


Musing 94: Boundless Socratic Learning with Language Games
Paper out of Google DeepMind

Today’s paper: Boundless Socratic Learning with Language Games. Tom Schaul. 25 Nov. 2024. https://arxiv.org/pdf/2411.16905
The abstract of today’s paper starts out by making a bold, but reasonable claim: An agent trained within a closed system can master any desired capability, as long as the following three conditions hold: (a) it receives sufficiently informative and aligned feedback, (b) its coverage of experience/data is broad enough, and (c) it has sufficient capacity and resource. The author aims to justify these conditions, and consider what limitations arise from (a) and (b) in closed systems, when assuming that (c) is not a bottleneck. Considering the special case of agents with matching input and output spaces (namely, language), they argue that such pure recursive self-improvement, dubbed ‘Socratic learning,’ can boost performance vastly beyond what is present in its initial data or knowledge, and is only limited by time, as well as gradual misalignment concerns. Last, they propose a constructive framework to implement it, based on the notion of language games.
Figure 1 below illustrates what the author means by a closed system. In this case, the system evolves over time, but it doesn’t have any inputs or outputs. Within the system is an entity with inputs and outputs, called agent, that also changes over time. External to the system is an observer whose purpose is to assess the performance of the agent. If performance keeps increasing, the author calls this system-observer pair an improvement process.
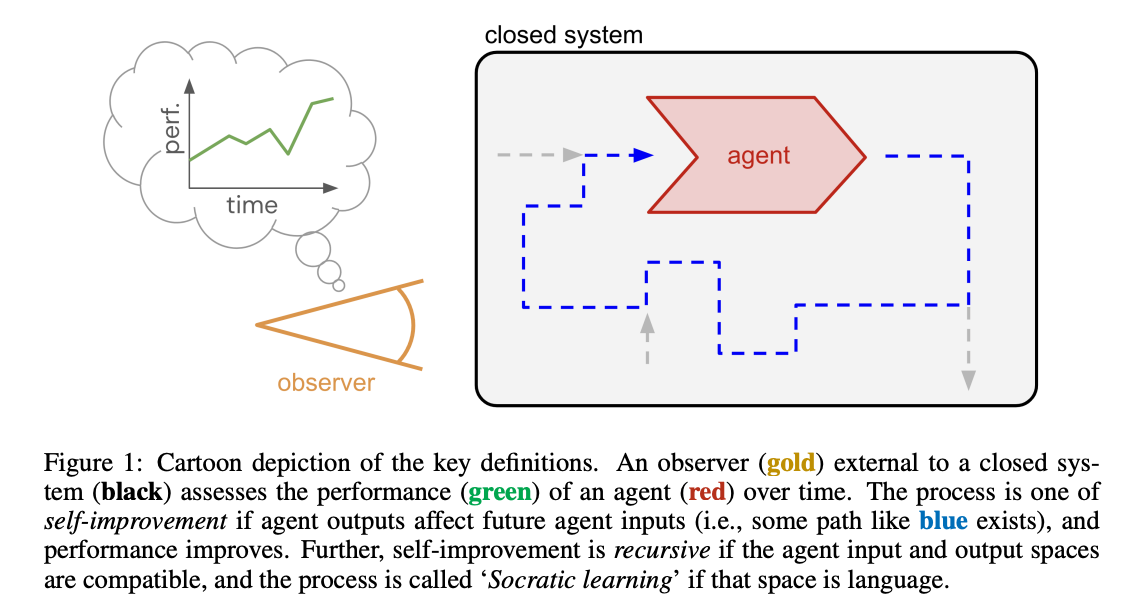
As the system is closed, the observer’s assessment cannot feed back into the system. Hence, the agent’s learning feedback must come from system-internal proxies such as losses, reward functions, preference data, or critics. The simplest type of performance metric is a scalar score that can be measured in finite time, that is, on (an aggregation of) episodic tasks. Mechanistically, the observer can measure performance in two ways, by passively observing the agent’s behaviour within the system (if all pertinent tasks occur naturally), or by copy-and-probe evaluations where it confronts a cloned copy of the agent with interactive tasks of its choosing.
This is an elegant way to frame the problem, which the paper gets at very directly and clearly. No fancy language or verbosity, which readers like me always appreciate. The author further states that, without loss of generality, the elements within an agent can be partitioned into three types: Fixed elements are unaffected by learning, such as its substrate or unmodifiable code. Transient elements do not carry over between episodes, or across to evaluation (e.g., activations, the state of a random number generator). And finally learned elements (e.g., weights, parameters, knowledge) change based on a feedback signal, and their evolution maps to performance differences. The author distinguishes improvement processes by their implied lifetime; some are open-ended and keep improving without limit, while others converge onto their asymptotic performance after some finite time.

Self-improvement is an improvement process as defined above, but with the additional criterion that the agent’s own outputs (actions) influence its future learning. In other words, systems in which agents shape (some of) their own experience stream, potentially enabling unbounded improvement in a closed system. This setting may look familiar to readers from the reinforcement learning community. Feedback is what gives direction to learning; without it, the process is merely one of self-modification. In a closed system where the true purpose resides in the external observer, but can not be accessed directly, feedback can only come from a proxy. This creates the fundamental challenge for system-internal feedback is be aligned with the observer, and remain aligned throughout the process. We’ve already seen quite a few papers that have dealt with this alignment challenge.
Next, the author considers the concept of coverage. By definition, a self-improving agent determines the distribution of data it learns from. To prevent issues like collapse, drift, exploitation or overfitting, it needs to preserve sufficient coverage of the data distribution everywhere the observer cares about. In most interesting cases, where performance includes a notion of generalisation, that target distribution is not given (the test tasks are withheld), so the system needs to be set up to intrinsically seek coverage, a sub-process classically called exploration. Note that aligned feedback is not enough for this on its own: even if a preferred behaviour is never ranked lower than a dis-preferred one, that is not tantamount to guaranteeing that the agent will find the preferred behaviour.
Lastly, concerning scale, research in RL has already produced a lot of detailed knowledge about how to train agents, which algorithms work in which circumstances, an abundance of neat tricks that address practical concerns, as well as theoretical results that characterize convergence, learning dynamics, rates of progress, and so on.
The specific type of self-improvement process considered in this paper is recursive self-improvement, where the agent’s inputs and outputs are compatible (i.e., live in the same space), and outputs become future inputs. An excellent example is language. A vast range of human behaviours are mediated by, and well-expressed, in language, especially in cognitive domains (which are definitionally part of Artificial Super Intelligence). Language has the neat property of being a soup of abstractions, encoding many levels of the conceptual hierarchy in a shared space. A related feature of language is its extendability, i.e., it is possible to develop new languages within an existing one, such as formal mathematics or programming languages that were first developed within natural language.
The author uses ‘Socratic learning’ to refer to a recursive self-improvement process that operates in language space. The name is alluding to Socrates’ approach of finding or refining knowledge through questioning dialogue and repeated language interactions, but, notably, without going out to collect observations in the real world—mirroring the emphasis on the system being closed. Among the three necessary conditions for self-improvement that were described earlier, two of them, coverage and feedback apply to Socratic learning in principle, and remain irreducible. To make their implications as clear as possible, the author ignores the third. They motivate this simplification by taking the long view: if compute and memory keep growing exponentially, scale constraints are but a temporary obstacle. If not, considering a resource-constrained scenario for Socratic learning (akin to studying bounded rationality) may still produce valid high-level insights.
In Section 5, the author boldly titles one of the sections “Language games are all you need…” Language games, defined in the Wittgensteinian way, address the two primary needs of Socratic learning; namely, they provide a scalable mechanism for unbounded interactive data generation and self-play, while automatically providing an accompanying feedback signal (the score). In fact, they are the logical consequence of the coverage and feedback conditions, almost tautologically so: there is no form of interactive data generation with tractable feedback that is not a language game.
However, rather than argue for one ‘universal’ language game that could possibly lead to something like ASI, the author argues that using many narrow but well-defined language games instead of a single universal one resolves a key dilemma: For each narrow game, a reliable score function (or critic) can be designed, whereas getting the single universal one right is more elusive. From that lens, the full process of Socratic learning is then a meta-game, which schedules the language games that the agent plays and learns from. The author posits that in principle, this idea is sufficient to address the issue of coverage. Concretely, if a proxy of the observer’s distribution of interest is available (e.g., a validation set of tasks), that can be used to drive exploration in the meta-game.
There are some other interesting and provocative ideas in this position piece, but in closing the musing, the author set out to investigate how far recursive self-improvement in a closed system can take us on the path to AGI, and concludes the piece on an optimistic note. In principle, the potential of Socratic learning is high, and the challenges that were identified (feedback and coverage) are well known. The framework of language games provides a constructive starting point that addresses both, and helps clarify how a practical research agenda could look like. An understudied dimension is the breadth and richness of the many such language games. The author believes that a great place to start is with processes capable of open-ended game generation. And not without seeing the irony, they propose all these ideas to scrutiny within an academic setting instead of resorting to self-talk in a closed system.
My final thoughts on the paper are that, while it does not necessarily contain ‘original’ research by way of theory or experiments (and the author is honest about this in saying right upfront that this is a position paper), the ideas are laid out elegantly and, at risk of over-using the word, provocatively. It will be interesting to see whether some of these ideas come to fruition empirically. Many details still need to be worked out, but the concept of achieving super-intelligence through Socratic learning using language-games is, in all honesty, mind-bending.