
Musing 86: Demystifying Large Language Models for Medicine: A Primer
Multi-institutional primer from the likes of National Library of Medicine (NLM), UIUC and Yale, among several others

Today’s paper: Demystifying Large Language Models for Medicine: A Primer. Jin et al. Oct. 25, 2024. https://arxiv.org/pdf/2410.18856
Despite the accelerated progress of Large Language Models (LLMs) in patient care, clinical practice, biomedical and health sciences research, as well as education, there is a noticeable lack of practical, actionable guidelines for their application from bench to bedside and beyond. A lot of current use of LLMs, such as ad-hoc prompting with ChatGPT, is far from sufficient in medical tasks. This gap can lead to both underutilization and misapplication of these technologies, potentially affecting patient outcomes.
Today’s paper, which is very accessible but also very basic, aims to close this gap by providing a detailed, structured framework to guide the utilization and integration of LLMs into medical workflows. An illustration of their goals is provided below:
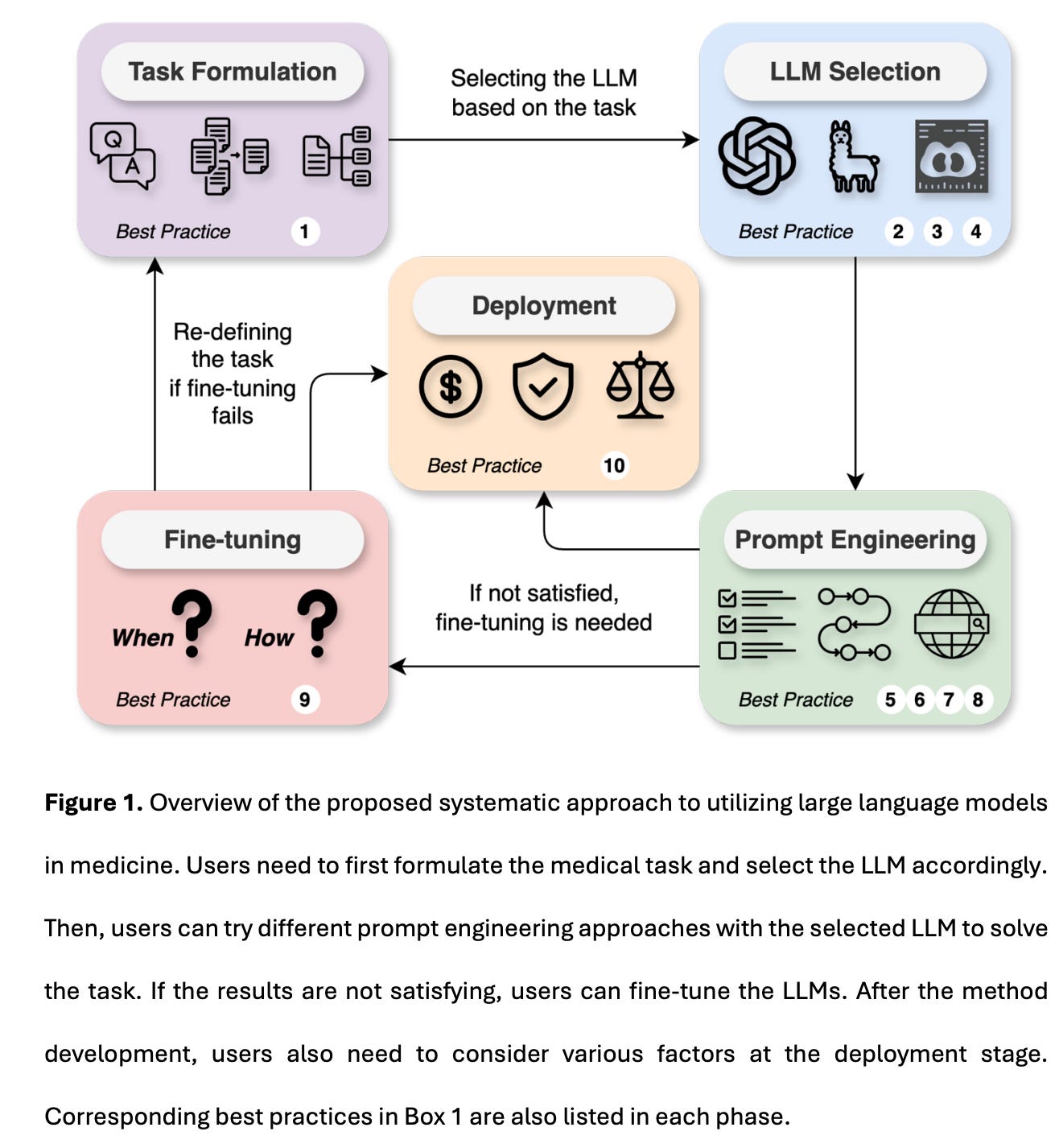
Let’s begin by diving into some of the best practices noted in the caption of the figure below. The authors enumerate the following, many of which seem obvious and self-explanatory but are still useful to list explicitly, almost as a checklist:
Organize your task into one of the five categories: (1) knowledge and reasoning, (2) summarization, (3) translation, (4) structurization, and (5) multi-modal data analysis. Collect up to 100 test cases for evaluation with task-specific metrics. (Figure 2 below).
Ensure that the LLM usage is compliant to Health Insurance Portability and Accountability Act (HIPAA) if working with sensitive data.
Choose an LLM that can process the data modality and has sufficient context length (length of the input prompt) used in the task. (Figure 3)
Select LLMs based on task-specific performance evaluated by experts in the literature. Scores on medical examinations can be used for the initial screening of LLMs (Figure 3)
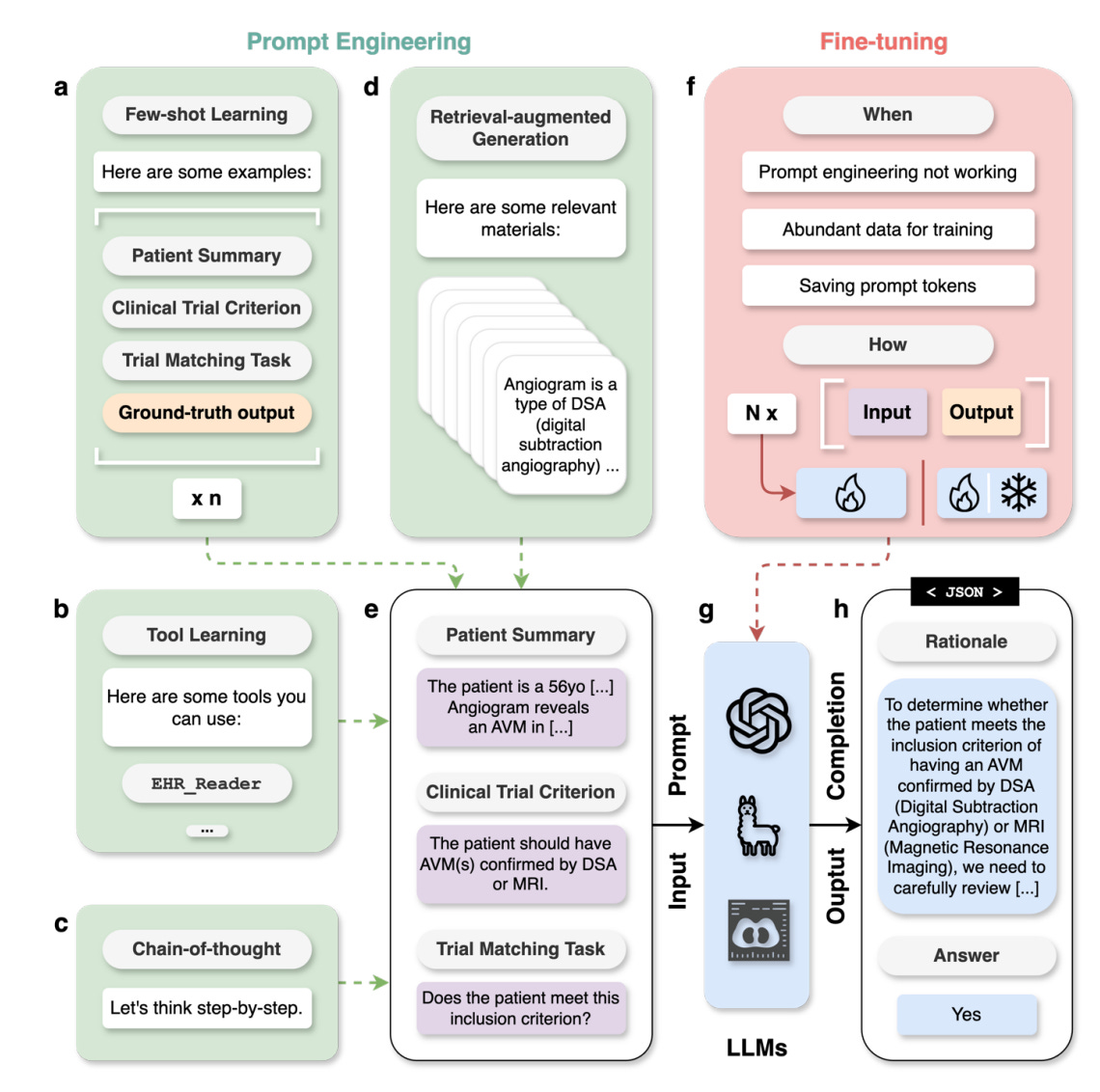
Use one to five representative and diverse examples in few-shot learning to better specify the response style and handle edge cases.
Always ask LLMs to “think-step-by-step” and generate the rationale before the answer for better explainability and improved performance.
Use retrieval-augmented generation (RAG) or tool learning if knowledge or domain utilities are needed and to make evidence-based and up-to-date generation.
Use a temperature of 0 and JSON formatting to generate reproducible and structured outputs that can be easily parsed.
Consider fine-tuning when prompt engineering fails to reach the desired performance, the working prompt is too costly, or abundant training data is readily available.
Safeguard against potential risks by monitoring fairness, equity, bias, and cost when deploying LLMs in the biomedical domain.
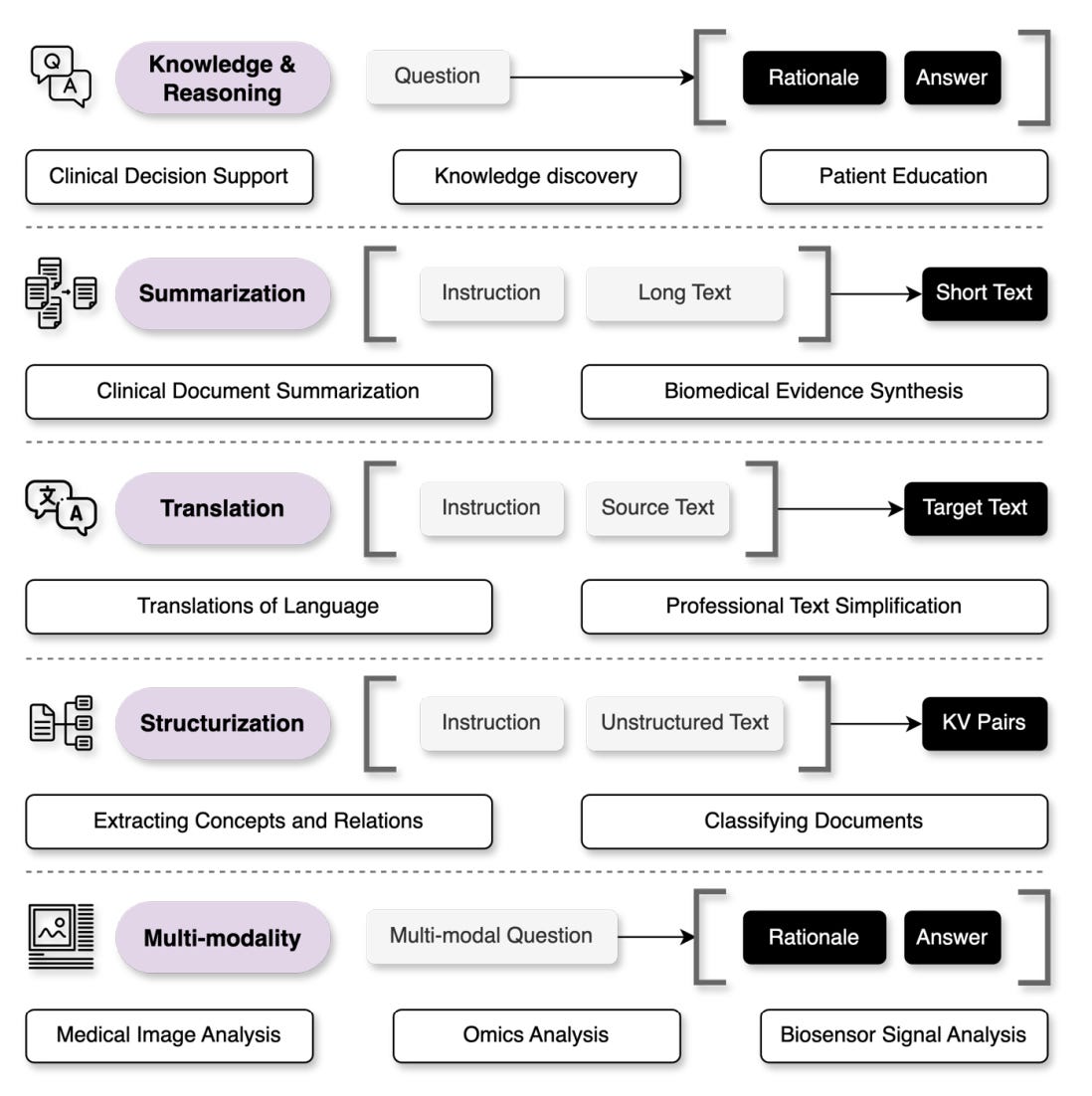
Among the best practices, I thought that the concept of ‘structurization’ mentioned in the first best practice is interesting since I really haven’t heard that term before, even though it’s not hard to imagine what it means. However, it’s still useful to think about what the authors mean in the specific context of medical applications. The authors state that LLMs can be leveraged to convert free-text input into structured outputs such as a list of key-value pairs. Medical structurization problems include classifying an input text into controlled vocabularies like the diagnosis-related groups and extracting biomedical concepts as well as their relationships (e.g., variant-causing-disease) from unstructured text. Structurization instances include task instruction (input), source text (input), and a list of extracted concepts and relations in structured forms (output). The evaluations are made to match the output with the reference answers. As such, the performance is often typically measured by precision, recall, and F1 score (and other such metrics).
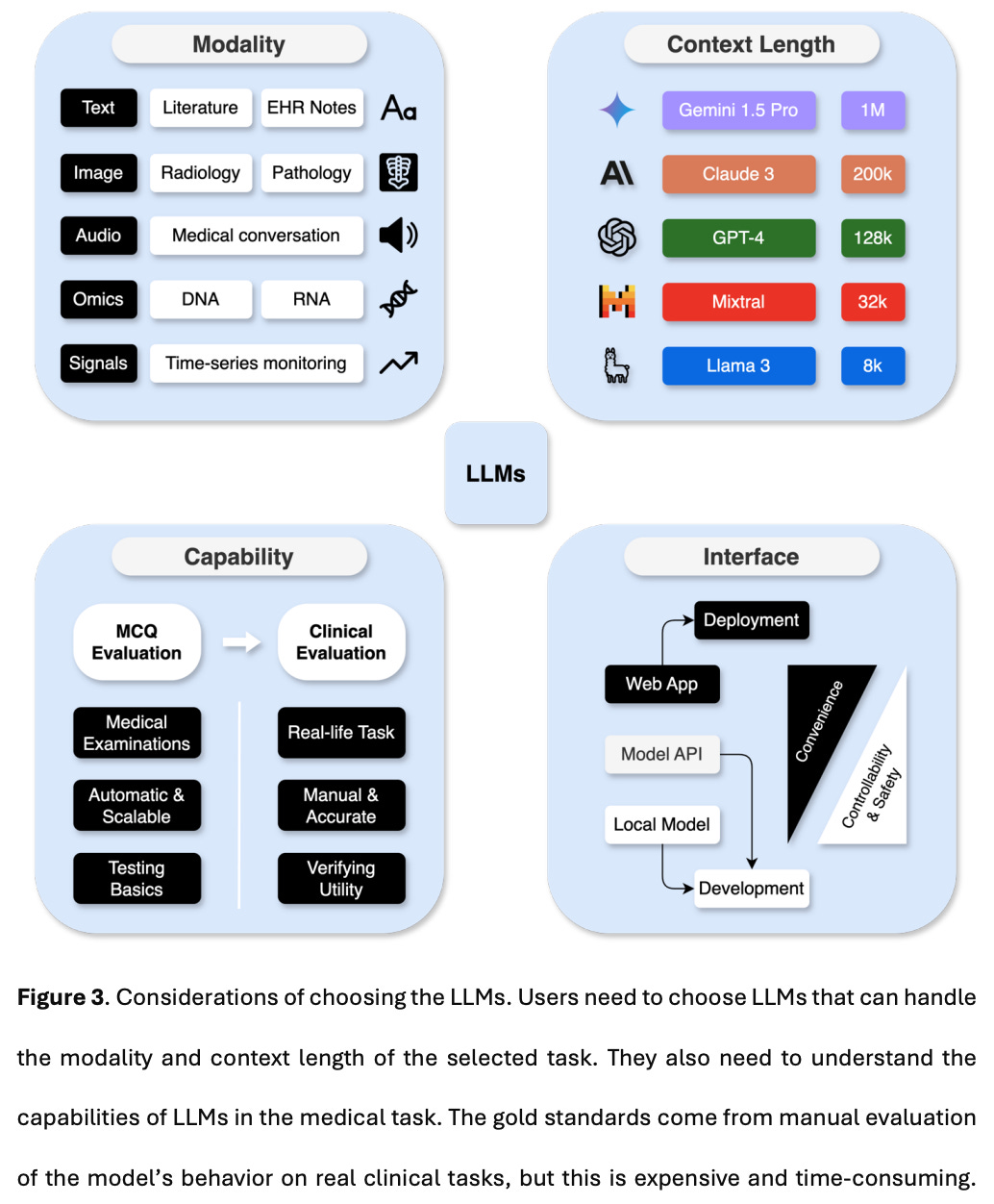
Also interesting is the authors’ exposition on how to evaluate the medical capabilities of LLMs: multi-choice question (MCQ) evaluation and clinical evaluation. Medical examination and questionanswering tasks, such as MedQA-USMLE, PubMedQA, MedMCQA, have been commonly used to evaluate the knowledge and reasoning capabilities of LLMs. These benchmarks should only be used to filter out models that cannot meet basic performance standards. However, higher scores on these datasets do not necessarily translate to better clinical utility, as there are no choices provided in real-life applications. After a model passes initial screening via MCQ evaluations, it must be further assessed for clinical utility.
The authors also briefly discuss prompt engineering, which is the process of designing and optimizing prompts to effectively guide LLMs in generating accurate and coherent responses. Prompts can vary from one simple instruction to many documents retrieved by a search system, allowing users to elicit a variety of behaviors without the need to modify the parameters of LLM. In general, more complex tasks typically require more sophisticated prompts. Figure 4 below shows a concrete task example of clinical trial matching, where a simple prompt that merely describes the patient and lists the clinical trial criteria (shown in Fig. 4e) might not work well. As such, prompt engineering and fine-tuning methods should be used.
In closing, I thought the paper was a good read for folks looking to gain an introduction to LLMs, terminologies like prompt engineering, measurement science of LLMs pertaining to medical applications, and in general, an accessible look into what LLMs might be able to achieve in medicine, and also what some of the pitfalls are. However, the article is not useful to anyone looking to gain more advanced insights. It serves a valuable role in the literature (it bills itself, ultimately, as only a primer after all) and it’s a good review. But I had hoped for a more in-depth and extensive treatment, written at an accessible level.