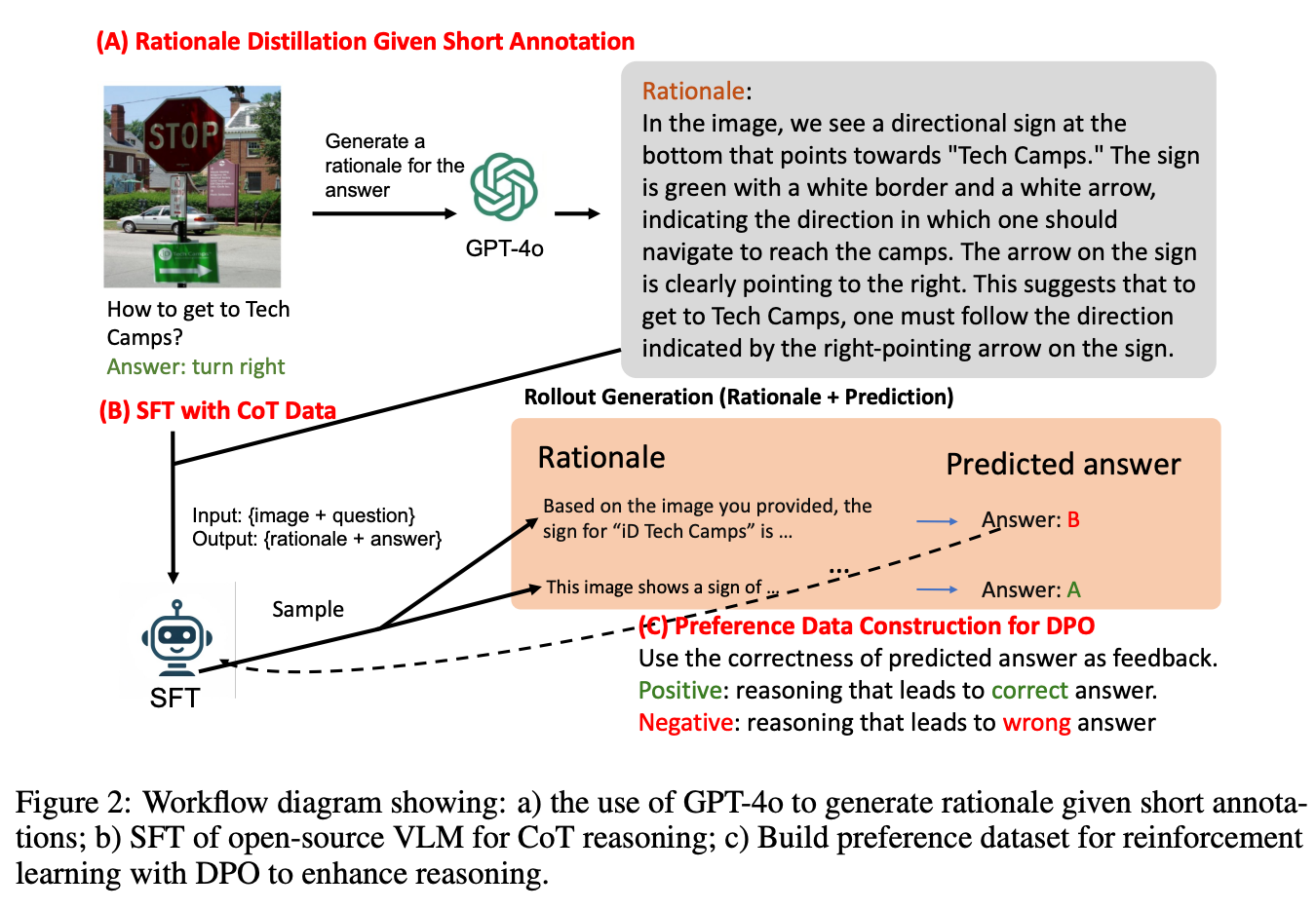
In Figure 2 below, the authors illustrate their workflow for improving VLMs’ reasoning, comprising three main stages:
CoT Data Distillation: This part shows how GPT-4o is used to generate reasoning rationales from datasets with short annotations. The idea is to take simple answers and augment them with logical reasoning, which is then used to train the model. This process enriches the training data with detailed reasoning steps that are often missing in standard datasets.
Supervised Fine-Tuning (SFT): The next step in the workflow involves fine-tuning an open-source VLM using the newly generated CoT data. This allows the model to improve its ability to reason through visual and language-based tasks.
Reinforcement Learning with Direct Preference Optimization (DPO): In the final stage, preference data is constructed using both correct and incorrect reasoning paths generated by the model. These preference pairs are then used in reinforcement learning to further enhance the model's reasoning abilities. Correct reasoning paths receive positive reinforcement, while incorrect ones are penalized, helping the model align its reasoning with correct outcomes.
To mitigate the limited availability of high-quality CoT data, the authors leverage VQA datasets with short annotations and augment them with rationales generated by the GPT-4o model. They collect 193k visual CoT instances to create the SHAREGPT-4O-REASONING dataset, which they say that they plan to release for public use. Figure 4 demonstrates examples of distilled reasoning across various types of tasks, such as:
Real-World Knowledge (e.g., identifying the use of horses in an image).
Chart Understanding (e.g., interpreting bar graphs to determine values or comparisons).
Document Information Localization (e.g., identifying specific information from industrial or educational documents).
Math and Science (e.g., performing arithmetic reasoning based on images of objects or scientific charts).

Next, Figure 5 below presents the data composition and model training process for the Supervised Fine-Tuning (SFT) experiments. The upper part of Figure 5 shows the data sources used for the SFT experiments. These data sources include:
CoT Data: Distilled from GPT-4o, containing 193k instances.
Direct Answer Data: Also containing 193k instances of short, direct answers.
Additional Math CoT Data: 16k examples from the G-LLaVA dataset, specifically related to math reasoning tasks.
Format-Aligned Data: A small set of format-aligned examples (450 CoT samples and 450 direct samples) from various datasets to help the model learn to handle both direct and CoT prompts.

The lower part of the figure outlines how the data is composed during the model training process. Each of the four experimental configurations shown allows the researchers to test different hypotheses about how direct and CoT data influence the model’s performance in both direct prediction and reasoning tasks.
Does the new dataset work as expected to improve performance? Table 5 below compares the performance of the SFT model developed by the authors (referred to as LLaVA-Reasoner-SFT) with two other models: GPT-4o and Cambrian-7B.
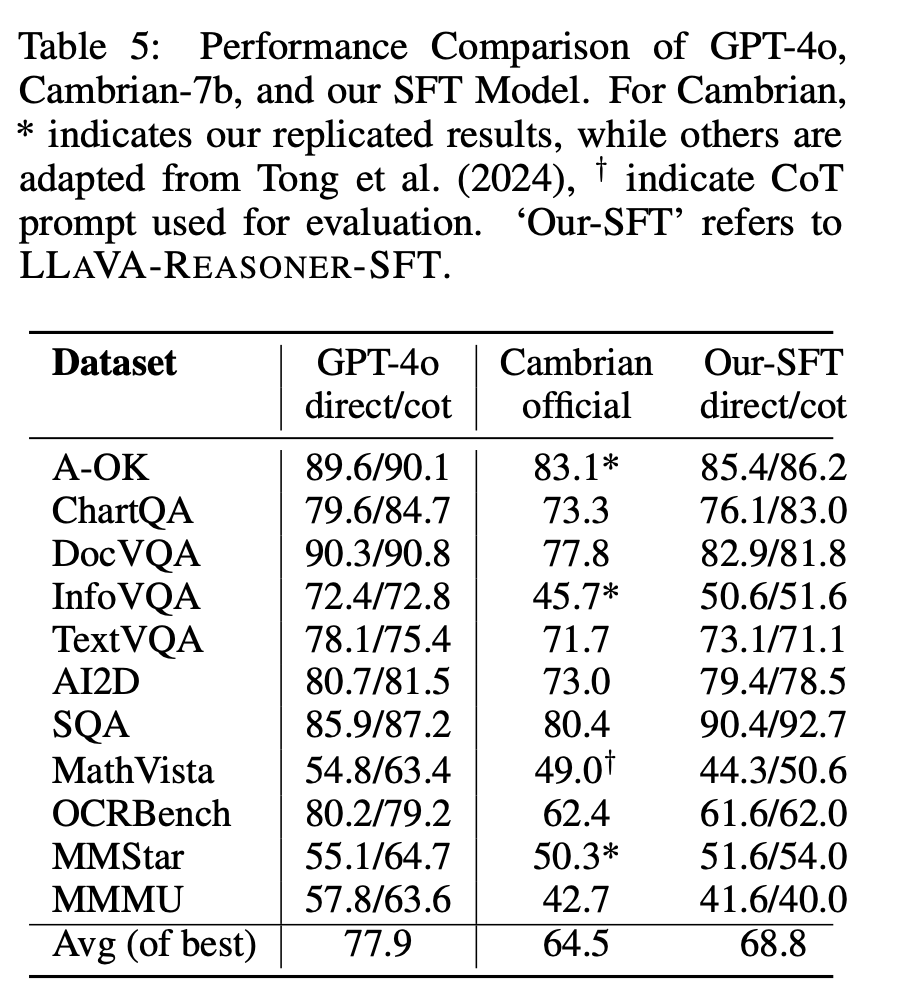
The table shows that fine-tuning process using CoT data leads to notable improvements in CoT prediction accuracy, as seen in tasks like ChartQA, AI2D, and SQA. This validates the authors' approach of distilling CoT data from GPT-4o and using it to enhance the model's reasoning capabilities. More impressive is the significant gains in tasks that require step-by-step reasoning (like MathVista and ChartQA) which clearly demonstrate that CoT reasoning, as distilled and fine-tuned in the authors’ approach, is effective.
Many other results are presented in the paper. For instance, the authors use the reinforcement learning with Direct Preference Optimization (DPO) to further refine the reasoning abilities of their model, showing that the DPO-optimized model not only improves CoT reasoning but also performs better in out-of-domain tasks. This suggests that training the model to learn from correct and incorrect reasoning paths allows it to generalize beyond the datasets it was trained on. The model’s ability to provide more accurate and interpretable rationales is demonstrated across various VQA and mathematical reasoning datasets, especially for the multi-stage training approach combining SFT and RL.
In summary, the authors collect a CoT reasoning dataset SHAREGPT-4O-REASONING and demonstrate that fine-tuning on this dataset can significantly improve performance across a broad range of VQA tasks. The authors further improve these models using reinforcement learning with direct preference optimization, which strengthens their ability to reason and generalize to direct answer prediction tasks. Overall, this paper marks a good advance in multimodal VLM reasoning.